SQL Server中UPDATE和DELETE语句结合INNER/LEFT/RIGHT/FULL JOIN的用法
在SQL Server中,UPDATE和DELETE语句是可以结合INNER/LEFT/RIGHT/FULL JOIN来使用的。
我们首先在数据库中新建两张表:
[T_A]
CREATE TABLE [dbo].[T_A](
[ID] [int] NOT NULL,
[Name] [nvarchar](50) NULL,
[Age] [int] NULL,
CONSTRAINT [PK_T_A] PRIMARY KEY CLUSTERED
(
[ID] ASC
)WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, IGNORE_DUP_KEY = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON) ON [PRIMARY]
) ON [PRIMARY]
[T_B]
CREATE TABLE [dbo].[T_B](
[ID] [int] NOT NULL,
[Name] [nvarchar](50) NULL,
[Age] [int] NULL,
CONSTRAINT [PK_T_B] PRIMARY KEY CLUSTERED
(
[ID] ASC
)WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, IGNORE_DUP_KEY = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON) ON [PRIMARY]
) ON [PRIMARY]
UPDATE与INNER/LEFT/RIGHT/FULL JOIN
UPDATE结合INNER JOIN:
TRUNCATE TABLE [T_A];
TRUNCATE TABLE [T_B]; INSERT INTO [T_A]([ID],[Name],[Age])
VALUES
(1,N'Tome',10),
(2,N'Jack',20),
(3,N'Jim',30),
(4,N'Mike',40),
(5,N'Bob',50); INSERT INTO [T_B]([ID],[Name],[Age])
VALUES
(1,N'Tome',100),
(2,N'Jack',200),
(3,N'Jim',300); UPDATE [T_A]
SET
Age=[T_B].Age
FROM
[T_A]
INNER JOIN
[T_B]
ON [T_A].ID=[T_B].ID; SELECT * FROM [dbo].[T_A];
表[T_A]的结果如下所示:

其效果相当于通过下面INNER JOIN查询,先找出表[T_A]的数据记录,然后UPDATE这些找出的数据记录:
SELECT
[T_A].*,
[T_B].*
FROM
[T_A]
INNER JOIN
[T_B]
ON [T_A].ID=[T_B].ID;
注意如果表[T_A]中的某行数据与表[T_B]中多行数据匹配上,这种情况下,表[T_A]的该行数据也只会被UPDATE一次,不过用表[T_B]中的哪一行匹配数据去UPDATE表[T_A]是不确定的。
UPDATE结合LEFT JOIN:
TRUNCATE TABLE [T_A];
TRUNCATE TABLE [T_B]; INSERT INTO [T_A]([ID],[Name],[Age])
VALUES
(1,N'Tome',10),
(2,N'Jack',20),
(3,N'Jim',30),
(4,N'Mike',40),
(5,N'Bob',50); INSERT INTO [T_B]([ID],[Name],[Age])
VALUES
(1,N'Tome',100),
(2,N'Jack',200),
(3,N'Jim',300); UPDATE [T_A]
SET
Age=[T_B].Age
FROM
[T_A]
LEFT JOIN
[T_B]
ON [T_A].ID=[T_B].ID; SELECT * FROM [dbo].[T_A];
表[T_A]的结果如下所示:
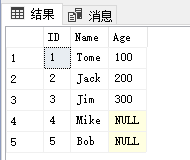
其效果相当于通过下面LEFT JOIN查询,先找出表[T_A]的数据记录,然后UPDATE这些找出的数据记录:
SELECT
[T_A].*,
[T_B].*
FROM
[T_A]
LEFT JOIN
[T_B]
ON [T_A].ID=[T_B].ID;
UPDATE结合RIGHT JOIN:
TRUNCATE TABLE [T_A];
TRUNCATE TABLE [T_B]; INSERT INTO [T_A]([ID],[Name],[Age])
VALUES
(1,N'Tome',10),
(2,N'Jack',20),
(3,N'Jim',30),
(4,N'Mike',40),
(5,N'Bob',50); INSERT INTO [T_B]([ID],[Name],[Age])
VALUES
(1,N'Tome',100),
(2,N'Jack',200),
(3,N'Jim',300),
(4,N'Mike',400),
(5,N'Bob',500),
(6,N'Clark',600),
(7,N'Sam',700); UPDATE [T_A]
SET
Age=[T_B].Age
FROM
[T_A]
RIGHT JOIN
[T_B]
ON [T_A].ID=[T_B].ID; SELECT * FROM [dbo].[T_A];
表[T_A]的结果如下所示:

其效果相当于通过下面RIGHT JOIN查询,先找出表[T_A]的数据记录,然后UPDATE这些找出的数据记录:
SELECT
[T_A].*,
[T_B].*
FROM
[T_A]
RIGHT JOIN
[T_B]
ON [T_A].ID=[T_B].ID;
UPDATE结合FULL JOIN:
TRUNCATE TABLE [T_A];
TRUNCATE TABLE [T_B]; INSERT INTO [T_A]([ID],[Name],[Age])
VALUES
(1,N'Tome',10),
(2,N'Jack',20),
(3,N'Jim',30),
(4,N'Mike',40),
(5,N'Bob',50); INSERT INTO [T_B]([ID],[Name],[Age])
VALUES
(1,N'Tome',100),
(2,N'Jack',200),
(3,N'Jim',300); UPDATE [T_A]
SET
Age=[T_B].Age
FROM
[T_A]
FULL JOIN
[T_B]
ON [T_A].ID=[T_B].ID; SELECT * FROM [dbo].[T_A];
表[T_A]的结果如下所示:
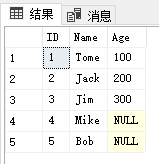
其效果相当于通过下面FULL JOIN查询,先找出表[T_A]的数据记录,然后UPDATE这些找出的数据记录:
SELECT
[T_A].*,
[T_B].*
FROM
[T_A]
FULL JOIN
[T_B]
ON [T_A].ID=[T_B].ID;
DELETE与INNER/LEFT/RIGHT/FULL JOIN
DELETE结合INNER JOIN:
TRUNCATE TABLE [T_A];
TRUNCATE TABLE [T_B]; INSERT INTO [T_A]([ID],[Name],[Age])
VALUES
(1,N'Tome',10),
(2,N'Jack',20),
(3,N'Jim',30),
(4,N'Mike',40),
(5,N'Bob',50); INSERT INTO [T_B]([ID],[Name],[Age])
VALUES
(1,N'Tome',100),
(2,N'Jack',200),
(3,N'Jim',300); DELETE [T_A]
FROM
[T_A]
INNER JOIN
[T_B]
ON [T_A].ID=[T_B].ID; SELECT * FROM [dbo].[T_A];
表[T_A]的结果如下所示:
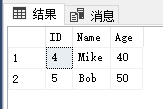
其效果相当于通过下面INNER JOIN查询,先找出表[T_A]的数据记录,然后DELETE这些找出的数据记录:
SELECT
[T_A].*
FROM
[T_A]
INNER JOIN
[T_B]
ON [T_A].ID=[T_B].ID;
DELETE结合LEFT JOIN:
TRUNCATE TABLE [T_A];
TRUNCATE TABLE [T_B]; INSERT INTO [T_A]([ID],[Name],[Age])
VALUES
(1,N'Tome',10),
(2,N'Jack',20),
(3,N'Jim',30),
(4,N'Mike',40),
(5,N'Bob',50); INSERT INTO [T_B]([ID],[Name],[Age])
VALUES
(1,N'Tome',100),
(2,N'Jack',200),
(3,N'Jim',300); DELETE [T_A]
FROM
[T_A]
LEFT JOIN
[T_B]
ON [T_A].ID=[T_B].ID; SELECT * FROM [dbo].[T_A];
表[T_A]的结果如下所示:
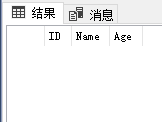
其效果相当于通过下面LEFT JOIN查询,先找出表[T_A]的数据记录,然后DELETE这些找出的数据记录:
SELECT
[T_A].*
FROM
[T_A]
LEFT JOIN
[T_B]
ON [T_A].ID=[T_B].ID;
DELETE结合RIGHT JOIN:
TRUNCATE TABLE [T_A];
TRUNCATE TABLE [T_B]; INSERT INTO [T_A]([ID],[Name],[Age])
VALUES
(1,N'Tome',10),
(2,N'Jack',20),
(3,N'Jim',30),
(4,N'Mike',40),
(5,N'Bob',50); INSERT INTO [T_B]([ID],[Name],[Age])
VALUES
(1,N'Tome',100),
(2,N'Jack',200),
(3,N'Jim',300),
(4,N'Mike',400),
(5,N'Bob',500),
(6,N'Clark',600),
(7,N'Sam',700); DELETE [T_A]
FROM
[T_A]
RIGHT JOIN
[T_B]
ON [T_A].ID=[T_B].ID; SELECT * FROM [dbo].[T_A];
表[T_A]的结果如下所示:

其效果相当于通过下面RIGHT JOIN查询,先找出表[T_A]的数据记录,然后DELETE这些找出的数据记录:
SELECT
[T_A].*
FROM
[T_A]
RIGHT JOIN
[T_B]
ON [T_A].ID=[T_B].ID;
DELETE结合FULL JOIN:
TRUNCATE TABLE [T_A];
TRUNCATE TABLE [T_B]; INSERT INTO [T_A]([ID],[Name],[Age])
VALUES
(1,N'Tome',10),
(2,N'Jack',20),
(3,N'Jim',30),
(4,N'Mike',40),
(5,N'Bob',50); INSERT INTO [T_B]([ID],[Name],[Age])
VALUES
(1,N'Tome',100),
(2,N'Jack',200),
(3,N'Jim',300); DELETE [T_A]
FROM
[T_A]
FULL JOIN
[T_B]
ON [T_A].ID=[T_B].ID; SELECT * FROM [dbo].[T_A];
表[T_A]的结果如下所示:
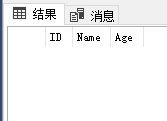
其效果相当于通过下面FULL JOIN查询,先找出表[T_A]的数据记录,然后DELETE这些找出的数据记录:
SELECT
[T_A].*
FROM
[T_A]
FULL JOIN
[T_B]
ON [T_A].ID=[T_B].ID;
JOIN语句使用子查询
其实我们还可以在UPDATE和DELETE语句使用JOIN时,对UPDATE和DELETE的表使用子查询,但是这种用法我个人不推荐,我们来看一个UPDATE的例子:
TRUNCATE TABLE [T_A];
TRUNCATE TABLE [T_B]; INSERT INTO [T_A]([ID],[Name],[Age])
VALUES
(1,N'Tome',10),
(2,N'Jack',20),
(3,N'Jim',30),
(4,N'Mike',40),
(5,N'Bob',50); INSERT INTO [T_B]([ID],[Name],[Age])
VALUES
(1,N'Tome',100),
(2,N'Jack',200),
(3,N'Jim',300); UPDATE [T_A]
SET
Age=[T_B].Age
FROM
(
SELECT
*
FROM [T_A]
WHERE
[T_A].ID<=2
) AS [T_A]
INNER JOIN
[T_B]
ON [T_A].ID=[T_B].ID; SELECT * FROM [dbo].[T_A];
表[T_A]的结果如下所示:
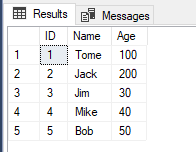
可以看到由于我们现在对表[T_A]做了子查询,用WHERE条件限制了其ID<=2,所以子查询只会返回表[T_A]的两条数据,因此最终表[T_A]只有两条数据得到了更新。
这个结果是符合我们预期的,但是其中有一个很重要的因素,就是UPDATE关键字后面的表名要和子查询的别名一致,我们对上面的UPDATE语句稍作修改,如下所示:
TRUNCATE TABLE [T_A];
TRUNCATE TABLE [T_B]; INSERT INTO [T_A]([ID],[Name],[Age])
VALUES
(1,N'Tome',10),
(2,N'Jack',20),
(3,N'Jim',30),
(4,N'Mike',40),
(5,N'Bob',50); INSERT INTO [T_B]([ID],[Name],[Age])
VALUES
(1,N'Tome',100),
(2,N'Jack',200),
(3,N'Jim',300); UPDATE [T_A]
SET
Age=[T_B].Age
FROM
(
SELECT
*
FROM [T_A]
WHERE
[T_A].ID<=2
) AS [T_A_1]
INNER JOIN
[T_B]
ON [T_A_1].ID=[T_B].ID; SELECT * FROM [dbo].[T_A];
现在我们将子查询的名字命名为了[T_A_1],但是我们UPDATE的表是[T_A],上面语句执行后,表[T_A]的结果如下所示:

我们可以看到表[T_A]的所有数据都被莫名其妙地更新了,我们来看看UPDATE语句的执行计划,如下所示:
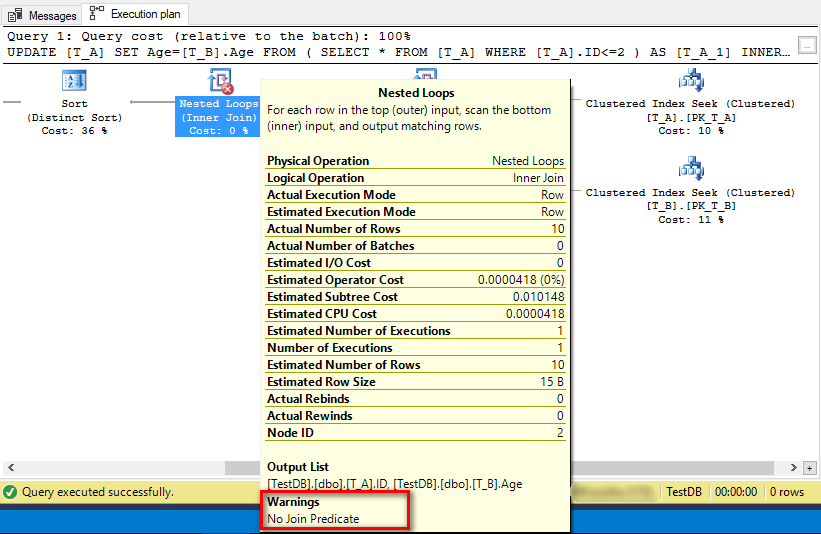
我们可以看到最关键的一个步骤,也就是表[T_A]和JOIN结果集之间的"Nested Loops"这个JOIN有个警告:"No Join Predicate",其含义就是说表[T_A]和JOIN结果集之间的JOIN是没有ON条件的,相当于CROSS JOIN,所以我们最后才看到表[T_A]的所有数据都被莫名其妙地更新了。这是因为现在UPDATE语句后面的表名[T_A]和子查询的命名[T_A_1]不一致,所以UPDATE语句现在不知道如何将[T_A_1]和[T_B]之间INNER JOIN后的结果集对应到UPDATE的表[T_A]中,所以就将表[T_A]的所有数据都更新了。
要解决这个问题其实也很简单,只要将UPDATE语句后面的表名改为子查询的名字[T_A_1],使得UPDATE语句后面的表名和子查询的名字一致就行了,如下所示:
TRUNCATE TABLE [T_A];
TRUNCATE TABLE [T_B]; INSERT INTO [T_A]([ID],[Name],[Age])
VALUES
(1,N'Tome',10),
(2,N'Jack',20),
(3,N'Jim',30),
(4,N'Mike',40),
(5,N'Bob',50); INSERT INTO [T_B]([ID],[Name],[Age])
VALUES
(1,N'Tome',100),
(2,N'Jack',200),
(3,N'Jim',300); UPDATE [T_A_1]
SET
Age=[T_B].Age
FROM
(
SELECT
*
FROM [T_A]
WHERE
[T_A].ID<=2
) AS [T_A_1]
INNER JOIN
[T_B]
ON [T_A_1].ID=[T_B].ID; SELECT * FROM [dbo].[T_A];
现在,表[T_A]的结果如下所示:
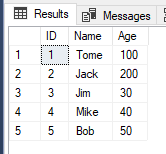
可以看到这次UPDATE语句正确地只更新了表[T_A]的两行数据,我们看看UPDATE语句的执行计划:

可以看到这次"Nested Loops"没有任何警告,正确地将表[T_A]和[T_B]进行了INNER JOIN,所以UPDATE语句只更新了表[T_A]的两行数据。这说明虽然我们在UPDATE语句后面写的是子查询的名字[T_A_1],但是UPDATE语句还是可以根据子查询[T_A_1]知道要更新的表实际上是[T_A],不得不说这一点SQL Server还是挺智能的。
但是鉴于在UPDATE和DELETE语句中使用JOIN时,再对UPDATE和DELETE的表使用子查询看起来比较怪,并且如上所示,用得不对会造成结果出错,所以我个人还是不推荐在UPDATE和DELETE语句中使用JOIN时,再对UPDATE和DELETE的表使用子查询,况且这种子查询实际上完全可以用其它方式来替代。
总结
举了这么多例子,其实我个人觉得UPDATE和DELETE语句与INNER JOIN结合使用才是最有用的,但是不管是什么JOIN,从上面的例子可以看出,其实都相当于是先用SELECT语句做表[T_A]的INNER/LEFT/RIGHT/FULL JOIN查询,然后UPDATE或DELETE表[T_A]中查询出的这些数据记录。
SQL Server中UPDATE和DELETE语句结合INNER/LEFT/RIGHT/FULL JOIN的用法的更多相关文章
- SQL Server 基本UPDATE和DELETE语句
1.UPDATA 基本UPDATE语法:(可以修改多行的列) 2.DELETE
- 【SQL Server学习笔记】Delete 语句、Output 子句、Merge语句
原文:[SQL Server学习笔记]Delete 语句.Output 子句.Merge语句 DELETE语句 --建表 select * into distribution from sys.obj ...
- SQL Server 中使用参数化Top语句
在T-Sql中,一般top数据不确定的情况下,都是拼sql,这样无论是效率还是可读性都不好.应该使用下面参数化Top方式:declare @TopCount int set @TopCount = 1 ...
- sql server中的while循环语句
语法格式: while 条件 begin ....... end declare @num begin update SDetail end
- SQL SERVER中查询某个表或某个索引是否存在
查询某个表是否存在: 在实际应用中可能需要删除某个表,在删除之前最好先判断一下此表是否存在,以防止返回错误信息.在SQL SERVER中可通过以下语句实现: IF OBJECT_ID(N'表名称', ...
- SQL server触发器中 update insert delete 分别给写个例子被。
SQL server触发器中 update insert delete 分别给写个例子以及解释下例子的作用和意思被, 万分感谢!!!! 主要想知道下各个语句的书写规范. INSERT: 表1 (ID, ...
- SQL Server中常用的SQL语句(转):
SQL Server中常用的SQL语句 转自:http://www.cnblogs.com/rainman/archive/2013/05/04/3060428.html 1.概述 名词 笛卡尔积.主 ...
- SQL Server中常用的SQL语句
1.概述 名词 笛卡尔积.主键.外键 数据完整性 实体完整性:主属性不能为空值,例如选课表中学号和课程号不能为空 参照完整性:表中的外键取值为空或参照表中的主键 用户定义完整性:取值范围或非空限制,例 ...
- SQL Server中CURD语句的锁流程分析
我只在数据库选项已开启“行版本控制的已提交读”(READ_COMMITTED_SNAPSHOT为ON)中进行了观察. 因此只适用于这种环境的数据库. 该类数据库支持四种不同事务隔离级别,下面分别观察数 ...
随机推荐
- Duplicate entry '0' for key 'PRIMARY'
一般使用ORM时,提交新增实体时, mysql会出现此错误:Duplicate entry '0' for key 'PRIMARY' 原因是插入语句,未提供主键的值,且主键是非自增长的. 解决办法是 ...
- Navicat Premium for Mac 破解版地址
找了好几个都不能使用 试了一下这个 可以使用 放地址:http://www.orsoon.com/Mac/85386.html
- <自动化测试方案_2>第二章、自动化测试是什么?(What)
第二章.自动化测试是什么?(What) 自动化测试是相对于手工测试而言:通过脚本自动去执行测试用例,从而代替人完成测试工作. 自动化测试相对手工测试优缺点 测试方式 优点 缺点 手工测试 1,完整的对 ...
- leetcode-28.实现strStr()
leetcode-28.实现strStr() 题意 实现 strStr() 函数. 给定一个 haystack 字符串和一个 needle 字符串,在 haystack 字符串中找出 needle 字 ...
- Ubuntu-18.04安装Docker
Docker 介绍 Docker 是一个开源的应用容器引擎,让开发者可以打包他们的应用以及依赖包到一个可移植的容器中,然后发布到任何流行的 Linux 机器上,也可以实现虚拟化.容器是完全使用沙箱机制 ...
- JavaWeb入门笔记
Java web笔记 一.HTTP协议 HTTP(超文本传输协议),它是一种主流B/S架构中应用的通信协议.具有以下特点: 1.无状态 服务端不会记录客户端每次提交的请求,服务器一旦相应客户端之后,就 ...
- AngularJS学习之旅—AngularJS 简介(一)
一.AngularJS 简介 1.AngularJS 是一个 JavaScript 框架. AngularJS 是一个 JavaScript 框架.它是一个以 JavaScript 编写的库.Angu ...
- Cs231n课堂内容记录-Lecture2-Part1 图像分类
Lecture 2 课程内容记录:(上)https://zhuanlan.zhihu.com/p/20894041?refer=intelligentunit (下)https://zhuanlan. ...
- http协议与https协议
1.前言 在介绍 HTTP 协议之前,先简单说一下TCP/IP协议的相关内容.TCP/IP协议是分层的,从底层至应用层分别为:物理层.链路层.网络层.传输层和应用层,如下图所示: 2.http协议简介 ...
- logstash关于date时间处理的几种方式总结
1.第一种,直接在配置文件中自定义时间格式 这是tomcat配置文件中的一段日志时间配置,按照这样的配置,那么输出的日志是这样子的: 然后你继续在logstash中这样子配置 此时logstash就不 ...