Python框架学习之Flask中的数据库操作
数据库操作在web开发中扮演着一个很重要的角色,网站中很多重要的信息都需要保存到数据库中。如用户名、密码等等其他信息。Django框架是一个基于MVT思想的框架,也就是说他本身就已经封装了Model类,可以在文件中直接继承过来。但是在Flask中,并没有把Model类封装好,需要使用一个扩展包,Flask-SQLAlchemy。它是一个对数据库的抽象,让开发者不用这些编写SQL语句,而是使用其提供的接口去操作数据库,这其中涉及到一个非常重要的思想:ORM什么是ORM呢?下面我们就来详细讲解一下。
一、ORM
1. ORM的全称是:Object Relationship Map:对象-关系映射。主要的功能是实现模型对象到关系型数据库数据的映射。说白了就是使用通过对象去操作数据库。
2. 操作过程图:
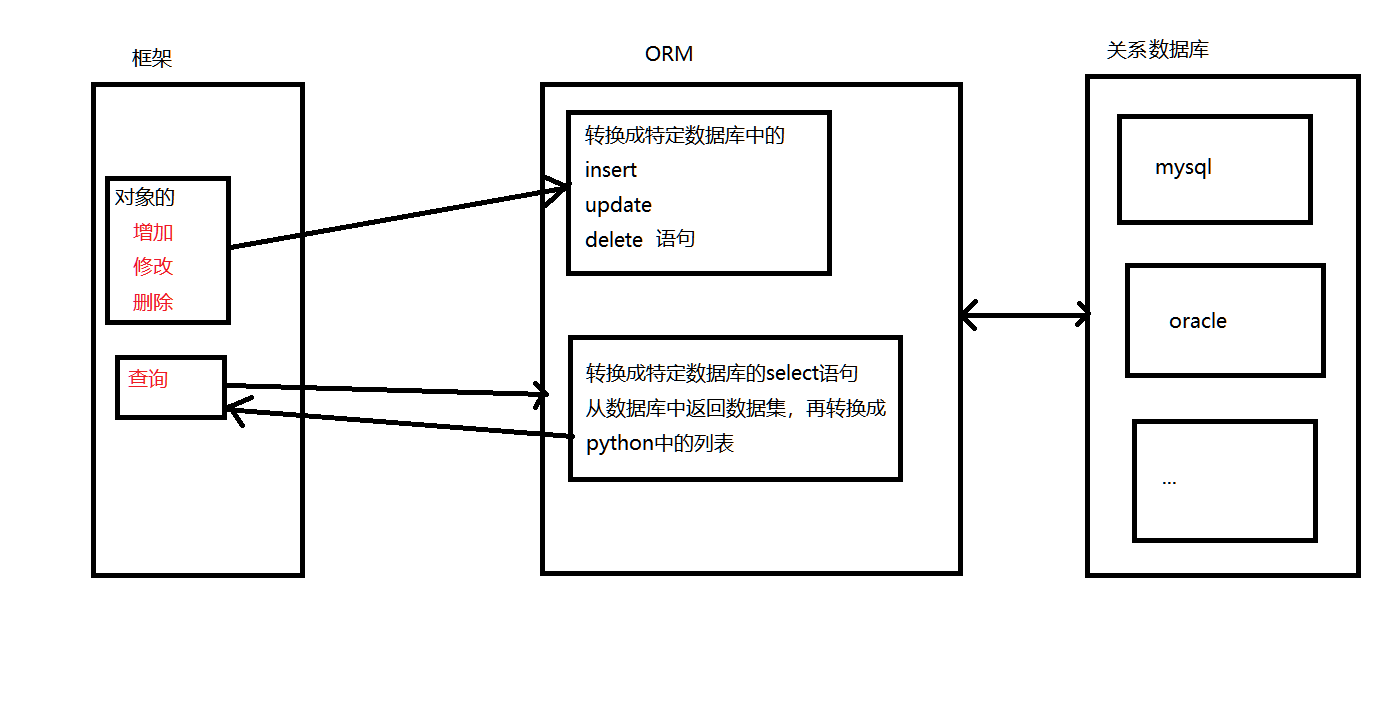
3. 优点:
(1). 不需要编写SQL代码,这样可以把精力放在业务逻辑处理上。
(2). 使用对象的方式去操作数据库。实现数据模型与数据库的解耦,利于开发。
4. 缺点:
性能较低。
二、Flask-SQLAlchemy的介绍
1.设置配置信息
在开发中,一般是把一些配置信息都写在一个单独的文件中,如settings.py。这样一些安全信息就可以得到保存!
重点字段有:
数据库的指定是使用URL的方式来指定的:'mysql://用户名:密码@服务器地址:端口号/数据库名',但是连接SQLite是使用这用格式:sqlite:////absolute/path/to/foo.db,使用////开头
SQLALCHEMY_DATABASE_URI = 'myslq://root:meiyou@127.0.0.1:3306/test'
SQLALCHEMY_POOL_RECYCLE:设置多少秒后自动回收连接,对MySQL来说,默认是2小时
SQLALCHEMY_ECHO:设置True的话,查询时会显示原始SQL语句。
SQLALCHEMY_TRACK_MODIFICATIONS:动态追踪修改设置。
2. 常用的SQLAlchemy字段类型:
Integer
String
Numberic
Boolean
Date
3. 常用的SQLAlchemy列选项
primary_key:如果为True,表示主键。Flask中没有自动生成主键,需要自定义。
unique:为True,设置该列不能有重复值,如用户名、邮箱、手机号
nullable:为True的话可以为null
default:设置默认值
index:为True,设置该列为索引,默认索引是主键。
4.关系选项
backref:在关系的另一模型中添加的反向引用,查询时起很大作用。
secondary:用于多对多关系中表的名字
primary join:
三、Flask-SQLAlchemy的基本操作
在Flask-SQLAlchemy中的增、删、改操作是由数据库会话(db.session)管理的。也就是说,在准备把数据写入数据库前,要先将数据添加(add())到会话中,然后使用commit()提交会话。
在Flask-SQLAlchemy中的查询操作都是通过query对象操作数据库。基本的查询是返回表中的所有数据,还可以使用过滤器进行更精确的数据库查询。
1.常用查询过滤器:
过滤器得到的还只是一些对象,需要使用执行器来获取真正的数据。
filter(): 把过滤器添加到原查询上,返回一个新查询,需要使用模型类名去获取字段来进行比较。
filter_by():把等值(只能使用=比较操作)过滤器添加到查询上,返回一个新查询。
order_by():根据指定条件对查询结果进行排序,返回一个新查询。
group_by():根据指定条件对原查询结果进行分组,返回一个新查询。
2.常用查询执行器
all():以列表的形式返回查询的所有结果
first():返回查询的第一个结果,
first_or_404():同first(), 只不过如果没有找到的话,返回404错误
get():返回指定主键对应的行,
get_or_404():返回指定主键对应的行,如不存在,返回404错误
count():返回查询结果的数量
paginate():返回一个Paginate对象,包含指定范围内的结果。
3. 查询条件
startswith('xx'):查询以xx开头的所有数据
endswith('xx'):查询以xx结尾的所有数据
not_():取反
and_():返回and()条件满足的所有数据
or_():返回or()条件满足的所有数据
from flask import Flask
from flask_sqlalchemy import SQLAlchemy
from settings import Config
app = Flask(__name__)
app.config.from_object(Config)
# 创建数据库实例对象
db = SQLAlchemy(app)
class Role(db.Model):
"""创建角色模型类"""
__tablename__ = 'roles'
id = db.Column(db.Integer, primary_key=True)
name = db.Column(db.String(64), unique=True)
# 描述roles表和users表的关系,
# 第一个参数为多那端的模型类名
# 第二个参数backref:为模型类名声明新属性,这样就可以实现反向查询
# 第三个参数决定了什么时候从数据库中查询数据
us = db.relationship('User', backref='role', lazy='dynamic')
def __repr__(self):
return 'Role:%s' % self.name
class User(db.Model):
"""创建用户模型类"""
# 设置表名
__tablename__ = 'users'
# 添加主键
id = db.Column(db.Integer, primary_key=True)
# 用户名
name = db.Column(db.String(30), unique=True)
email = db.Column(db.String(64), unique=True)
password = db.Column(db.String(64))
# 定义一个外键
role_id = db.Column(db.Integer, db.ForeignKey('roles.id'))
def __repr__(self):
return 'User:%s' % self.name
if __name__ == '__main__':
# 先删除表
db.drop_all()
# 创建表
db.create_all()
# 添加数据
app.run()
Python框架学习之Flask中的数据库操作的更多相关文章
- Python框架学习之Flask中的常用扩展包
Flask框架是一个扩展性非常强的框架,所以导致它有非常多的扩展包.这些扩展包的功能都很强大.本节主要汇总一些常用的扩展包. 一. Flask-Script pip install flask-scr ...
- Python框架学习之Flask中的蓝图与单元测试
因为Flask框架的集成度很低,随着Flask项目文件的增多,会导致不太好管理.但如果对一个项目进行模块化管理的,那样子管理起来就会特别方便.而在Flask中刚好就提供了这么一个特别好用的工具蓝图(B ...
- Python框架学习之Flask中的视图及路由
在前面一讲中我们学习如何创建一个简单的Flask项目,并做了一些简单的分析.接下来在这一节中就主要来讲讲Flask中最核心的内容之一:Werkzeug工具箱.Werkzeug是一个遵循WSGI协议的P ...
- Python框架学习之Flask中的Jinja2模板
前面也提到过在Flask中最核心的两个组件是Werkzeug和Jinja2模板.其中Werkzeug在前一节已经详细说明了.现在这一节主要是来谈谈Jinja2模板. 一.为什么需要引入模板: 在进行软 ...
- Spring框架学习10——JDBC Template 实现数据库操作
为了简化持久化操作,Spring在JDBC API之上提供了JDBC Template组件. 1.添加依赖 添加Spring核心依赖,MySQL驱动 <!--Spring核心基础依赖--> ...
- golang学习笔记16 beego orm 数据库操作
golang学习笔记16 beego orm 数据库操作 beego ORM 是一个强大的 Go 语言 ORM 框架.她的灵感主要来自 Django ORM 和 SQLAlchemy. 目前该框架仍处 ...
- android中的数据库操作(转)
android中的数据库操作 android中的应用开发很难避免不去使用数据库,这次就和大家聊聊android中的数据库操作. 一.android内的数据库的基础知识介绍 1.用了什么数据库 an ...
- android中的数据库操作(SQLite)
android中的数据库操作 android中的应用开发很难避免不去使用数据库,这次就和大家聊聊android中的数据库操作. 一.android内的数据库的基础知识介绍 1.用了什么数据库 an ...
- CI中的数据库操作以及AR连贯操作
要使用CI中的数据库操作,首先我们应该在CI的 application/config/databass.php 文件中配置数据库信息,通常就是配置主机名,用户名,密码,数据库名,表前缀(dbprefi ...
随机推荐
- webpack+vue+vueRouter模块化构建完整项目实例详细步骤-入门篇
新建项目 开始(确认已经安装node环境和npm包管理工具) 1.新建项目文件名为start_vuedemo 2.npm init -y 初始化项目,我的win7系统,工程在d盘的vue_test_p ...
- bitnami_redmine3.3.0-1 问题及备份恢复
1. 服务不见了处理方法: 安装Bitnami Redmine之后,会生成5个与之相关的进程,分别是 redmineApache redmineMySQL redmineSubversion redm ...
- 系统调用fork()在powerpc上的源码分析
总结一句话:系统调用的本质,通过sc指令触发异常,完成用户态到内核的转换. 展开一些:应用程序调用fork(),fork()是一个glibc函数,该函数的最底层调用sc指令,触发cpu异常,从而完成从 ...
- iOS ----------怎么修改xcode默认打开方式
很简单就能解决:选中文件,右键,显示简介,打开方式,选择8.2.然后打钩.
- 如何获取view的大小
很多初学者都会犯一个错误 ,就是在onCreate或者onStart里面去获取view的大小,然而这样获取到的宽高通常都是0,为什么呢?因为view的测量过程和activity的生命周期不是同步的,因 ...
- Android深入四大组件(九)Content Provider的启动过程
前言 Content Provider做为四大组件之一,通常情况下并没有其他的组件使用频繁,但这不能作为我们不去深入学习它的理由.关于Content Provider一篇文章是写不完的,这一篇文章先来 ...
- python base64 decode incorrect padding错误解决方法
个人觉得原因应该是不同的语言/base64库编码规则不太统一的问题. python中base64串的长度需为4的整数倍,故对长度不为4整数倍的base64串需要用"='补足 如下代码: da ...
- Jetbrains Idea连接TFS时配置的坑
#Team Explorer Everywherehttps://www.microsoft.com/en-us/search/result.aspx?q=team+explorer+everywhe ...
- redis sentinel集群的搭建
背景说明: 这里采用1主2从的redis集群,3个sentinel搭建高可用redis集群. 一,关于搭建redis-sentinel高可用之前,我们必须要了解redis主从搭建redis-senti ...
- 监控mysql主从同步
1,昨天看到shell一道面试题,需求如下: 监控MySQL主从同步是否异常,如果异常,则发送短信或者邮件给管理员.提示:如果没主从同步环境,可以用下面文本放到文件里读取来模拟:阶段1:开发一个守护进 ...