python3实战之字幕vtt与字母srt的相互转换
关于
- 0.本文将介绍一个字幕格式vtt与srt相互转换的py脚本。
- 1.代码大部分出自: https://www.cnblogs.com/BigJ/p/vtt_srt.html
- 2.但是自己针对上面的代码做了修改和增加。原始代码不支持批量转换,改为增加支持批量转换:
- 2.1 支持批量转换
- 2.2 还可以继续完善功能,比如用格式:
python3 XXX.py [源文件格式] [源目标文件路径] [目标文件输出路径]
目前还不支持这个格式,后面再做优化。以后再做吧
我的测试环境
- os: ubuntu
Linux xxxx-virtual-machine 5.4.0-47-generic #51-Ubuntu SMP Fri Sep 4 19:50:52 UTC 2020 x86_64 x86_64 x86_64 GNU/Linux
- python3
Python 3.8.2
用法
1. vtt -> srt
找一个适合你的文件夹,下面的这些操作都是基于这个文件夹:
- 1.1 创建目录vtt和srt
- 1.2 将vtt文件放入vtt目录,
- 1.3 创建main.py文件,文件内容最后一个章节的源码 。
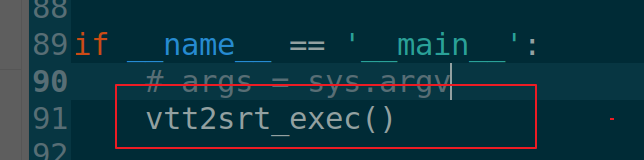
- 1.4 将vtt2srt_exec()添加到代码if name == 'main':的下一行
- 1.5 执行代命令
python3 main.py
- 1.6 打开srt目录,查看输出。
2. srt -> vtt
- 用法与 章节1类似。
- 不同的是:
- 1.4步骤替换为:srt2vtt_exec()添加到代码if name == 'main':的下一行 、
- 1.6步骤替换为: 打开vtt目录查看输出。
完整源码
import os
import sys
import re
def get_file_name(dir, file_extension):
f_list = os.listdir(dir)
result_list = []
for file_name in f_list:
if os.path.splitext(file_name)[1] == file_extension:
result_list.append(os.path.join(dir, file_name))
return result_list
def vtt2srt(file_name, output_dir):
content = open(file_name, "r", encoding="utf-8").read()
# 删除WEBVTT行
content = content.replace("WEBVTT", "", 1)
content = content.replace("Kind: captions", "", 1)
content = content.replace("Language: en-GB", "", 1)
# 替换“.”为“,”
content = re.sub("(\d{2}:\d{2}:\d{2}).(\d{3})", lambda m: m.group(1) + ',' + m.group(2), content)
# content = content.replace(",", ".")
output_file = output_dir + file_name[file_name.rfind("/"):]
output_file = os.path.splitext(output_file)[0] + '.srt'
open(output_file, "w", encoding="utf-8").write(content)
def srt2vtt(file_name):
content = open(file_name, "r", encoding="utf-8").read()
# 添加WEBVTT行
content = "WEBVTT\n\n" + content
# 替换“,”为“.”
content = re.sub("(\d{2}:\d{2}:\d{2}),(\d{3})", lambda m: m.group(1) + '.' + m.group(2), content)
# output_file = os.path.splitext(file_name)[0] + '.vtt'
output_file = output_dir + file_name[file_name.rfind("/"):]
output_file = os.path.splitext(output_file)[0] + '.vtt'
open(output_file, "w", encoding="utf-8").write(content)
# to get all .vtt files from cur_path
def file_name(file_dir, file_ext):
L=[]
for root, dirs, files in os.walk(file_dir):
for file in files:
if os.path.splitext(file)[1] == file_ext:
L.append(os.path.join(root, file))
return L
def vtt2srt_exec():
# 1.to get current directory
cur_path = os.getcwd() + "/vtt"
# 2. output folder
output_dir = os.getcwd() + "/srt"
if (False == os.path.exists(output_dir, ".vtt")):
os.mkdir(output_dir)
# 3. to convert
name_list = file_name(cur_path)
for file_vtt in name_list:
vtt2srt(file_vtt, output_dir)
def srt2vtt_exec():
# 1.to get current directory
cur_path = os.getcwd() + "/srt"
# 2. output folder
output_dir = os.getcwd() + "/vtt"
if (False == os.path.exists(output_dir)):
os.mkdir(output_dir)
# 3. to convert
name_list = file_name(cur_path, ".srt")
for file_srt in name_list:
srt2vtt(file_srt, output_dir)
if __name__ == '__main__':
# args = sys.argv
vtt2srt_exec()
python3实战之字幕vtt与字母srt的相互转换的更多相关文章
- MapReduce实战项目:查找相同字母组成的字谜
实战项目:查找相同字母组成的字谜 项目需求:一本英文书籍中包含有成千上万个单词或者短语,现在我们要从中找出相同字母组成的所有单词. 数据集和期望结果举例: 思路分析: 1)在Map阶段,对每个word ...
- Python3实战Spark大数据分析及调度 (网盘分享)
Python3实战Spark大数据分析及调度 搜索QQ号直接加群获取其它学习资料:715301384 部分课程截图: 链接:https://pan.baidu.com/s/12VDmdhN4hr7yp ...
- selenium3与Python3实战 web自动化测试框架 ☝☝☝
selenium3与Python3实战 web自动化测试框架 selenium3与Python3实战 web自动化测试框架 学习 教程 一.环境搭建 1.selenium环境搭建 Client: py ...
- Python3实战spark大数据分析及调度 ☝☝☝
Python3实战spark大数据分析及调度 ☝☝☝ 一.实例分析 1.1 数据 student.txt 1.2 代码 二.代码解析 2.1函数解析 2.1.1 collect() RDD的特性 在 ...
- selenium3与Python3实战 web自动化测试框架✍✍✍
selenium3与Python3实战 web自动化测试框架 整个课程都看完了,这个课程的分享可以往下看,下面有链接,之前做java开发也做了一些年头,也分享下自己看这个视频的感受,单论单个知识点课 ...
- Python3实战spark大数据分析及调度✍✍✍
Python3实战spark大数据分析及调度 整个课程都看完了,这个课程的分享可以往下看,下面有链接,之前做java开发也做了一些年头,也分享下自己看这个视频的感受,单论单个知识点课程本身没问题,大 ...
- 字幕文件 WebVTT 与 srt 之间的互相转化
1. WebVTT 2 srt 1. 用记事本打开 .vtt 文件: 2. 在记事本中点击 编辑 -> 替换 -> 查找内容中输入".",替换为中输入",& ...
- Python3实战系列之六(获取印度售后数据项目)
问题:续接上一篇.说干咱就干呀,勤勤恳恳写程序呀! 目标:此篇我们试着把python程序打包成.exe程序.这样就可以在服务器上运行了.实现首篇计划列表功能模块的第三步: 3..exe文件能在服务器上 ...
- Python3实战系列之二(获取印度售后数据项目)
问题:续接上一篇.说干咱就干呀,勤勤恳恳写程序呀! 目标:安装python和pycharm.要编写并运行python程序就需要电脑有开发工具和运行环境,所以此篇就是安装编辑和运行python程序的软件 ...
随机推荐
- Python基础之字典内置方法
目录 1. 字典 1.1 字典的作用 1.2 创建和使用字典 1.2.1 dict类 1.2.2 基本的字典操作 1.2.3 字典方法 1. 字典 映射:可以通过名称来访问其各个值的数据结构. 字典是 ...
- SQL-关联表查询(连表查询)
0.例如:select * from T1,T2 where T1.a=T2.a 1.连表查询 <=> join(inner join)内连接查询 数据源: Persion表: ...
- GeckoDriver的安装和使用
GeckoDriver用于驱动Firefox,在这之前请确保已经正确安装好了Firefox浏览器并可以正常运行. 一.GeckoDriver的安装 GitHub:https://github.com/ ...
- OpenSSH 密码和公钥认证原理探究
目录 配置和保护SSH H3 - 使用SSH 访问远程命令行 H4 - 什么是OpenSSH ? H4 - 登录方式: H4 - 登录并执行临时命令: H4 - 查看登录用户 H4 - 登录原理 密码 ...
- 【模板】缩点(Tarjan算法)/洛谷P3387
题目链接 https://www.luogu.com.cn/problem/P3387 题目大意 给定一个 \(n\) 个点 \(m\) 条边有向图,每个点有一个权值,求一条路径,使路径经过的点权值之 ...
- JVM2 类加载子系统
目录 类加载子系统 类加载器子系统 类加载器ClassLoader角色 类加载的过程 案例 加载Loading 连接Linking 初始化Intialization clinit() 类的加载器 虚拟 ...
- JavaIO——转换流、字符编码
1.转换流 转换流是将字节流变成字符流的流. OutputStreamWriter:将字节输出流转换成字符输出流. public class OutputStreamWriter extends Wr ...
- 命令行方式运行hadoop程序
1,写一个java代码.*.java.(这里从example 拷贝一个过来作为测试) cp src/examples/org/apache/hadoop/examples/WordCount.java ...
- centos7 docker 修改Nginx文件
1.docker 安装 nginx : docker安装Nginx还是很简单的,可以参考百度文章 ,或者参照docker安装mysql :https://www.cnblogs.com/jonrain ...
- axios使用步骤详解(附代码)
Axios是一个基于Promise的 HTTP 库,可以用在浏览器和node.js 中,因为尤大大的推荐,axios也变得越来越流行.最近项目中使用axios也遇到了一些问题,就借此机会总结一下,如有 ...