ElasticSearch进阶检索
ElasticSearch进阶检索
入门检索中讲了如何导入elastic提供的样本测试数据,下面我们用这些数据进一步检索
一、SearchAPI
ES 支持两种基本方式检索 :
1、一种是通过使用 REST request URI 发送搜索参数(uri+检索参数)
GET bank/_search 检索 bank 下所有信息,包括 type 和 docs
GET bank/_search?q=*&sort=account_number:asc 请求参数方式检索
2、另一种是通过使用 REST request body 来发送它们(uri+请求体)
GET /bank/_search
{
"query": {
"match_all": {}
},
"sort": [
{
"account_number": "asc"
}
]
}
# query 查询条件
# sort 排序条件
响应结果
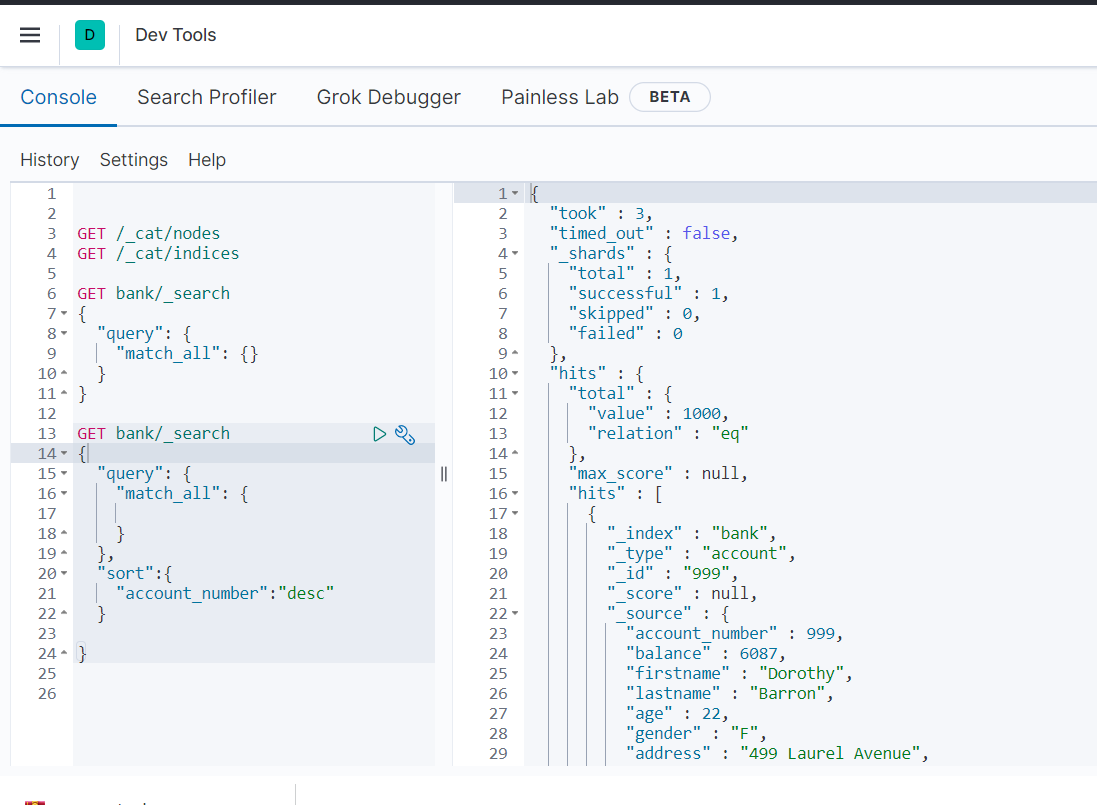
响应结果解释:
took - 执行搜索的时间(毫秒)
time_out - 告诉我们搜索是否超时
_shards - 告诉我们多少个分片被搜索了,以及统计了成功/失败的搜索分片
hits - 搜索结果
hits.total - 搜索结果条数
hits.hits - 实际的搜索结果数组(默认为前 10 的文档)
sort - 结果的排序 key(键)(没有则按 score 排序)
score 和 max_score –相关性得分和最高得分(全文检索用)
二、Query DSL
1、基本语法格式
Elasticsearch 提供了一个可以执行查询的 Json 风格的 DSL(domain-specific language 领域特
定语言)。这个被称为 Query DSL。
一个查询语句的典型结构:
QUERY_NAME:{
ARGUMENT:VALUE,
ARGUMENT:VALUE,...
}
如果针对于某个字段,那么它的结构如下:
{
QUERY_NAME:{
FIELD_NAME:{
ARGUMENT:VALUE,
ARGUMENT:VALUE,...
}
}
}
请求示例
GET bank/_search
{
"query": {
"match_all": {}
},
"from":0,
"size":5,
"sort": [
{
"balance": {
"order": "desc"
}
}
]
}
#query 定义如何查询
#match_all 查询类型【代表查询所有的所有】,es 中可以在 query 中组合非常多的查询类型完成复杂查询
#除了 query 参数之外,我们也可以传递其它的参数以改变查询结果。如 sort,size from+size 限定完成分页
#sort 排序,多字段排序,会在前序字段相等时后续字段内部排序,否则以前序为准
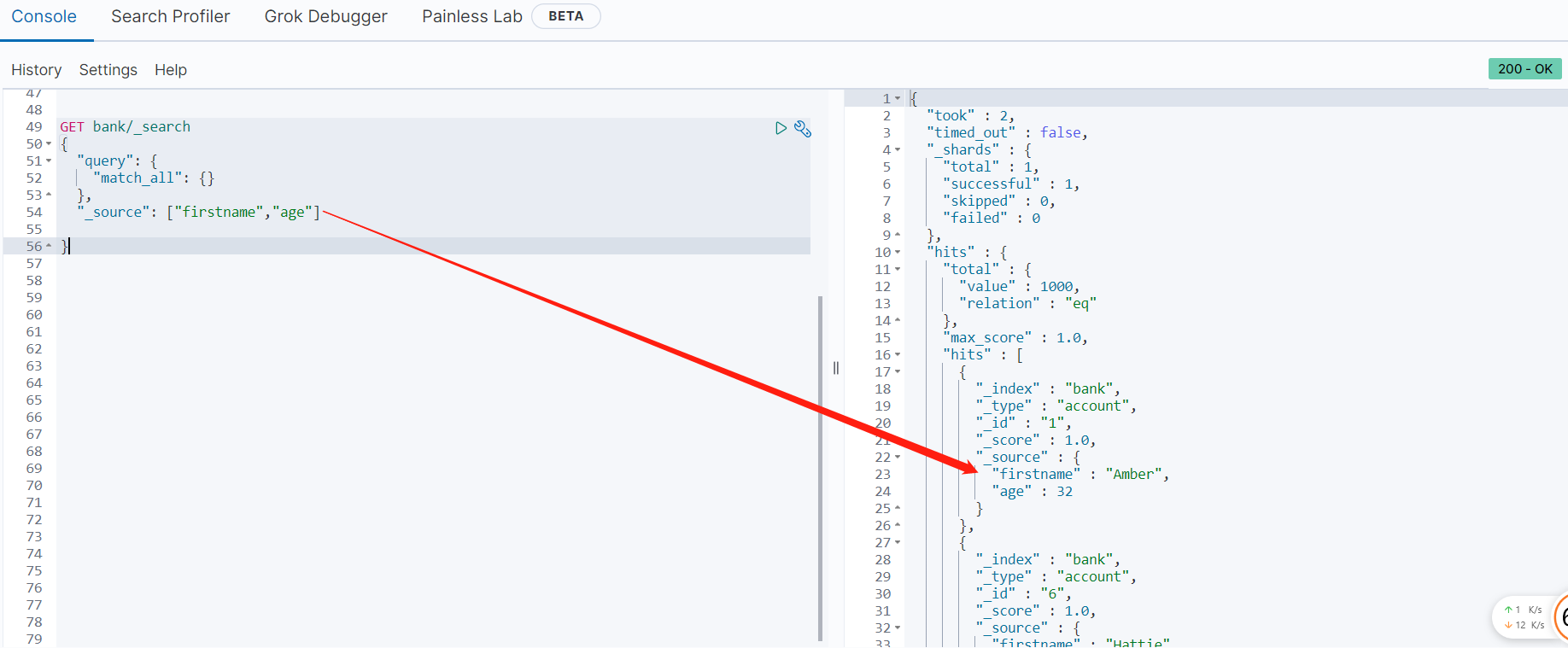
2、返回部分字段
_source:需要返回哪些字段写在数组中即可
3、match【匹配查询】
(1)对于基本数据类型的(非字符串),进行精确匹配
GET bank/_search
{
"query": {
"match": {
"account_number": 10
}
}
}
#match 返回 account_number=10 的
(2)对于字符串类型的字段,进行全文检索,模糊匹配
GET bank/_search
{
"query": {
"match": {
"address": "mill"
}
}
}
#最终查询出 address 中包含 mill 单词的所有记录
#match 当搜索字符串类型的时候,会进行全文检索,并且每条记录有相关性得分
(3)字符串,多个单词(分词+全文检索)
GET bank/_search
{
"query": {
"match": {
"address": "mill road"
}
}
}
#最终查询出 address 中包含 mill 或者 road 或者 mill road 的所有记录,并给出相关性得分(_score),也会按照这个评分排序
(4)精确匹配文本字符串
GET bank/_search
{
"query": {
"match": {
"address.keyword": " Mill road"
}
}
}
# 查找 address完全为Mill Street 的数据
4、match_phrase【短语匹配】
将需要匹配的值当成一个整体单词(不分词)进行检索
GET bank/_search
{
"query": {
"match_phrase": {
"address": "mill road"
}
}
}
#查出 address 中包含 mill road 的所有记录,并给出相关性得分
5、multi_match【多字段匹配】
GET bank/_search
{
"query": {
"multi_match": {
"query": "mill",
"fields": [
"city","address"
]
}
}
}
#检索 city 或 address 匹配包含 mill 的数据,会对查询条件分词
6、bool【复合查询】
bool 用来做复合查询: 复合语句可以合并任何其它查询语句,包括复合语句,复合语句之间可以互相嵌套,可以表达非常复杂的逻辑
(1)must:必须达到must所列举的所有条件
GET bank/_search
{
"query": {
"bool": {
"must": [
{"match": {"firstname": "Forbes"}},
{"match": {"gender": "M"}}
]
}
}
}
(2)must_not 必须不是指定的情况
GET bank/_search
{
"query": {
"bool": {
"must": [
{"match": {"firstname": "Forbes"}},
{"match": {"gender": "M"}}
],
"must_not": [
{"match": {"lastname": "Wallace"}}
]
}
}
}
(3)should:应该达到 should列举的条件
如果达到会增加相关文档的评分并不会改变 查询的结果。如果 query 中只有 should 且只有一种匹配规则,那么 should 的条件就会被作为默认匹配条件而去改变查询结果
GET bank/_search
{
"query": {
"bool": {
"must": [
{"match": {"address": "mill"}},
{"match": { "gender": "M" }}
],
"should": [ {"match": { "address": "lane" }} ]
}
}
}
#应该匹配,匹配到能增加文档相关性得分,匹配不到也不会影响查询结果
7、filter【结果过滤】
不是所有的查询都需要计算相关性得分,仅用于 “filtering”(过滤)的文档。为了不计算分数 Elasticsearch 会自动检查场景并且优化查询的执行。
GET bank/_search
{
"query": {
"bool": {
"must": [
{"match": {"address": "mill"}}
],
"filter": [
{"range": {
"balance": {
"gte": 10000,
"lte": 20000
}
}}
]
}
}
}
#range范围查询,大于1000小于20000
8、term精确检索
避免使用 term 查询文本字段,默认情况下,Elasticsearch 会通过analysis分词将文本字段的值拆分为一部分,这使精确匹配文本字段的值变得困难。如果要查询文本字段值,请使用 match 查询代替。
和 match 一样,匹配某个属性的值。全文检索字段用 match,其他非 text 字段匹配用 term
GET bank/_search
{
"query": {
"term": {
"age": "20"
}
}
}
9、Aggregation-执行聚合
聚合提供了从数据中分组和提取数据的能力。最简单的聚合方法大致等于 SQL GROUP BY 和 SQL聚合函数。
详细的介绍可以查看官网关于Aggregation的文档,下面提供几个示例来看一下聚合
https://www.elastic.co/guide/en/elasticsearch/reference/7.11/search-aggregations.html
(1)搜索address中包含 mill的所有人的年龄分布以及平均年龄,但不显示这些人的详情
GET bank/_search
{
"query": {
"match": {
"address": "mill"
}
},
"aggs": {
"group_by_state": {
"terms": {
"field": "age"
}
},
"avg_age":{
"avg": {
"field": "age"
}
}
},
"size": 0
}
#size:0 不显示搜索数据
#aggs:执行聚合。聚合语法如下:
#"aggs": {
"aggs_name 这次聚合的名字,方便展示在结果集中": {
"AGG_TYPE 聚合的类型(avg,term,terms)": {
"field": "age"
}
}
}
(2)按照年龄聚合,并且请求这些年龄段的这些人的平均薪资
GET bank/_search
{
"query": {"match_all": {}},
"aggs": {
"group_by_state": {
"terms": {
"field": "age"
},
"aggs": {
"avg_age": {
"avg": {
"field": "age"
}
}
}
}
}
}
#其实就是aggs里面又加了一个aggs,第二个aggs根据第一个aggs聚合后的结果在聚合
(3)查出所有年龄分布,并且这些年龄段中 性别为M 的平均薪资和 性别为F 的平均薪资以及这个年龄
段的总体平均薪资
GET bank/_search
{
"query": {"match_all": {}},
"aggs": {
"age_avg":{
"terms": {
"field": "age",
"size": 1000
},
"aggs": {
"gender_avg": {
"terms": {
"field": "gender.keyword",
"size": 10
},
"aggs": {
"balance_avg": {
"avg": {
"field": "balance"
}
}
}
},
"balance_avg": {
"avg": {
"field": "balance"
}
}
}
}
}
}
ElasticSearch进阶检索的更多相关文章
- ElasticSearch 进阶
目录 ElasticSearch 进阶 SearchAPI 检索信息 Query DSL 基本语法格式 查询-match 查询-match_phrase 查询-multi_match 查询-bool复 ...
- ElasticSearch入门检索
前面简介说到 elsatic是通过RestFul API接口操作数据的,可以通过postman模拟接口请求测试一下 一._cat 1.GET /_cat/nodes:查看所有节点 2.GET /_ca ...
- Elasticsearch原理学习--为什么Elasticsearch/Lucene检索可以比MySQL快?
转载于:http://vlambda.com/wz_wvS2uI5VRn.html 同样都可以对数据构建索引并通过索引查询数据,为什么Lucene或基于Lucene的Elasticsearch会比关系 ...
- 分布式搜索elasticsearch 文献检索索引 入门
1.首先,例如,下面的数据被提交给ES该指数 {"number":32768,"singer":"杨坤","size": ...
- 搭建ElasticSearch+MongoDB检索系统
ElasticSearch是一个基于Lucene的搜索服务器.它提供了一个分布式多用户能力的全文搜索引擎,基于RESTful web接口.Elasticsearch是用Java开发的,并作为Apach ...
- ES 19 - Elasticsearch的检索语法(_search API的使用)
目录 1 Search API的基本用法 1.1 查询所有数据 1.2 响应信息说明 1.3 timeout超时机制 1.4 查询多索引和多类型中的数据 2 URI Search的用法 2.1 GET ...
- Elasticsearch高级检索之使用单个字母数字进行分词N-gram tokenizer(不区分大小写)【实战篇】
一.前言 小编最近在做到一个检索相关的需求,要求按照一个字段的每个字母或者数字进行检索,如果是不设置分词规则的话,英文是按照单词来进行分词的. 小编以7.6.0版本做的功能哈,大家可以根据自己的版本去 ...
- elasticsearch 拼音检索能力研究
gitchennan/elasticsearch-analysis-lc-pinyin 配置参数少,功能满足需求. 对应版本 elasticsearch2.3.2 对应 elasticsearch-a ...
- ElasticSearch 分页检索
在ElasticSearch的多索引和多类别里说到我们在集群中有14个文档匹配我们的(空)搜索语句.单数仅仅有10个文档在hits数组中.我们怎样看到其它文档? 和SQL使用LIMITkeyword返 ...
随机推荐
- 43、uniq命令
相邻去重 uniq -c 表示相邻去重并统计: 1.uniq介绍: uniq是对指定的ascii文件或标准输入进行唯一性检查,以判断文本文件中重复出现的行,常用于系统排查及日志分析: 2.命令格式: ...
- POJ 3761:Bubble Sort——组合数学
题目大意:众所周知冒泡排序算法多数情况下不能只扫描一遍就结束排序,而是要扫描好几遍.现在你的任务是求1~N的排列中,需要扫描K遍才能排好序的数列的个数模20100713.注意,不同于真正的冒泡排序算法 ...
- springCloud学习05之api网关服务zuul过滤器filter
前面学习了zuul的反向代理.负载均衡.fallback回退.这张学习写过滤器filter,做java web开发的对filter都不陌生,那就是客户端(如浏览器)发起请求的时候,都先经过过滤器fil ...
- 6 shell内置命令
知识点1:什么是shell内建命令? Shell 内建命令,就是由 Bash 自身提供的命令,而不是文件系统中的某个可执行文件. 内建命令与普通命令的性质是不一样的,内建命令并不是某个外部文件,只要在 ...
- android开发相关知识笔记
1.xpage页面打开: openPage(TestFragment.class) openPage("标识") // 页面打开等待结果返回: openPageForResult( ...
- Python单元测试框架unittest之生成测试报告(HTMLTestRunner)
前言 批量执行完用例后,生成的测试报告是文本形式的,不够直观,为了更好的展示测试报告,最好是生成HTML格式的. unittest里面是不能生成html格式报告的,需要导入一个第三方的模块:HTMLT ...
- CF1444D Rectangular Polyline[题解]
Rectangular Polyline 题目大意 给定 \(h\) 条长度分别为 \(l_1,l_2,--,l_h\) 的水平线段以及 \(v\) 条长度分别为 \(p_1,p_2,--.p_v\) ...
- C语言:带参数的宏与函数的区别
带参数的宏和函数很相似,但有本质上的区别:宏展开仅仅是字符串的替换,不会对表达式进行计算:宏在编译之前就被处理掉了,它没有机会参与编译,也不会占用内存.而函数是一段可以重复使用的代码,会被编译,会给它 ...
- python numpy 求数组的百位分数
百分位数,统计学术语,如果将一组数据从小到大排序,并计算相应的累计百分位,则某一百分位所对应数据的值就称为这一百分位的百分位数.运用在教育统计学中,例如表现测验成绩时,称PR值.分位数是以概率将一批数 ...
- 【转载】SpringMVC学习笔记
转载于:SpringMVC笔记 SpringMVC 1.SpringMVC概述 MVC: Model(模型): 数据模型,提供要展示的数据,:Value Object(数据Dao) 和 服务层(行为S ...