lagou数据爬取
1. 使用的工具
selenium+xpath+ 手动输入登录
2. 实现的功能:
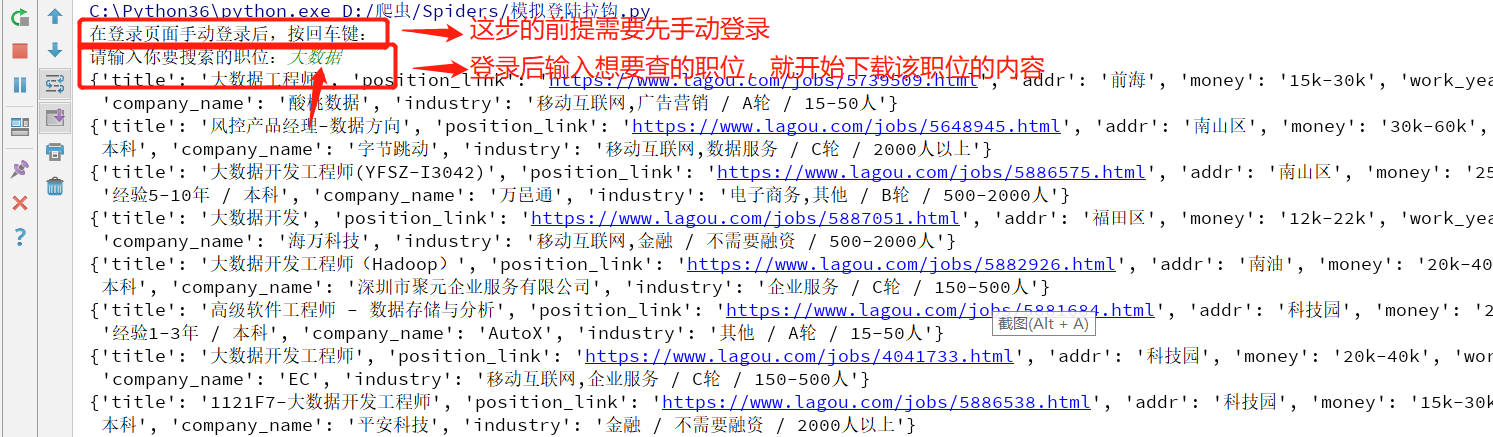
1.手动登录后,按终端提示,就能下载所需要的内容
import requests
import json
import time
import random
from lxml import etree
from concurrent.futures import ThreadPoolExecutor
from selenium import webdriver import pymongo # 连接mongo 数据库
client = pymongo.MongoClient()
db = client.lougou
collention =db.lou # 进入拉钩首页
url ='https://www.lagou.com/'
bro = webdriver.Chrome() bro.get(url) input('在登录页面手动登录后,按回车键:') # 进入了自己登录页面
# 找到收缩框
search_input = bro.find_element_by_id('search_input') # 找到搜索按钮
search_button = bro.find_element_by_id('search_button') # 输入你需要搜索的职位
search_msg = input('请输入你要搜索的职位:') # 在输入框自动填入搜索内容
search_input.send_keys(search_msg) # 自动点击搜索按钮
search_button.click() def get_data():
'''
提取页面数据 将数据存入 mongo 数据库
'''
time.sleep(1) # 获取页面内容
page=bro.page_source
time.sleep(2) tree = etree.HTML(page) li_list =tree.xpath("//ul[@class='item_con_list']/li") for li in li_list:
item={} item['title'] =li.xpath('.//h3/text()')[0] # 职位标题
item['position_link'] = li.xpath(".//a[@class='position_link']/@href")[0] # 职位详情链接
item['addr'] = li.xpath(".//span[@class='add']/em/text()")[0].strip() # 公司区域
item['money'] = li.xpath(".//div[@class='li_b_l']/span/text()")[0] # 岗位工资
item['work_year'] = li.xpath(".//div[@class='p_bot']/div[@class='li_b_l']//text()") #
item['work_year'] = [i.strip() for i in item['work_year'] if i.strip()]
item['work_year'] =item['work_year'][1] # 工作经历
item['company_name'] = li.xpath(".//div[@class='company_name']/a/text()")[0] # 公司名字
item['industry'] = li.xpath(".//div[@class='industry']/text()")[0].strip() # 公司所属行业 print(item)
# 将数据存到MongoDB 中 collention.insert(item) get_data() # 翻页下载该搜索也的所有页的数据
while 1: try:
# 下一页
next =bro.find_element_by_xpath('//span[@class="pager_next "]')
next.click() get_data() except : print('没有下一页了。。。。。') break # 进入循环 ,实现 用户再次 输入 不同职位进行下载该类职位的信息 ,用户可以按 q 或 Q 退出下载
while 1: keyword_input = bro.find_element_by_id('keyword') # 搜索框
submit_btn = bro.find_element_by_id('submit') # 搜索按钮 # 清空输入搜索框的内容
keyword_input.clear() # 重新进行搜索
msg2 =input('请输入你要下载的职位信息:') # 退出循环条件,退出下载
if msg2.upper()=='Q':
break keyword_input.send_keys(msg2)
# 点击搜索
submit_btn.click() # 下载该页面的数据
get_data() while 1: try:
# 下一页
next =bro.find_element_by_xpath('//span[@class="pager_next "]')
next.click() # 进入下一页,进行下载该页的数据
get_data() except : print('没有下一页了。。。。。') break # 关闭数据库
client.close() # 关闭浏览器 bro.quit()
代码
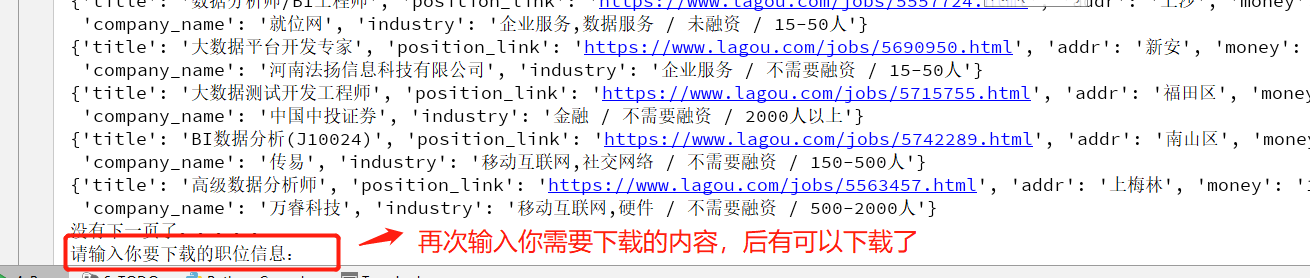
2. 你第一次输入的职位下载完会提醒你,你可以再次下载你所需要的其他职位的数据
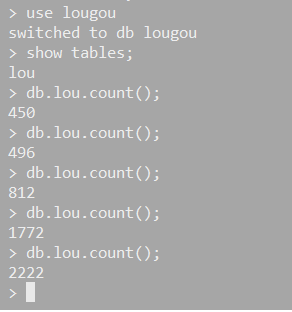
3. 数据保存在了 mongo中,此处没有做扩展,存文件或其他数据库
lagou数据爬取的更多相关文章
- 爬虫1.5-ajax数据爬取
目录 爬虫-ajax数据爬取 1. ajax数据 2. selenium+chromedriver知识准备 3. selenium+chromedriver实战拉勾网爬虫代码 爬虫-ajax数据爬取 ...
- python实现人人网用户数据爬取及简单分析
这是之前做的一个小项目.这几天刚好整理了一些相关资料,顺便就在这里做一个梳理啦~ 简单来说这个项目实现了,登录人人网并爬取用户数据.并对用户数据进行分析挖掘,终于效果例如以下:1.存储人人网用户数据( ...
- 芝麻HTTP:JavaScript加密逻辑分析与Python模拟执行实现数据爬取
本节来说明一下 JavaScript 加密逻辑分析并利用 Python 模拟执行 JavaScript 实现数据爬取的过程.在这里以中国空气质量在线监测分析平台为例来进行分析,主要分析其加密逻辑及破解 ...
- Python爬虫 股票数据爬取
前一篇提到了与股票数据相关的可能几种数据情况,本篇接着上篇,介绍一下多个网页的数据爬取.目标抓取平安银行(000001)从1989年~2017年的全部财务数据. 数据源分析 地址分析 http://m ...
- quotes 整站数据爬取存mongo
安装完成scrapy后爬取部分信息已经不能满足躁动的心了,那么试试http://quotes.toscrape.com/整站数据爬取 第一部分 项目创建 1.进入到存储项目的文件夹,执行指令 scra ...
- Ajax数据爬取
Ajax的基本原理 以菜鸟教程的代码为例: XMLHTTPRequest对象是JS对Ajax的底层实现: var xmlhttp; if (window.XMLHttpRequest) { // IE ...
- Python爬虫入门教程 15-100 石家庄政民互动数据爬取
石家庄政民互动数据爬取-写在前面 今天,咱抓取一个网站,这个网站呢,涉及的内容就是 网友留言和回复,特别简单,但是网站是gov的.网址为 http://www.sjz.gov.cn/col/14900 ...
- 基于 PHP 的数据爬取(QueryList)
基于PHP的数据爬取 官方网站站点 简单. 灵活.强大的PHP采集工具,让采集更简单一点. 简介: QueryList使用jQuery选择器来做采集,让你告别复杂的正则表达式:QueryList具有j ...
- Scrapy 框架 CrawlSpider 全站数据爬取
CrawlSpider 全站数据爬取 创建 crawlSpider 爬虫文件 scrapy genspider -t crawl chouti www.xxx.com import scrapy fr ...
随机推荐
- 【LeetCode】532. K-diff Pairs in an Array 解题报告(Python & C++)
作者: 负雪明烛 id: fuxuemingzhu 个人博客: http://fuxuemingzhu.cn/ 目录 题目描述 题目大意 解题方法 字典 日期 题目地址:https://leetcod ...
- 【LeetCode】822. Card Flipping Game 解题报告(Python)
作者: 负雪明烛 id: fuxuemingzhu 个人博客: http://fuxuemingzhu.cn/ 题目地址:https://leetcode.com/problems/card-flip ...
- hdu-1593 find a way to escape(贪心,数学)
思路:两个人都要选取最优的策略. 先求外层那个人的角速度,因为他的角速度是确定的,再求内层人的当角速度和外层人一样时的对应的圆的半径r1.外层圆的半径为d; 那么如果r1>=外围圆的半径,那么肯 ...
- web安全之burpsuite实战
burpsuite暴力破解实战 一.burpsuite的下载及安装使用b站有详细参考 二.burpsuite: 1.熟悉comparer,repeater,intruder模块. (1) comp ...
- java泛型中<?>和<T>
T 代表一种类型 加在类上==============>class SuperClass<A>{} 加在方法上============>public <T>void ...
- Generative Adversarial Nets (GAN)
目录 目标 框架 理论 数值实验 代码 Generative Adversarial Nets 这篇文章,引领了对抗学习的思想,更加可贵的是其中的理论证明,证明很少却直击要害. 目标 GAN,译名生成 ...
- 代码质量管理sonarqube部署使用
一.sonarqube的部署 1.下载sonaqube:https://www.sonarqube.org/downloads/ 根据需要下载特定版本: 2.如果通过sonar-scanner进行代码 ...
- 一文搞懂Google Navigation Component
一文搞懂Google Navigation Component 应用中的页面跳转是一个常规任务, Google官方提供的解决方案是Android Jetpack的Navigation componen ...
- IntelliJ IDEA 2019.3 代码提示忽略大小写(IDEA 2019版本如何设置代码提示不分大小写?)
最近在使用IDEA,发现每次只能进行完全匹配,且区分大小写,界面变了IDEA 2019.3 忽略大小写设置跟之前的版本稍微有点不同,跟之前的软件有点点区别,在此记录一下不区分大小写的方法. 1. 使用 ...
- Java初学者作业——完成对已定义类(Admin)的对象的创建。并完成属性的赋值和方法的调用。
返回本章节 返回作业目录 需求说明: 完成对已定义类(Admin)的对象的创建.并完成属性的赋值和方法的调用. 实现思路: 创建 MyTest 类,并添加 main函数. 在 main函数中完成对 A ...