lagou数据爬取
1. 使用的工具
selenium+xpath+ 手动输入登录
2. 实现的功能:
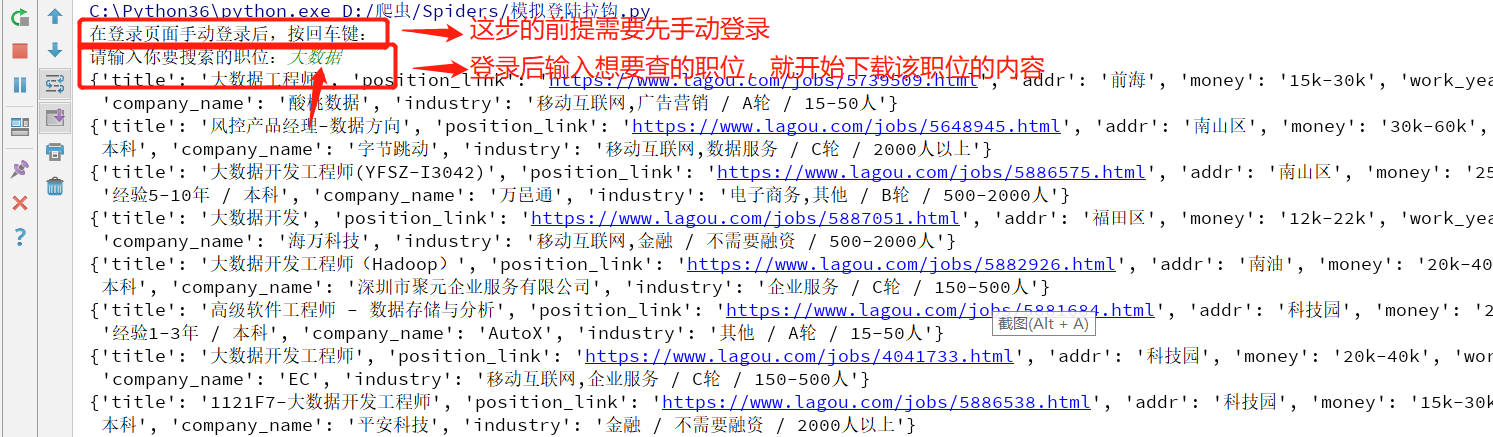
1.手动登录后,按终端提示,就能下载所需要的内容
import requests
import json
import time
import random
from lxml import etree
from concurrent.futures import ThreadPoolExecutor
from selenium import webdriver import pymongo # 连接mongo 数据库
client = pymongo.MongoClient()
db = client.lougou
collention =db.lou # 进入拉钩首页
url ='https://www.lagou.com/'
bro = webdriver.Chrome() bro.get(url) input('在登录页面手动登录后,按回车键:') # 进入了自己登录页面
# 找到收缩框
search_input = bro.find_element_by_id('search_input') # 找到搜索按钮
search_button = bro.find_element_by_id('search_button') # 输入你需要搜索的职位
search_msg = input('请输入你要搜索的职位:') # 在输入框自动填入搜索内容
search_input.send_keys(search_msg) # 自动点击搜索按钮
search_button.click() def get_data():
'''
提取页面数据 将数据存入 mongo 数据库
'''
time.sleep(1) # 获取页面内容
page=bro.page_source
time.sleep(2) tree = etree.HTML(page) li_list =tree.xpath("//ul[@class='item_con_list']/li") for li in li_list:
item={} item['title'] =li.xpath('.//h3/text()')[0] # 职位标题
item['position_link'] = li.xpath(".//a[@class='position_link']/@href")[0] # 职位详情链接
item['addr'] = li.xpath(".//span[@class='add']/em/text()")[0].strip() # 公司区域
item['money'] = li.xpath(".//div[@class='li_b_l']/span/text()")[0] # 岗位工资
item['work_year'] = li.xpath(".//div[@class='p_bot']/div[@class='li_b_l']//text()") #
item['work_year'] = [i.strip() for i in item['work_year'] if i.strip()]
item['work_year'] =item['work_year'][1] # 工作经历
item['company_name'] = li.xpath(".//div[@class='company_name']/a/text()")[0] # 公司名字
item['industry'] = li.xpath(".//div[@class='industry']/text()")[0].strip() # 公司所属行业 print(item)
# 将数据存到MongoDB 中 collention.insert(item) get_data() # 翻页下载该搜索也的所有页的数据
while 1: try:
# 下一页
next =bro.find_element_by_xpath('//span[@class="pager_next "]')
next.click() get_data() except : print('没有下一页了。。。。。') break # 进入循环 ,实现 用户再次 输入 不同职位进行下载该类职位的信息 ,用户可以按 q 或 Q 退出下载
while 1: keyword_input = bro.find_element_by_id('keyword') # 搜索框
submit_btn = bro.find_element_by_id('submit') # 搜索按钮 # 清空输入搜索框的内容
keyword_input.clear() # 重新进行搜索
msg2 =input('请输入你要下载的职位信息:') # 退出循环条件,退出下载
if msg2.upper()=='Q':
break keyword_input.send_keys(msg2)
# 点击搜索
submit_btn.click() # 下载该页面的数据
get_data() while 1: try:
# 下一页
next =bro.find_element_by_xpath('//span[@class="pager_next "]')
next.click() # 进入下一页,进行下载该页的数据
get_data() except : print('没有下一页了。。。。。') break # 关闭数据库
client.close() # 关闭浏览器 bro.quit()
代码
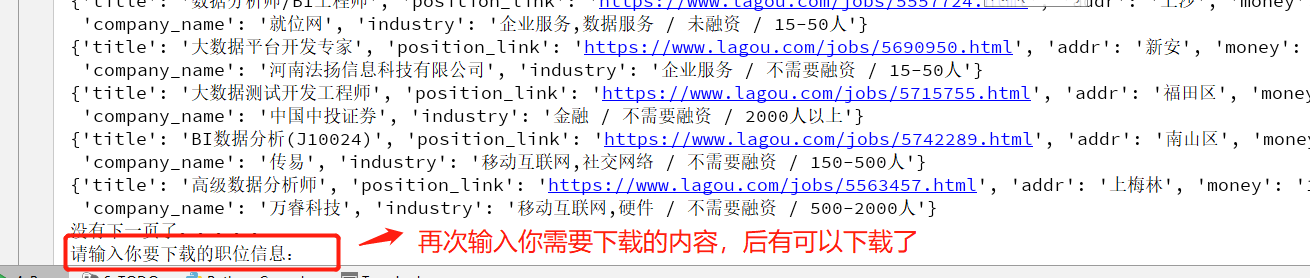
2. 你第一次输入的职位下载完会提醒你,你可以再次下载你所需要的其他职位的数据
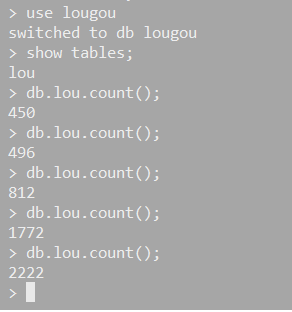
3. 数据保存在了 mongo中,此处没有做扩展,存文件或其他数据库
lagou数据爬取的更多相关文章
- 爬虫1.5-ajax数据爬取
目录 爬虫-ajax数据爬取 1. ajax数据 2. selenium+chromedriver知识准备 3. selenium+chromedriver实战拉勾网爬虫代码 爬虫-ajax数据爬取 ...
- python实现人人网用户数据爬取及简单分析
这是之前做的一个小项目.这几天刚好整理了一些相关资料,顺便就在这里做一个梳理啦~ 简单来说这个项目实现了,登录人人网并爬取用户数据.并对用户数据进行分析挖掘,终于效果例如以下:1.存储人人网用户数据( ...
- 芝麻HTTP:JavaScript加密逻辑分析与Python模拟执行实现数据爬取
本节来说明一下 JavaScript 加密逻辑分析并利用 Python 模拟执行 JavaScript 实现数据爬取的过程.在这里以中国空气质量在线监测分析平台为例来进行分析,主要分析其加密逻辑及破解 ...
- Python爬虫 股票数据爬取
前一篇提到了与股票数据相关的可能几种数据情况,本篇接着上篇,介绍一下多个网页的数据爬取.目标抓取平安银行(000001)从1989年~2017年的全部财务数据. 数据源分析 地址分析 http://m ...
- quotes 整站数据爬取存mongo
安装完成scrapy后爬取部分信息已经不能满足躁动的心了,那么试试http://quotes.toscrape.com/整站数据爬取 第一部分 项目创建 1.进入到存储项目的文件夹,执行指令 scra ...
- Ajax数据爬取
Ajax的基本原理 以菜鸟教程的代码为例: XMLHTTPRequest对象是JS对Ajax的底层实现: var xmlhttp; if (window.XMLHttpRequest) { // IE ...
- Python爬虫入门教程 15-100 石家庄政民互动数据爬取
石家庄政民互动数据爬取-写在前面 今天,咱抓取一个网站,这个网站呢,涉及的内容就是 网友留言和回复,特别简单,但是网站是gov的.网址为 http://www.sjz.gov.cn/col/14900 ...
- 基于 PHP 的数据爬取(QueryList)
基于PHP的数据爬取 官方网站站点 简单. 灵活.强大的PHP采集工具,让采集更简单一点. 简介: QueryList使用jQuery选择器来做采集,让你告别复杂的正则表达式:QueryList具有j ...
- Scrapy 框架 CrawlSpider 全站数据爬取
CrawlSpider 全站数据爬取 创建 crawlSpider 爬虫文件 scrapy genspider -t crawl chouti www.xxx.com import scrapy fr ...
随机推荐
- 【LeetCode】884. Uncommon Words from Two Sentences 解题报告(Python)
作者: 负雪明烛 id: fuxuemingzhu 个人博客: http://fuxuemingzhu.cn/ 目录 题目描述 题目大意 解题方法 字典统计 日期 题目地址:https://leetc ...
- Lucky Substrings
而在26以内且属于fibonacci数列的数为1,2,3,5,8,13,21时间限制:10000ms 单点时限:1000ms 内存限制:256MB 描述 A string s is LUCKY if ...
- APP打开(四)—Deeplink推广,打开率很低怎么排查
在开始正文之前,先解释一下,这里提到的打开率指的是点击了Deeplink之后正常打开了APP和点击量的比值. 开始正文: 但凡做TOC业务的多多少少都会用到Deeplink,这是一个重要的运营手段.但 ...
- 洛谷 P1434 [SHOI2002]滑雪(DP,记忆化搜索)
题目描述 Michael喜欢滑雪.这并不奇怪,因为滑雪的确很刺激.可是为了获得速度,滑的区域必须向下倾斜,而且当你滑到坡底,你不得不再次走上坡或者等待升降机来载你.Michael想知道在一个区域中最长 ...
- JVM垃圾收集器专题
垃圾收集器:利用垃圾收集算法,实现垃圾回收的实践落地. 1 HotSpot垃圾回收器 HotSpot垃圾回收器有多个,可以配合使用. 1.1 垃圾回收的一些术语 术语: Stop the world ...
- Java代码实体类生成SQL语句(Java实体类转数据库)
有的时候把数据库删了,如果照着实体类重新创建数据库的话比较麻烦,可以使用这个工具,把代码复制到项目里面设置一下即可把Java代码中的实体类转换为SQL语句输出为一个文件,打开执行命令即可. 下载:ht ...
- Java初学者作业——为某超市设计管理系统,需要在控制台展示系统菜单,菜单之间可以完成跳转。
返回本章节 返回作业目录 需求说明: 为某超市设计管理系统,需要在控制台展示系统菜单,菜单之间可以完成跳转. 实现思路: 定义mainMenu方法,用于显示主菜单. 主菜单主要负责显示4个选项,分别是 ...
- Flask_generate_password_hash的加盐哈希加密算法与check_password_hash的校验
密码加密简介 密码存储的主要形式: 明文存储:肉眼就可以识别,没有任何安全性. 加密存储:通过一定的变换形式,使得密码原文不易被识别. 密码加密的几类方式: 明文转码加密算法:BASE64, 7BIT ...
- git branch --set-upstream-to 本地关联远程分支
最近使用git pull的时候多次碰见下面的情况: There is no tracking information for the current branch. Please specify wh ...
- Python实战案例系列(一)
本节目录 烟草扫码数据统计 奖学金统计 实战一.烟草扫码数据统计 1. 需求分析 根据扫码信息在数据库文件中匹配相应规格详细信息,并进行个数统计 条码库.xls 扫码.xlsx 一个条码对应多个规格名 ...