用python的pandas读取excel文件中的数据
一、读取Excel文件
使用pandas的read_excel()方法,可通过文件路径直接读取。注意到,在一个excel文件中有多个sheet,因此,对excel文件的读取实际上是读取指定文件、并同时指定sheet下的数据。可以一次读取一个sheet,也可以一次读取多个sheet,同时读取多个sheet时后续操作可能不够方便,因此建议一次性只读取一个sheet。
当只读取一个sheet时,返回的是DataFrame类型,这是一种表格数据类型,它清晰地展示出了数据的表格型结构。具体写法为:
(1)不指定sheet参数,默认读取第一个sheet,
df=pd.read_excel("data_test.xlsx")
(2)指定sheet名称读取,
df=pd.read_excel("data_test.xlsx",sheet_name="test1")
(3)指定sheet索引号读取,
df=pd.read_excel("data_test.xlsx",sheet_name=0) #sheet索引号从0开始
*同时读取多个sheet,以字典形式返回。(不推荐)
(1)指定多个sheet名称读取, df=pd.read_excel("data_test.xlsx",sheet_name=["test1","test2"])
(2)指定多个sheet索引号读取,
df=pd.read_excel("data_test.xlsx",sheet_name=[0,1])
(3)混合指定sheet名称和sheet索引号读取,
df=pd.read_excel("data_test.xlsx",sheet_name=[0,"test2"])
二、DataFrame对象的结构
对内容的读取分有表头和无表头两种方式,默认情形下是有表头的方式,即将第一行元素自动置为表头标签,其余内容为数据;当在read_excel()方法中加上header=None参数时是不加表头的方式,即从第一行起,全部内容为数据。读取到的Excel数据均构造成并返回DataFrame表格类型(以下以df表示)。
对有表头的方式,读取时将自动地将第一行元素置为表头向量,同时为除表头外的各行内容加入行索引(从0开始)、各列内容加入列索引(从0开始)。如图所示
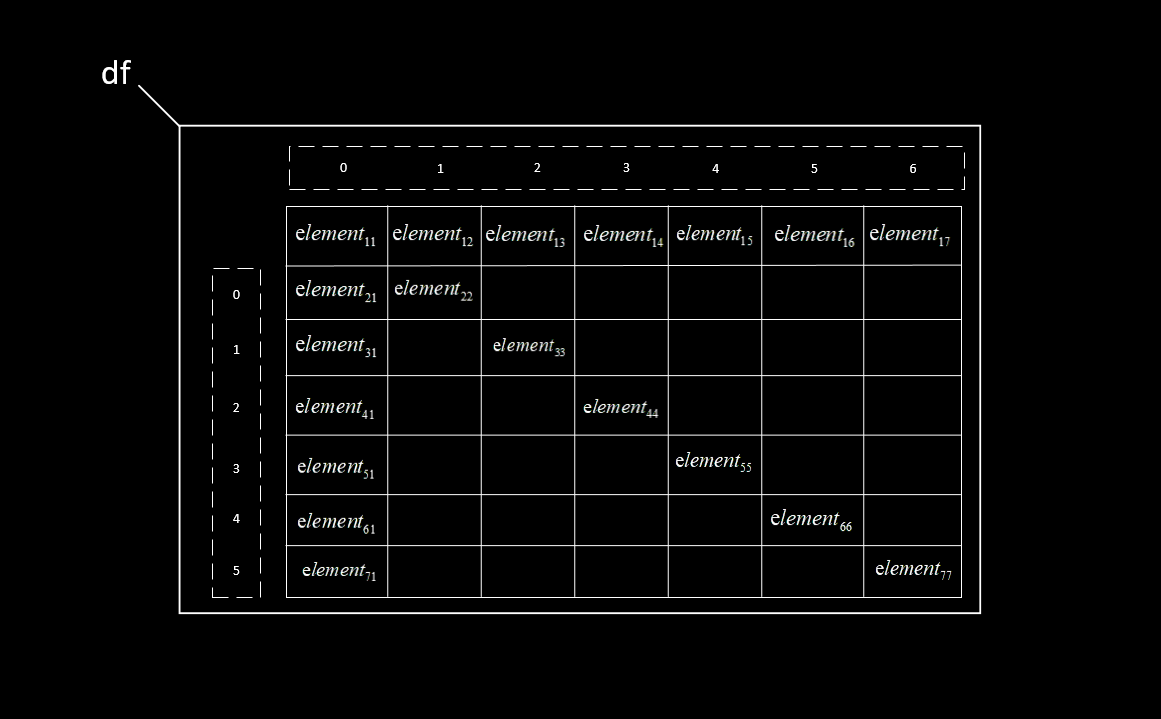
对无表头的方式,读取时将自动地为各行内容加入行索引(从0开始)、为各列内容加入列索引(从0开始),行索引从第一行开始。如图所示
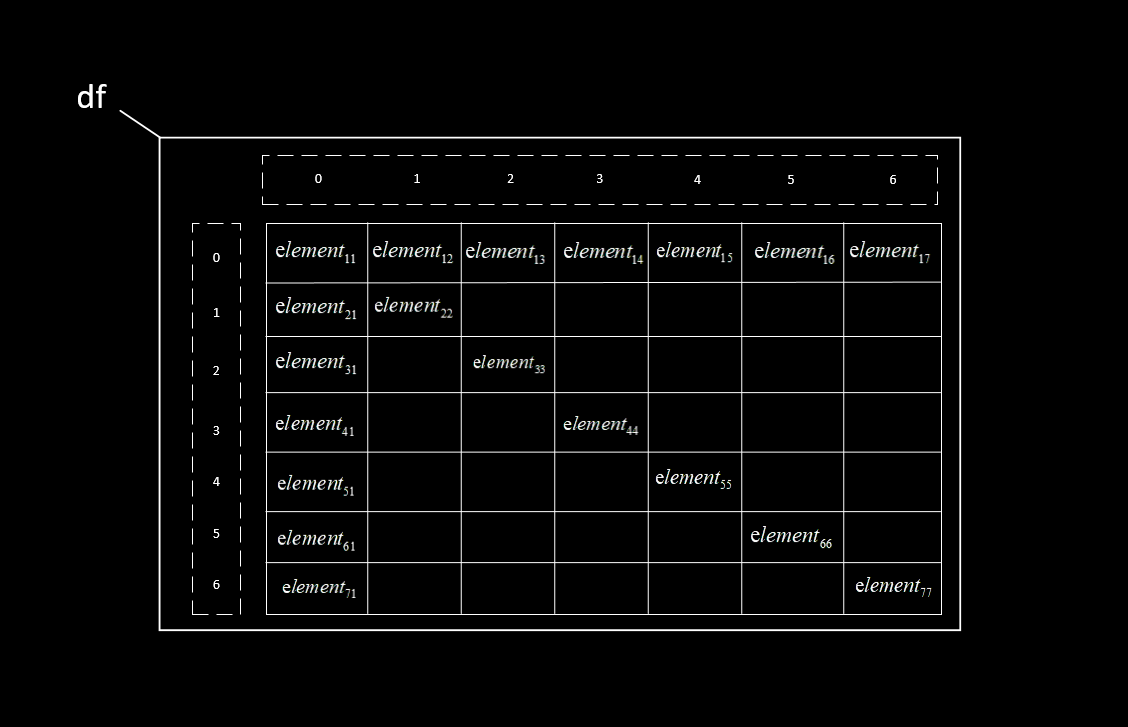
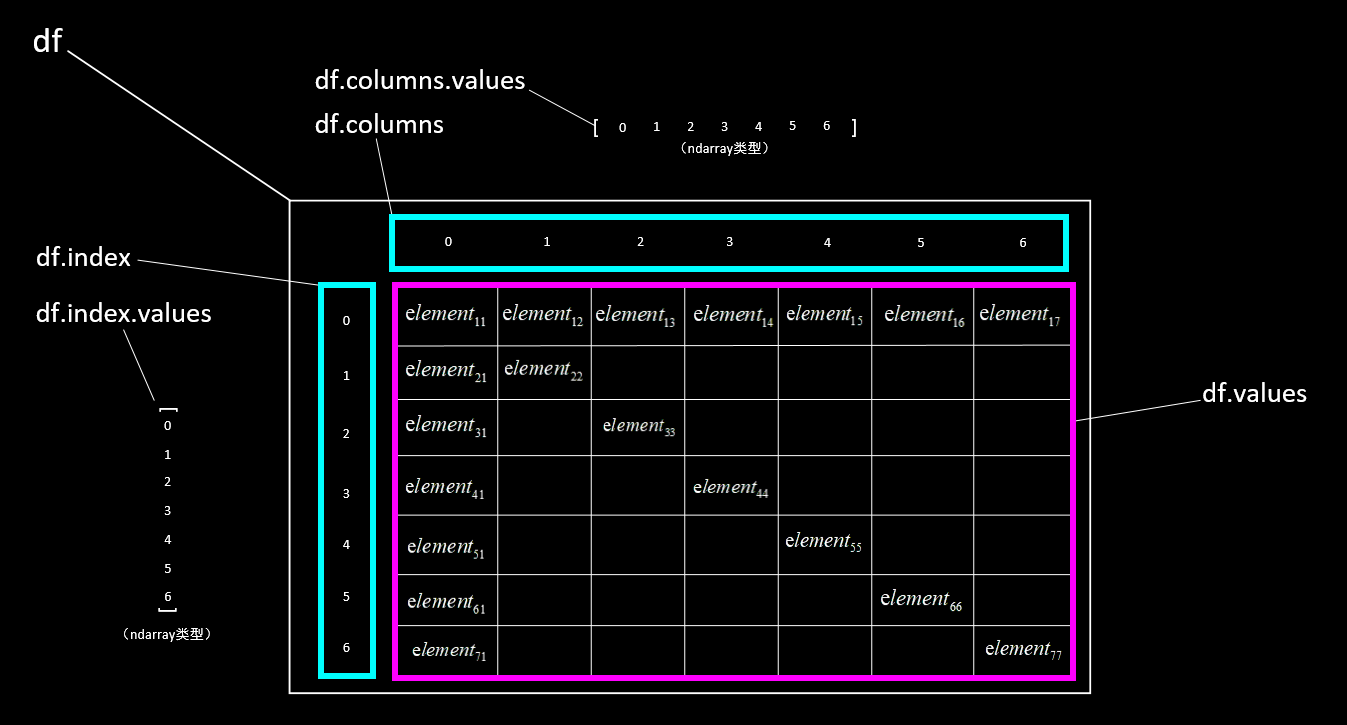
三、用values方式获取数据
1.基本方法
df.values,获取全部数据,返回类型为ndarray(二维);
df.index.values,获取行索引向量,返回类型为ndarray(一维);
df.columns.values,获取列索引向量(对有表头的方式,是表头标签向量),返回类型为ndarray(一维)。
根据具体需要,通过ndarray的使用规则获取指定数据。数据获取的结构示意图如下所示。
有表头

无表头
2.获取指定数据的写法
(1)获取全部数据:
df.values,获取全部数据,返回类型为ndarray(二维)。
(2)获取某个值:
df.values[i , j],第i行第j列的值,返回类型依内容而定。
(3)获取某一行:
df.values[i],第i行数据,返回类型为ndarray(一维)。
(4)获取多行:
df.values[[i1 , i2 , i3]],第i1、i2、i3行数据,返回类型为ndarray(二维)。
(5)获取某一列:
df.values[: , j],第j列数据,返回类型为ndarray(一维)。
(6)获取多列:
df.values[:,[j1,j2,j3]],第j1、j2、j3列数据,返回类型为ndarray(二维)。
(7)获取切片:
df.values[i1:i2 , j1:j2],返回行号[i1,i2)、列号[j1,j2)左闭右开区间内的数据,返回类型为ndarray(二维)。
3.示例
带表头,excel内容为
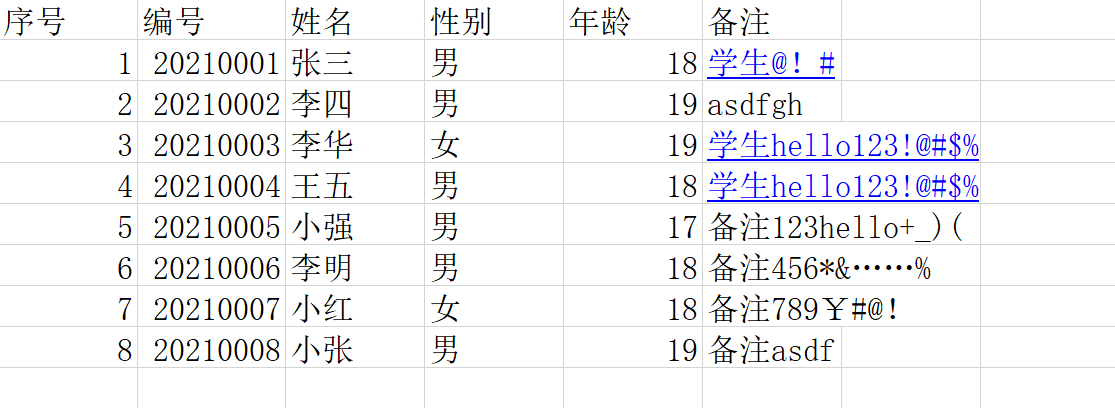
Python脚本为
`import pandas as pd
df = pd.read_excel("data_test.xlsx")
print("\n(1)全部数据:")
print(df.values)
print("\n(2)第2行第3列的值:")
print(df.values[1,2])
print("\n(3)第3行数据:")
print(df.values[2])
print("\n(4)获取第2、3行数据:")
print(df.values[[1,2]])
print("\n(5)第2列数据:")
print(df.values[:,1])
print("\n(6)第2、3列数据:")
print(df.values[:,[1,2]])
print("\n(7)第2至4行、第3至5列数据:")
print(df.values[1:4,2:5])
`
执行结果

四、用loc和iloc方式获取数据
1.基本写法
loc和iloc方法是通过索引定位的方式获取数据的,写法为loc[A, B]和iloc[A, B]。其中A表示对行的索引,B表示对列的索引,B可缺省。A、B可为列表或i1:i2(切片)的形式,表示多行或多列。
这两个方法的区别是,loc将参数当作标签处理,iloc将参数当作索引号处理。也就是说,在有表头的方式中,当列索引使用str标签时,只可用loc,当列索引使用索引号时,只可用iloc;在无表头的方式中,索引向量也是标签向量,loc和iloc均可使用;在切片中,loc是闭区间,iloc是半开区间。
获取指定数据的写法:
(1)获取全部数据:
df.loc[: , :].values
或
df.iloc[: , :].values,返回类型为ndarray(二维)。
(2)获取某个值:
无表头
df.loc[i, j]
或
df.iloc[i, j],第i行第j列的值,返回类型依内容而定。
有表头
df.loc[i, "序号"],第i行‘序号’列的值。
或
df.iloc[i, j],第i行第j列的值。
(3)获取某一行:
df.loc[i].values
或
df.iloc[i].values,第i行数据,返回类型为ndarray(一维)。
(4)获取多行:
df.loc[[i1, i2, i3]].values,
或
df.iloc[[i1, i2, i3]].values,第i1、i2、i3行数据,返回类型为ndarray(二维)。
(5)获取某一列:
无表头
df.loc[:, j].values
或
df.iloc[:, j].values,第j列数据,返回类型为ndarray(一维)。
有表头
df.loc[:,"姓名"].values,‘姓名’列数据,返回类型为ndarray(一维)。
或
df.iloc[:, j].values,第j列数据,返回类型为ndarray(一维)。
(6)获取多列:
无表头
df.loc[:, [j1 , j2]].values
或
df.iloc[:, [j1 , j2]].values,第j1、j2列数据,返回类型为ndarray(二维)。
有表头
df.loc[:, ["姓名","性别"]].values,‘姓名’、‘性别’列数据,返回类型为ndarray(二维);
df.iloc[:, [j1 , j2]].values,第j1、j2列数据,返回类型为ndarray(二维)。
(7)获取切片:
无表头
df.loc[i1:i2, j1:j2].values,返回行号[i1,i2]、列号[j1,j2]闭区间内的数据,返回类型为ndarray(二维);
df.iloc[i1:i2, j1:j2].values,返回行号[i1,i2)、列号[j1,j2)左闭右开区间内的数据,返回类型为ndarray(二维)。
有表头
df.loc[i1:i2, "序号":"姓名"].values,返回行号[i1,i2]、列号["序号","姓名"]闭区间的数据,返回类型为ndarray(二维);
df.iloc[i1:i2, j1:j2].values,返回行号[i1,i2)、列号[j1,j2)左闭右开区间内的数据,返回类型为ndarray(二维)。
2.示例
带表头,excel内容为

Python脚本为
`import pandas as pd
df = pd.read_excel("data_test.xlsx")
print("\n(1)全部数据:")
print(df.iloc[:,:].values)
print("\n(2)第2行第3列的值:")
print(df.iloc[1,2])
print("\n(3)第3行数据:")
print(df.iloc[2].values)
print("\n(4)第2列数据:")
print(df.iloc[:,1].values)
print("\n(5)第6行的姓名:")
print(df.loc[5,"姓名"])
print("\n(6)第2至3行、第3至4列数据:")
print(df.iloc[1:3,2:4].values)`
执行结果
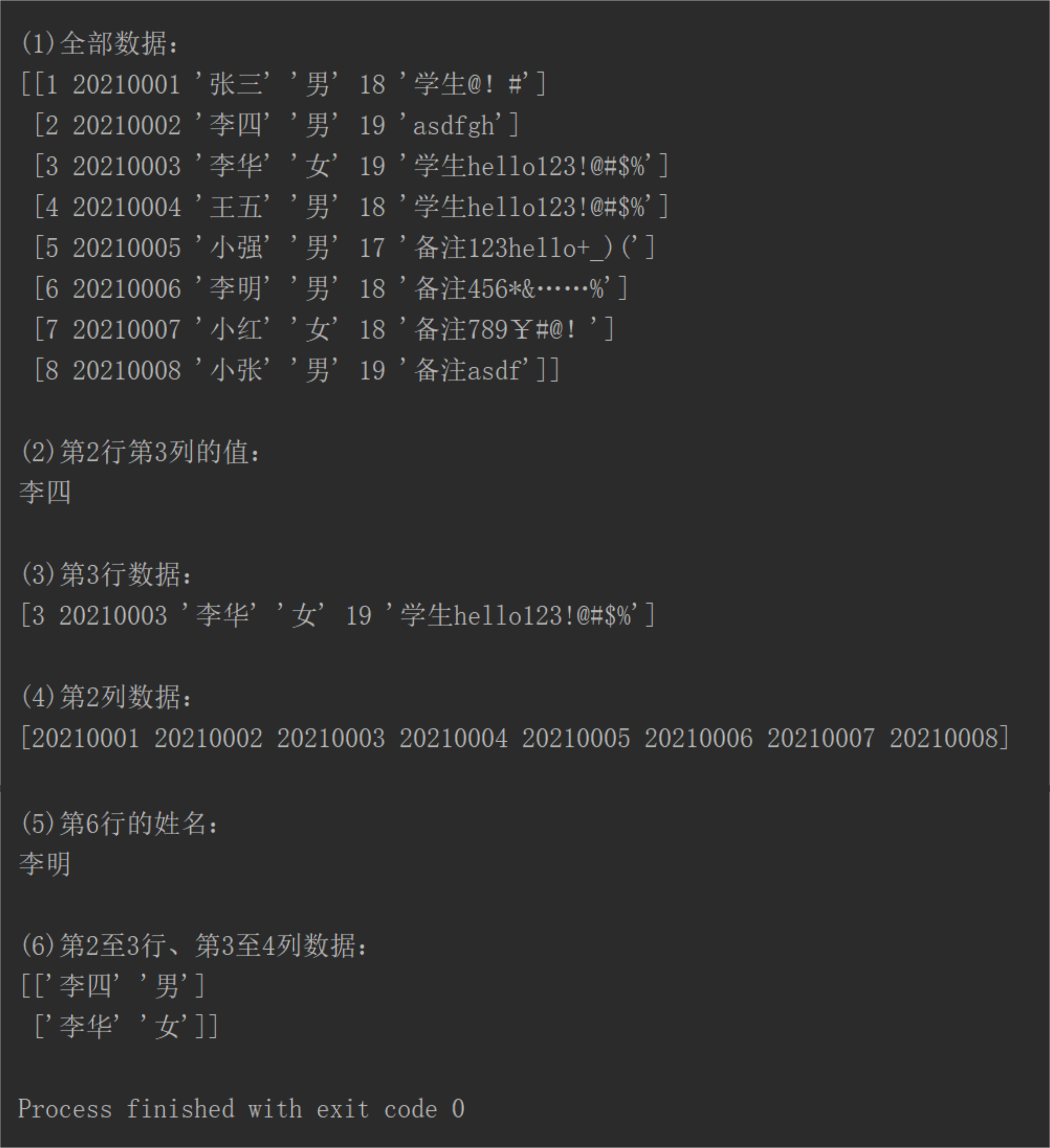
End.
用python的pandas读取excel文件中的数据的更多相关文章
- Python笔记(读取txt文件中的数据)
在机器学习中,常常需要读取txt文本中的数据,这里主要整理了两种读取数据的方式 数据内容 共有四列数据,前三列为特征值,最后一列为数据标签 40920 8.326976 0.953952 3 1448 ...
- matlab读取excel文件中的数据
1.读取sheet1中的所有数据 1.1首先我们建立一个sheet表,表名为‘111’ 1.2 默认这些文本以及数字都放在sheet1中,我们将此excel选入当前工作目录(必要步骤), 选入当前工作 ...
- Python xlrd模块读取Excel表中的数据
1.xlrd库的安装 直接使用pip工具进行安装(当然也可以使用pycharmIDE进行安装,这里就不详述了) pip install xlrd 2.xlrd模块的一些常用命令 ①打开excel文件并 ...
- gridview读取Excel文件中的数据,并将其导入数据库
原文发布时间为:2008-10-16 -- 来源于本人的百度文章 [由搬家工具导入] //将需要导入的文件上传到服务器 string filePath = "" ...
- [Python]将Excel文件中的数据导入MySQL
Github Link 需求 现有2000+文件夹,每个文件夹下有若干excel文件,现在要将这些excel文件中的数据导入mysql. 每个excel文件的第一行是无效数据. 除了excel文件中已 ...
- 用Python的pandas框架操作Excel文件中的数据教程
用Python的pandas框架操作Excel文件中的数据教程 本文的目的,是向您展示如何使用pandas 来执行一些常见的Excel任务.有些例子比较琐碎,但我觉得展示这些简单的东西与那些你可以在其 ...
- 读取Excel文件中的单元格的内容和颜色
怎样读取Excel文件中的单元格的内容和颜色 先创建一个Excel文件,在A1和A2中随意输入内容,设置A1的字体颜色为红色,A2的背景为黄色.需要 using Excel = Microsoft.O ...
- Java读取、写入、处理Excel文件中的数据(转载)
原文链接 在日常工作中,我们常常会进行文件读写操作,除去我们最常用的纯文本文件读写,更多时候我们需要对Excel中的数据进行读取操作,本文将介绍Excel读写的常用方法,希望对大家学习Java读写Ex ...
- 利用java反射机制实现读取excel表格中的数据
如果直接把excel表格中的数据导入数据库,首先应该将excel中的数据读取出来. 为了实现代码重用,所以使用了Object,而最终的结果是要获取一个list如List<User>.Lis ...
随机推荐
- python3.7安装和pycharm安装教程. 以及pycharm的破解教程
前言: 供对python初学者查阅, pycharm破解教程参阅了: https://blog.csdn.net/u014044812/article/details/78727496 1. 安装py ...
- 程序员被老板要求两个月做个APP,要不比京东差,网友:做一个快捷方式,直接链到京东
隔行如隔山,这句话说得一点都没错.做一个程序员,很多人都会羡慕,也有很多人会望而却步. 作为一个外行人,你别看程序员每天坐在电脑前敲敲键盘打打代码,以为很简单,其实啊也只有程序员自己明白,任何一个看似 ...
- mysql《一》
一.启动和停止服务器 通过管理员权限打开cmd命令指示符 通过 net stop mysql(自己的服务器名字) 停止服务器 通过 net start mysql(自己的服务器名字) 启动服务器 ...
- ElasticSearch进阶篇(一)--版本控制
一.前言 ElasticSearch(以下简称ES)的数据写入支持高并发,高并发就会带来很普遍的数据一致性问题.常见的解决方法就是加锁.同样,ES为了保证高并发写的数据一致性问题,加入了类似于锁的实现 ...
- const变量通过指针修改问题
const的变量在特定情况下可以通过指针修改,但是在另一些情况下是不能通过指针修改. 以下是VC6下才测试. 1. 不能修改的情况 #include int const a = 10; void ma ...
- putty编译过程
在Win7上用Visual Studio编译putty源代码. 安装vs2005,只安装c++和.net framework sdk即可: 将putty-src.zip解压到e:\MyDoc\VSPr ...
- MATLAB批量存储图像和显示算法处理的图像不留空白
一 前言 最近收到审稿人的修改意见,其中一条为<RC: There were only five images evaluated in the experiment, and I recomm ...
- 理解SpingAOP
目录 什么是AOP? AOP术语 通知(Advice) 连接点(Join point) 切点(Pointcut) 连接点和切点的区别 切面(Aspect) 引入(Introduction) 织入(We ...
- 一个系列搞懂YARN(1)——Yarn架构
前言 几天前和大哥说起了Yarn,大哥问我,你知道Yarn里面怎么进行资源的动态分配回收的吗?我和诚实,说不知道,然后就有了这个系列博文.不同版本的hadoop版本对应的yarn文档会有差别,本文中选 ...
- docker配置cdn-容器内可以通过域名访问
添加docker的cdn配置 # 没有这个文件创建 vim /etc/docker/daemon.json 添加内容如下 { "dns":["8.8.8.8", ...