Python爬Boss,找工作,快人一步!!!
通过职位搜索"Python开发",看下搜索的结果:
https://www.zhipin.com/job_detail/?query=python开发&city=101020100&industry=&position=
按F12,使用开发者工具查看下html的结构:
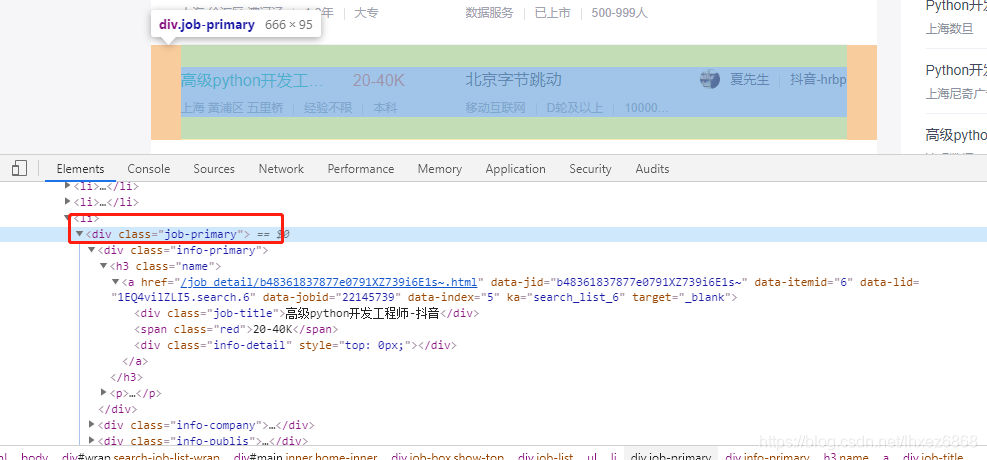
先获取所有的class="job-primary"的div列表,然后遍历列表对象,在子查询里面的各个需要的信息。
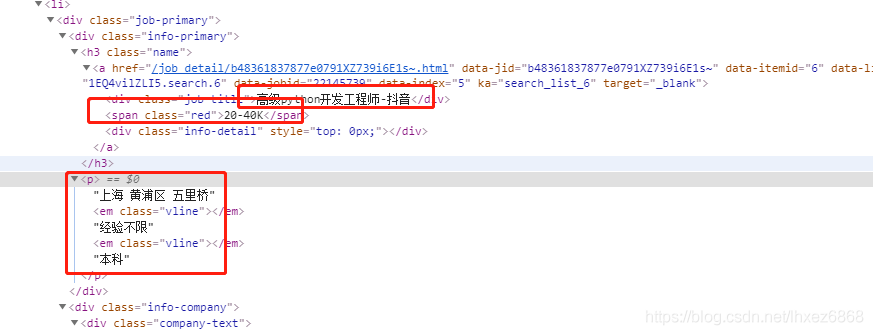
职位需求信息如下:
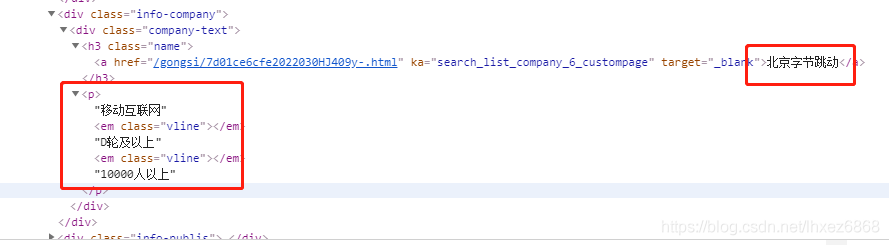
公司信息:
先创建数据库,保存爬取的信息
create table boss_job(
jid varchar(50) primary key,
name varchar(50) not null,
sal varchar(20),
addr varchar(50),
work_year varchar(20),
edu varchar(20),
company varchar(40),
company_type varchar(20),
company_staff varchar(20),
url varchar(200)
)engine=innodb default charset=utf-8
boss直聘需要带上cookies,不然无法正常返回,会访问到一个请稍后的页面。
爬取库使用BeautifulSoup4。
#-*- coding: UTF-8 -*-
import requests,pymysql
from bs4 import BeautifulSoup def get_one_page_info(kw,page):
'''获取第page的数据,搜索关键字kw'''
url="https://www.zhipin.com/c101020100/?query="+kw+"&page="+str(page)+"&ka=page-"+str(page)
cookies={
"lastCity":"101020100",
"_uab_collina":"156594127160811552815566",
"sid":"sem_pz_bdpc_dasou_title",
"__c":"1566178735",
"__g":"sem_pz_bdpc_dasou_title",
"__l":"l=%2Fwww.zhipin.com%2F%3Fsid%3Dsem_pz_bdpc_dasou_title&r=https%3A%2F%2Fsp0.baidu.com%2F9q9JcDHa2gU2pMbgoY3K%2Fadrc.php%3Ft%3D06KL00c00fDIFkY0IWPB0KZEgsA_ON-I00000Kd7ZNC00000Irp6hc.THdBULP1doZA80K85yF9pywdpAqVuNqsusK15yRLPH6zuW-9nj04nhRLuhR0IHYYn1mzwW9AwHIawWmdrRN7P1-7fHN7wjK7nRNDfW6Lf6K95gTqFhdWpyfqn1czPjmsPjnYrausThqbpyfqnHm0uHdCIZwsT1CEQLILIz4lpA-spy38mvqVQ1q1pyfqTvNVgLKlgvFbTAPxuA71ULNxIA-YUAR0mLFW5Hfsrj6v%26tpl%3Dtpl_11534_19713_15764%26l%3D1511867677%26attach%3Dlocation%253D%2526linkName%253D%2525E6%2525A0%252587%2525E5%252587%252586%2525E5%2525A4%2525B4%2525E9%252583%2525A8-%2525E6%2525A0%252587%2525E9%2525A2%252598-%2525E4%2525B8%2525BB%2525E6%2525A0%252587%2525E9%2525A2%252598%2526linkText%253DBoss%2525E7%25259B%2525B4%2525E8%252581%252598%2525E2%252580%252594%2525E2%252580%252594%2525E6%252589%2525BE%2525E5%2525B7%2525A5%2525E4%2525BD%25259C%2525EF%2525BC%25258C%2525E6%252588%252591%2525E8%2525A6%252581%2525E8%2525B7%25259F%2525E8%252580%252581%2525E6%25259D%2525BF%2525E8%2525B0%252588%2525EF%2525BC%252581%2526xp%253Did(%252522m3224604348_canvas%252522)%25252FDIV%25255B1%25255D%25252FDIV%25255B1%25255D%25252FDIV%25255B1%25255D%25252FDIV%25255B1%25255D%25252FDIV%25255B1%25255D%25252FH2%25255B1%25255D%25252FA%25255B1%25255D%2526linkType%253D%2526checksum%253D8%26wd%3Dboss%25E7%259B%25B4%25E8%2581%2598%26issp%3D1%26f%3D8%26ie%3Dutf-8%26rqlang%3Dcn%26tn%3Dbaiduhome_pg%26sug%3Dboss%2525E7%25259B%2525B4%2525E8%252581%252598%2525E5%2525AE%252598%2525E7%2525BD%252591%26inputT%3D4829&g=%2Fwww.zhipin.com%2F%3Fsid%3Dsem_pz_bdpc_dasou_title",
"Hm_lvt_194df3105ad7148dcf2b98a91b5e727a":"1565941272,1566178735",
"__zp_stoken__":"c839%2FbUp4y%2FcG59Q1lQU84czePIXK3dDRi%2F3AGRWQ6KVQWUNKQa4lxpn2jAVyXKDRxk0g3H19loBTLIK4KtUfLuxbQ%3D%3D",
"__a":"74852898.1565941271.1565941271.1566178735.32.2.3.3",
"Hm_lpvt_194df3105ad7148dcf2b98a91b5e727a":"1566178748",
}
headers={
"user-agent":"Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/76.0.3809.100 Safari/537.36",
"referer":"https://www.zhipin.com/c101020100/?query=python%E5%BC%80%E5%8F%91&page=1&ka=page-1"
}
r= requests.get(url,headers=headers,cookies=cookies)
soup=BeautifulSoup(r.text,"lxml")
# 先获取每一行的列表数据
all_jobs=soup.select("div.job-primary")
infos=[]
for job in all_jobs:
jnama=job.find("div",attrs={"class":"job-title"}).text
jurl="https://www.zhipin.com"+job.find("div",attrs={"class":"info-primary"}).h3.a.attrs['href']
jid=job.find("div",attrs={"class":"info-primary"}).h3.a.attrs['data-jid']
sal=job.find("div",attrs={"class":"info-primary"}).h3.a.span.text
info_contents=job.find("div",attrs={"class":"info-primary"}).p.contents
addr=info_contents[0]
# 有的工作年薪是没有的,有的是有四个的需要更具contents子节点的个数去判断
# <p>上海 静安区 汶水路<em class="vline"></em>4天/周<em class="vline"></em>6个月<em class="vline"></em>大专</p>
# contents里面包含着文本和em标签
# print(info_contents)
# ['上海 嘉定区 安亭', <em class="vline"></em>, '3-5年', <em class="vline"></em>, '大专']
if len(info_contents)==3:
work_year = "无数据"
edu = job.find("div", attrs={"class": "info-primary"}).p.contents[2]
elif len(info_contents)==5:
work_year=job.find("div",attrs={"class":"info-primary"}).p.contents[2]
edu=job.find("div",attrs={"class":"info-primary"}).p.contents[4]
elif len(info_contents)==7:
work_year = job.find("div", attrs={"class": "info-primary"}).p.contents[-3]
edu = job.find("div", attrs={"class": "info-primary"}).p.contents[-1]
company=job.find("div",attrs={"class":"company-text"}).h3.a.text
company_type=job.find("div",attrs={"class":"company-text"}).p.contents[0]
company_staff=job.find("div",attrs={"class":"company-text"}).p.contents[-1]
print(jid,jnama,jurl,sal,addr,work_year,edu,company,company_type,company_staff)
infos.append({
"jid":jid,
"name":jnama,
"sal":sal,
"addr":addr,
"work_year":work_year,
"edu":edu,
"company":company,
"company_type":company_type,
"company_staff":company_staff,
"url":jurl})
print("%s职位信息,第%d页抓取完成"%(kw,page))
return infos
def save_mysql(infos):
'''保存每一页的数据到数据库中'''
db = pymysql.connect("localhost","root","123456","ai11",charset="utf8")
cursor = db.cursor()
for job in infos:
sql = "insert into boss_job values('%(jid)s','%(name)s','%(sal)s','%(addr)s','%(work_year)s'\
,'%(edu)s','%(company)s','%(company_type)s','%(company_staff)s','%(url)s');"%(job)
try:
cursor.execute(sql)
except pymysql.Error as e:
print("数据库出错",e)
db.rollback()
else:
db.commit() for i in range(1,11):
infos=get_one_page_info("python开发",i)
save_mysql(infos)
结尾:欢迎加入我们一起学习
最后,拿起你的小手机,点赞收藏,加扣群,里面有更多更好玩的资料源码分享。
正所谓,来者都是客,咳咳,不对,是你有一块钱,我有一块钱,我们合在一起就是两块钱,知识,是可以互相交流的^_^

Python爬Boss,找工作,快人一步!!!的更多相关文章
- 教你用python爬虫监控教务系统,查成绩快人一步!
教你用python爬虫监控教务系统,查成绩快人一步!这几天考了大大小小几门课,教务系统又没有成绩通知功能,为了急切想知道自己挂了多少门,于是我写下这个脚本. 设计思路:设计思路很简单,首先对已有的成绩 ...
- 让大蛇(Python)帮你找工作
前段时间用Python实现了一个网络爬虫(让大蛇(Python)帮你找工作),效率总体还可以,但是缺点就是每次都需要手动的去触发,于是打算对该爬虫加上Timer,经过网上一番搜索以及API的查询,发现 ...
- 云上领跑,快人一步:华为云抢先发布Redis5.0
12月17日,华为云在DCS2.0的基础上,快人一步,抢先推出了新的Redis 5.0产品,这是一个崭新的突破.目前国内在缓存领域的发展普遍停留在Redis4.0阶段,华为云率先发布了Redis5.0 ...
- 浅谈C# .Net技术面试 , 正在找工作的人一定要看看
1.引子 最近一直在负责.net(B/S方向)技术面试相关的工作,前前后后面试了不少人,但是通过率较低,大概只有20%左右:有颇多感慨. 最近也一直比较困惑,原因究竟是什么? 是我们要求太高,应聘者本 ...
- python学习快人一步,从19个语法开始!
Python简单易学,但又博大精深.许多人号称精通Python,却不会写Pythonic的代码,对很多常用包的使用也并不熟悉.学海无涯,我们先来了解一些Python中最基本的内容. Python的特点 ...
- 让大蛇(Python)帮你找工作 之增强版
前一段时间用Python写了个简单的网络爬虫,可以从某个求职网站上根据预先设置的条件一次性的爬取所有的职位信息,最近对该程序进行了一下完善,主要包括如下内容 (1)可以对爬取的结果再进行筛选 例如,你 ...
- Android P的APP适配总结,让你快人一步
欢迎大家前往腾讯云+社区,获取更多腾讯海量技术实践干货哦~ 本文由QQ音乐技术团队发表于云+社区专栏 上篇:Android P 行为变更适配 Android P 这次有很多行为变更,其中不乏一些需要亟 ...
- 【微信小程序推广营销】教你微信小程序SEO优化,让你的小程序快人一步抢占先机
今年一月份上线的小程序,经过近一年的沉淀发酵,现在也进入了快速发展期. 在未来肯定会有越来越多的小程序诞生,小程序多了就需要搜索,那么如何让自己的小程序在众多的小程序中脱颖而出,这就需要小程序SEO优 ...
- 合宙Luat直播间即将开启,你揭开行业奥秘,让你快人一步。
嗨~刚陪你们过儿童节 和你们一起成长的合宙Luat 又有新计划 -- 合宙Luat官方直播即将开启 - 敬请关注 - - 官方直播什么内容 - 可能是合宙研发动态 可能是新品发布资讯 可能是行业大咖分 ...
随机推荐
- MySQL数据库安装,MySQL数据库库的增删改查,表的增删改查,表数据的基本数据类型
一 MySQL的安装 MySQL现在属于甲骨文公司,所以和java语言匹配度较高,同时甲骨文公司的另一种数据库为Oracle,两者同为关系型数据库,即采用关系模型来组织数据,以行和列的方法来存储数据的 ...
- 小程序的优化代码的分析Promise方法
代码优化,这里通过了wx.request请求轮播图的API,通过result结果里面的data数据我们可以看到massage里面装着我们的数据 通过图片可以用看到swiperList返回的三个元素的数 ...
- 使用halo搭建自己的博客并配置https域名访问
首先进行java配置 # 1. 下载jdk [下载地址](https://www.oracle.com/cn/java/technologies/javase-downloads.html) - 一定 ...
- 在Linux使用虚拟环境
定义 “虚拟环境”,是python解释器的一个私有副本.在这个环境中,你可以安装私有包,而且不会影响系统中安装的全局python解释器. 作用 为每个程序单独创建虚拟环境时,可以保证程序只能访问虚拟环 ...
- IOS 崩溃原因统计 2014-07-12 10:13
注意: 1,释放自己的autorelease对象,app会crash: 2,释放系统的autorelease对象,app会crash: 第一种 情况有现象如下: 声明一个 对象 A* obj:把o ...
- Oracle 多条数据转一行逗号隔开
wm_concat 例: select wm_concat(市) from pa50 where apa132=省
- 剑指offer数组中重复的数字
package 数组; /*在一个长度为n的数组里的所有数字都在0到n-1的范围内. 数组中某些数字是重复的,但不知道有几个数字是重复的. 也不知道每个数字重复几次.请找出数组中任意一个重复的数字. ...
- linux下的scp传输文件
转载于:http://moyu2010.blog.163.com/blog/static/177439041201112710243064/,再次谢谢作者. 1.功能说明scp就是security c ...
- vscode下终端返回中文乱码
用python写个爬虫,配置个VScode环境,发现输出都是乱码,翻阅网站后发现一个简单有效的方法,在此谢过网络上的大牛们的无私分享,我也在此记录一下,以备后用: 文件---->首选项----& ...
- openvswitch 流表测试 ovs-appctl
[root@ostack170 ~]# ovs-appctl ofproto/trace br-mirror in_port=,dl_vlan=,dl_src=:ea:cb:5d:e4:ee,dl_d ...