python_mmdt:一种基于敏感哈希生成特征向量的python库(一)
概述
python_mmdt是一种基于敏感哈希的特征向量生成工具。核心算法使用C实现,提高程序执行效率。同时使用python进行封装,方便研究人员使用。
本篇幅主要介绍涉及的相关基本内容与使用,相关内容的详细说明,后续另开篇幅探讨。
项目地址:python_mmdt
重点内容
本篇重点内容,包括三个方面:
- 对象归一化:数据的重采样
- 局部敏感哈希函数的定义:特征向量的生成
- 特征向量的应用:距离计算、相似度计算、分类、聚类
重点假设
- 数据的重采样方法无条件适用于研究对象,且重采样的过程部分了保留原始数据的差异性与相似性
- 重采样之后的单个数据点(随机变量)是满足独立同分布的
- N取值很大时,敏感哈希函数值分布近似于正态分布,则落在指定区间内的局部敏感哈希值是有效的
基本过程
1. 数据重采样
我们的研究对象常常是不同的文件格式,不同的文件大小,如何方便的处理这类格式不同,大小不一的文件呢?方法有很多种,这里我们使用采样的方法。
采样原始定义:
采样是将信号从连续时间域上的模拟信号转换到离散时间域上的离散信号的过程。
下采样定义:
对于一个样值序列间隔几个样值取样一次,这样得到新序列就是原序列的下采样。
通过重采样(本工具中特指下采样),我们让对象数据都处于相同的维度(大小)。这样,就可以比较方便地定义我们自己的局部敏感哈希函数。
python_mmdt使用Lanczos下采样方法。
2. 局部敏感哈希函数
局部敏感哈希的基本概念
局部敏感哈希(Locality Sensitive Hashing,LSH)的基本思想类似于一种空间域转换思想,LSH算法基于一个假设,如果两个文本在原有的数据空间是相似的,那么分别经过哈希函数转换以后的它们也具有很高的相似度;相反,如果它们本身是不相似的,那么经过转换后它们应仍不具有相似性。
通过重采样之后的数据,我们假设其满足独立同分布。同时,我们将重采样的数据,平均分成N块,每块之间的数据进行累计求和,和值分布近似服从正态分布,我们取和值高x位的一个byte做为本块数据的敏感哈希值。
例如:
51030000:D6E26822530202020202020202020202:51030000是4字节索引敏感哈希,D6E26822530202020202020202020202是16字节敏感哈希4F454750:A4B58A07235B23F13B2F244A9B8A547B:4F454750是4字节索引敏感哈希,A4B58A07235B23F13B2F244A9B8A547B是16字节敏感哈希
3. 特征向量的应用
1. 简单应用
简单应用如,索引敏感哈希可以转成一个int32的数字,当索引敏感哈希相等时,再比较敏感哈希的距离(如曼哈顿距离,将敏感哈希转成N个unsigned char类型计算敏感哈希,此时00和FF之间的距离可算作1,也可算作255,具体看实现)。
2. 复杂应用
由于特征向量的维度是固定的,因此可以很方便的使用其他数学方法,进行大规模计算。
- 如结合矩阵运算,快速得到上万特征向量(样本)的相似度矩阵,
- 如用于机器学习的分类(KNN)、聚类(Kmeans)等
安装
依赖
cmake: 2.6及以上版本windows: 当前版本(0.1.3)安装需要配置minGW编译C代码
pip安装
$ pip install python_mmdt
通过whl包安装(免编译)
.whl从github_release或者pypi下载编译好的二进制包安装
$ pip install python_mmdt-xxx.whl
使用
命令行
安装之后,可以通过命令行,快速计算敏感hash或比较两个文件相似度
# calculate mmdt sensitive
$ mmdt-hash $file_path
# calculate file similarity
$ mmdt-compare $file_path1 $file_path2
python code
用作python库,导入编码使用
# -*- coding: utf-8 -*-
import unittest
import os
from python_mmdt.mmdt.mmdt import MMDT
class Testmmdt(unittest.TestCase):
def test_process(self):
mmdt = MMDT()
test_path = os.path.dirname(__file__)
test_samples = os.path.join(test_path, "samples")
files = os.listdir(test_samples)
for f in files:
file_path = os.path.join(test_samples, f)
r1 = mmdt.mmdt_hash(file_path)
print(r1)
r2 = mmdt.mmdt_hash_streaming(file_path)
print(r2)
sim1 = mmdt.mmdt_compare(file_path, file_path)
print(sim1)
sim2 = mmdt.mmdt_compare_hash(r1, r2)
print(sim2)
示例
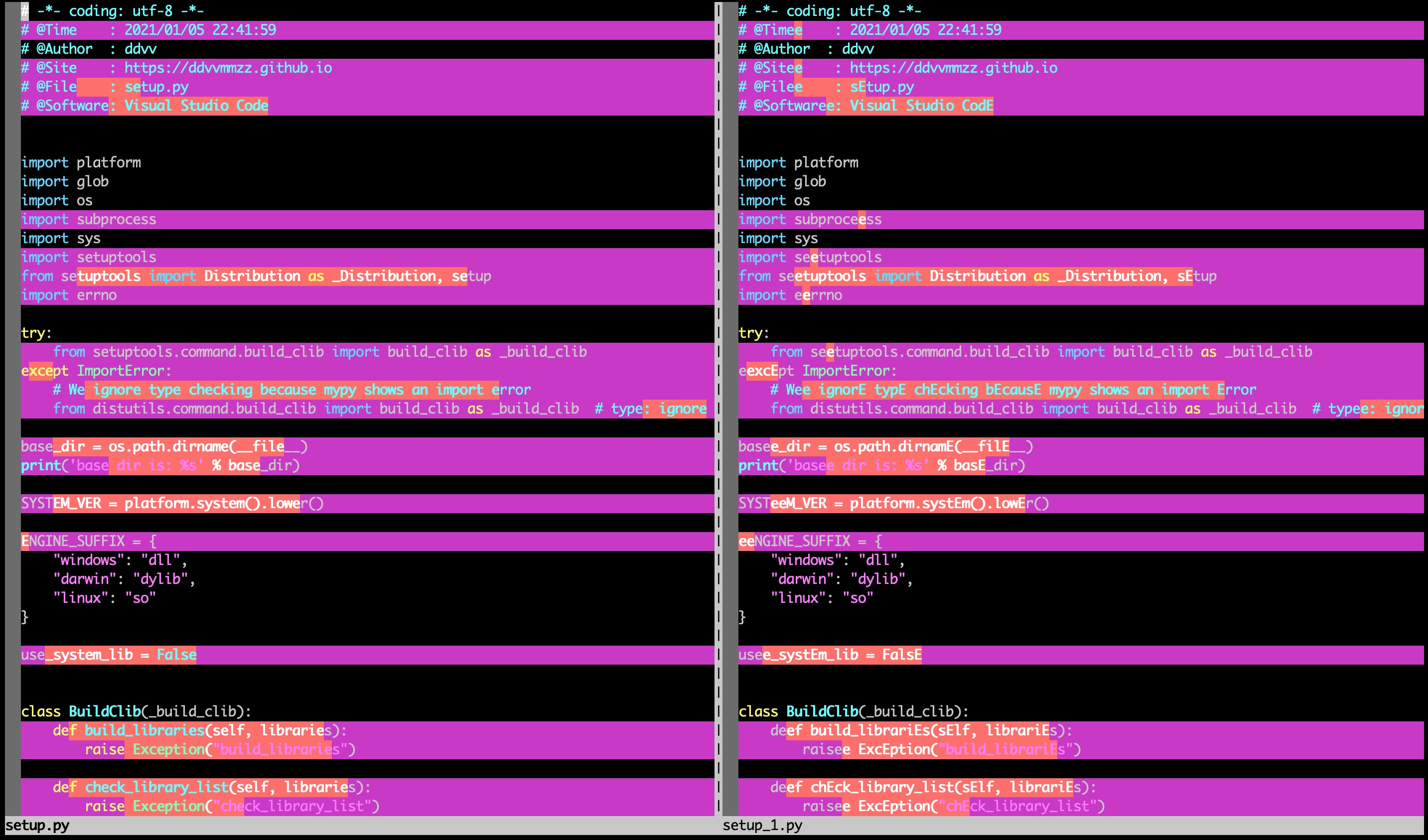
拷贝一份当前项目的setup.py,命名为setup_1.py。
setup_1.py进行两种变换:
- 使用大写字母
E全局替换小写字母e - 使用
ee全局替换大写字母E
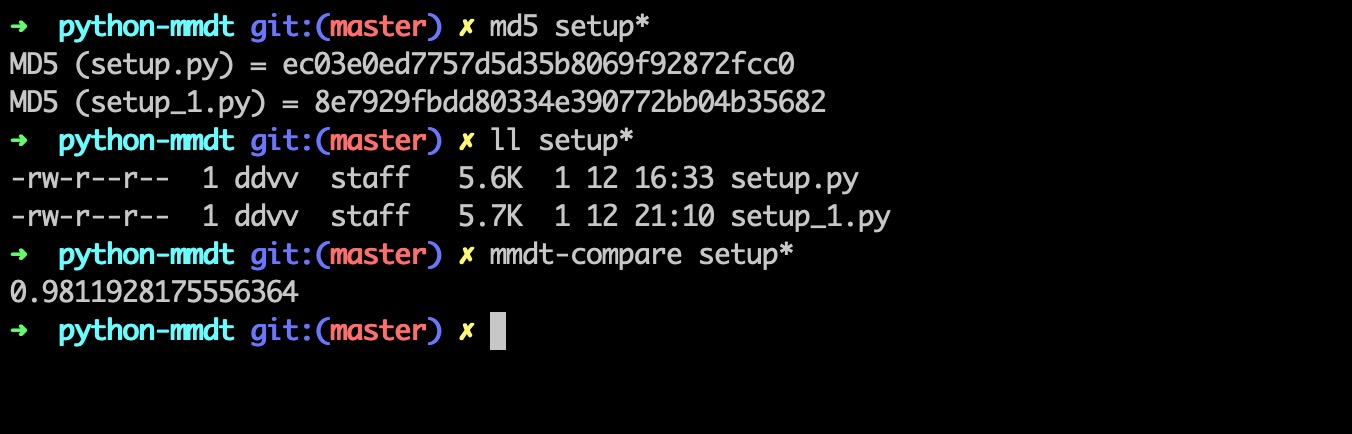
计算mmdt_hash等于0.9811928175556364。
vim对比图如:
md5、文件大小、mmdt_hash信息图如:
其他
由于敏感哈希采用累计求和的方式,和值近似服从正态分布,所以由此计算出来的相似度,绝大部分会分布在u值附近区间内。在这块区间内的相似度,其实价值很低的。相反的,在这个区间外的,如正态分布的两侧数据,价值就很高了。相似度越高的表示真的越相似,相似度越低的表示真的越不相似。而落在中间取值范围,价值就小很多。
如比较项目中的setup.py和LICENSE,相似度0.62左右,但价值不大:

python_mmdt:一种基于敏感哈希生成特征向量的python库(一)的更多相关文章
- 基于局部敏感哈希的协同过滤算法之simHash算法
搜集了快一个月的资料,虽然不完全懂,但还是先慢慢写着吧,说不定就有思路了呢. 开源的最大好处是会让作者对脏乱臭的代码有羞耻感. 当一个做推荐系统的部门开始重视[数据清理,数据标柱,效果评测,数据统计, ...
- 大规模异常滥用检测:基于局部敏感哈希算法——来自Uber Engineering的实践
uber全球用户每天会产生500万条行程,保证数据的准确性至关重要.如果所有的数据都得到有效利用,t通过元数据和聚合的数据可以快速检测平台上的滥用行为,如垃圾邮件.虚假账户和付款欺诈等.放大正确的数据 ...
- [Algorithm] 局部敏感哈希算法(Locality Sensitive Hashing)
局部敏感哈希(Locality Sensitive Hashing,LSH)算法是我在前一段时间找工作时接触到的一种衡量文本相似度的算法.局部敏感哈希是近似最近邻搜索算法中最流行的一种,它有坚实的理论 ...
- 局部敏感哈希-Locality Sensitive Hashing
局部敏感哈希 转载请注明http://blog.csdn.net/stdcoutzyx/article/details/44456679 在检索技术中,索引一直须要研究的核心技术.当下,索引技术主要分 ...
- 局部敏感哈希(Locality-Sensitive Hashing, LSH)方法介绍
局部敏感哈希(Locality-Sensitive Hashing, LSH)方法介绍 本文主要介绍一种用于海量高维数据的近似近期邻高速查找技术--局部敏感哈希(Locality-Sensitive ...
- R语言实现︱局部敏感哈希算法(LSH)解决文本机械相似性的问题(二,textreuse介绍)
每每以为攀得众山小,可.每每又切实来到起点,大牛们,缓缓脚步来俺笔记葩分享一下吧,please~ --------------------------- 上一篇(R语言实现︱局部敏感哈希算法(LSH) ...
- 局部敏感哈希(Locality-Sensitive Hashing, LSH)
本文主要介绍一种用于海量高维数据的近似最近邻快速查找技术——局部敏感哈希(Locality-Sensitive Hashing, LSH),内容包括了LSH的原理.LSH哈希函数集.以及LSH的一些参 ...
- 局部敏感哈希-Locality Sensitivity Hashing
一. 近邻搜索 从这里开始我将会对LSH进行一番长篇大论.因为这只是一篇博文,并不是论文.我觉得一篇好的博文是尽可能让人看懂,它对语言的要求并没有像论文那么严格,因此它可以有更强的表现力. 局部敏感哈 ...
- 局部敏感哈希(Locality-Sensitive Hashing, LSH)方法介绍(转)
局部敏感哈希(Locality-Sensitive Hashing, LSH)方法介绍 本文主要介绍一种用于海量高维数据的近似最近邻快速查找技术——局部敏感哈希(Locality-Sensitive ...
随机推荐
- 仵航说 前后端分离,文件上传下载(springBoot+vue+elementUI)仵老大
1.介绍 本文主要是介绍前后端分离的上传下载,后端使用的是SpringBoot,持久层用的是mybatis-plus,前端用的Vue,UI用的elementUI,测试了一下,文本,图片,excel ...
- 工具-Git与GitHub-安装以及基本操作(99.5.1)
@ 目录 1.安装 2.使用 3.工作区和版本库 关于作者 1.安装 1.windows安装 安装后添加环境变量 2.linux安装 sudo apt-get install git 2.使用 1.常 ...
- 关于 ReentrantLock 中锁 lock() 和解锁 unlock() 的底层原理浅析
关于 ReentrantLock 中锁 lock() 和解锁 unlock() 的底层原理浅析 如下代码,当我们在使用 ReentrantLock 进行加锁和解锁时,底层到底是如何帮助我们进行控制的啦 ...
- 项目1_001_涉及知识点(Django任务追踪平台)
- UICamera 编辑器与移动设备下的Find异常
某次出包后,在移动设备下,发现所有的UIDrag和一些UIHUD组件都失效了,看了看Editor下是正常的,后面就做了一系列检查措施来排除问题所在. 1.看了下log日志里是否有相关报错异常,结果毫无 ...
- easyui获取table列表中所有数据组装成json格式发送到后台
jsp代码 var rows =$('#findAllRolestable').datagrid('getSelections'); var result = JSON.stringify(rows) ...
- easyui中刷新列表
<table class="crud-content-info" id="showProductDialogFormstandrad"> </ ...
- vue3系列:vue3.0自定义弹框组件V3Popup|vue3.x手机端弹框组件
基于Vue3.0开发的轻量级手机端弹框组件V3Popup. 之前有分享一个vue2.x移动端弹框组件,今天给大家带来的是Vue3实现自定义弹框组件. V3Popup 基于vue3.x实现的移动端弹出框 ...
- 高性能MySQL学习总结二----常见数据类型选择及优化
一.数据类型的选择 MySQL的数据类型有很多种,选择正确的数据类型对于获得高性能特别地重要,如何选择合适的数据类型呢?主要遵从以下三个原则: 1.更小的通常情况下性能更好 一般情况下,应该尽量使用可 ...
- Spring Boot 自动配置之@Conditional的使用
Spring Boot自动配置的"魔法"是如何实现的? 转自-https://sylvanassun.github.io/2018/01/08/2018-01-08-spring_ ...