gpfdist原理解析
gpfdist原理解析
前言:gpfdist作为批量向postgresql写入数据的工具,了解其内部原理有助于正确使用以及提供更合适的数据同步方案。文章先简要介绍gpfdist的整体流程,然后针对重要步骤详细展开。文章有的地方可能探索不够深入,感兴趣的可以继续深入。如有错误请指出。
1 整体流程
Gpfdist的整体流程可简单分为4步。
(1) 解析参数;
(2) 从指定的端口列表中搜寻可用端口;
(3) 监听第一个可用端口;
(4) 注册该端口的可读事件,等待连接请求;
(5) 响应各类事件。
下面通过源码及注释详细介绍上述过程。
int main(int argc, const char* const argv[])
{
if (gpfdist_init(argc, argv) == -1)
gfatal(NULL, "Initialization failed");
return gpfdist_run();
}
Main函数很简短,调用了gpfdist_init与gpfdist_run,其中gpfdist_run比较简单,源码如下,仅仅调用了libevent的事件分发函数,以回调形式响应各类事件(主要是socket读写事件)。
int gpfdist_run()
{
return event_dispatch();
}
gpfdist_init比较复杂,完成了libevent的初始化、事件绑定、http服务启动等功能,源码如下。其中apr是Apache的可移植运行库,在该项目中主要用于资源管理,不影响理解gpfdist原理,这里不再介绍,有兴趣的可参考https://apr.apache.org/。
int gpfdist_init(int argc, const char* const argv[])
{
/*初始化apr资源池*/
if (0 != apr_app_initialize(&argc, &argv, 0))
gfatal(NULL, "apr_app_initialize failed");
atexit(apr_terminate);
if (0 != apr_pool_create(&gcb.pool, 0))
gfatal(NULL, "apr_app_initialize failed");
//apr_signal_init(gcb.pool);
gcb.session.tab = apr_hash_make(gcb.pool);
//解析命令行参数
parse_command_line(argc, argv, gcb.pool);
......
event_init();
signal_register();
//启动http服务
http_setup();
.....
gpfdist_init通过调用http_setup函数完成http服务的启动,http_setup源码如下,主要功能是测试哪些端口可以使用。
http_setup(void)
{
SOCKET f;
int on = 1;
struct linger linger;
struct addrinfo hints;
struct addrinfo *addrs, *rp;
int s;
int i;
char service[32];
const char *hostaddr = NULL;
//绑定gpfdist的文件读写函数,用于从文件或其他方式读写数据
gpfdist_send = gpfdist_socket_send;
gpfdist_receive = gpfdist_socket_receive;
......
/* 下面的内容就是从指定端口列表中测试哪些端口可用*/
for (;;)
{
//利用第一个端口组成socket使用的网络地址
snprintf(service,32,"%d",opt.p);
memset(&hints, 0, sizeof(struct addrinfo));
hints.ai_family = AF_UNSPEC; /* Allow IPv4 or IPv6 */
hints.ai_socktype = SOCK_STREAM; /* tcp socket */
hints.ai_flags = AI_PASSIVE; /* For wildcard IP address */
hints.ai_protocol = 0; /* Any protocol */
s = getaddrinfo(hostaddr, service, &hints, &addrs);
.......
/*
* 测试地址是否可用,这个for循环只会执行一次,因为rp->ai_next=0
*/
for (rp = addrs; rp != NULL; rp = rp->ai_next)
{
gprint(NULL, "Trying to open listening socket:\n");
print_listening_address(rp);
/*
* getaddrinfo gives us all the parameters for the socket() call
* as well as the parameters for the bind() call.
*/
f = socket(rp->ai_family, rp->ai_socktype, rp->ai_protocol);
//设置keep_alive linger等属性
......
if (bind(f, rp->ai_addr, rp->ai_addrlen) != 0)
{
......
}
/* listen with a big queue */
if (listen(f, opt.z))
{
......
}
gcb.listen_socks[gcb.listen_sock_count++] = f;
gprint(NULL, "Opening listening socket succeeded\n");
}
......
}
/*
* 为上述可用端口绑定可读事件响应函数do_accept,用于接收客户端的连接。
*/
for (i = 0; i < gcb.listen_sock_count; i++)
{
/* when this socket is ready, do accept */
event_set(&gcb.listen_events[i], gcb.listen_socks[i], EV_READ | EV_PERSIST,
do_accept, 0);
......
if (event_add(&gcb.listen_events[i], 0))
gfatal(NULL, "cannot set up event on listen socket: %s",
strerror(errno));
}
}
自此http服务已经建立起来,并准备好接收postgresql segment的连接。
2 核心数据结构间的联系
接下来说明一下gpfdist中的几个核心数据结构及其之间的关系,便于对下文代码逻辑关系的理解。
session_t是一次会话,由成员key唯一标识,key = tid:path,tid = xid.cid.sn,其中xid是事务id,cid是查询命令id,每次查询时属于同一个sql的segment请求的xid、cid相同,但由于各segment请求的path可能不同,因此同一个查询的不同segment请求可能属于不同session。另外注意tid长度不能超过1023字节。
request_t代表一个segment的请求,因此session_t对应多个request_t。
fstream_t代表属于同一session_t的request_t想要请求的数据流,其成员glob_and_copy_t包含多个文件地址,fstream_t会顺序读取这些文件回应给segment。
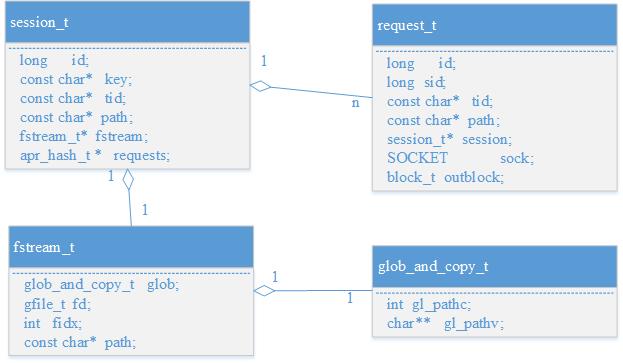
图1 核心数据结构
3 接受连接
http服务接收到客户端连接后由do_accept函数响应,该函数首先接收客户端连接,并给该连接设置非阻塞等属性,接着创建request_t对象并初始化其部分属性,最后调用setup_read函数为该连接绑定读事件响应函数do_read_request,到此gpfdist已经与客户端建立了连接并开始等待客户端的http请求。
static void do_accept(int fd, short event, void* arg)
{
address_t a;
socklen_t len = sizeof(a);
SOCKET sock;
request_t* r;
apr_pool_t* pool;
int on = 1;
struct linger linger;
/* do the accept */
if ((sock = accept(fd, (struct sockaddr*) &a, &len)) < 0)
{
gwarning(NULL, "accept failed");
goto failure;
}
/* set to non-blocking, and close-on-exec */
......
/* set keepalive, reuseaddr, and linger */
......
/* create a pool container for this socket */
......
/* 调用setup_read为上述socket设置读事件响应函数do_read_request */
if (setup_read(r))
{
http_error(r, FDIST_INTERNAL_ERROR, "internal error");
request_end(r, 1, 0);
}
return;
}
接收请求后的处理
如图2,gpfdist接收到http请求后解析出相关参数,包含tid、cid、文件路径等信息,然后绑定到对应session上,根据请求类型分别调用不同函数完成对segment的响应。下面着重讲解路径提取、session绑定两个操作的细节。
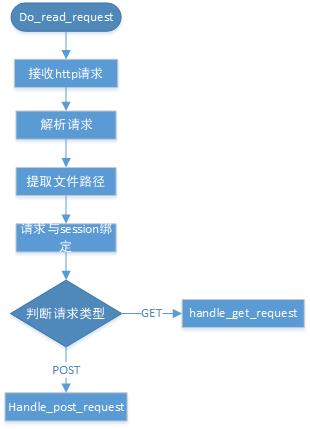
图2 接收请求
(1)路径提取
segment请求中路径参数格式如下所示:
1.csv空格t*.csv
(注意:该串不能含有相对路径”..”)
gpfdist会遍历该字符串,以空格为分隔符提取所有文件路径,并在每个路径前拼接上gpfdist启动时命令行输入的目录,最终得到如下路径:
/home/test/data/1.csv 空格/home/test/data/t*.csv
转换后的路径将用于后面的文件读取或写入操作。
(2)session与连接绑定
接收到segment的http请求后需要将其与session绑定,流程如图3。首先根据请求的key查找对应的session是否存在,存在则请求与session绑定,否则就新建并初始化fstream_t与session对象。

图3 绑定session
新建fstream_t时会重新组织文件路径并检查是否有操作权限。首先把上文转换后的路径以空格分开,然后将每一个路径中包含的通配符解析成具体的文件名,得到如下的路径列表(这里假设目录下存在t1.csv t2.csv):
/home/test/data/1.csv
/home/test/data/t1.csv
/home/test/data/t2.csv
然后尝试打开上述文件以测试是否有操作权限。
4 GET请求
如果segment是GET请求, 对应的socket会被设置可写事件响应函数do_write,其流程如图4:

图4 发送数据
在读取一个数据块时,gpfdist采用整行读取方式,即每次回应的业务数据一定是源文件的完整若干行,目前gpfdist对于csv文件仅支持\n \r \r\n 三种行分隔符,但可通过修改scan_csv_records_crlf函数支持其他类型的行分隔符,另外csv文件允许数据中含有行分隔符;对于text格式的文件,行分隔只支持\n。
gpfdist会将本次读取到的数据的元信息填充到回应头部,包含本次回应的业务数据的长度、行数、文件名、在文件中的偏移等信息。
5 POST请求
图5是gpfdist对post请求(写请求)的处理流程,不再详细展开。
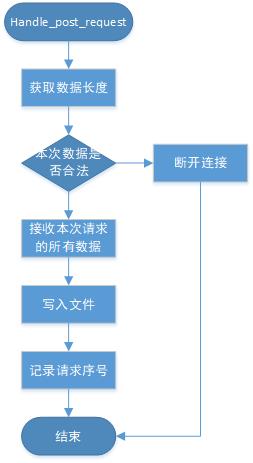
图5 数据写入文件
6 外表文件个数与segment数量的关系
在此只针对文件形式的读外表进行分析,读外表的创建语句如下:
create external table test ( id integer, name varchar ) location (‘gpfdist://$IP:$PORT/$file_name’[,..]) format ‘csv’(delimiter’,’) ;
从以上语句可以看出,外表可以配置多个文件,但应注意配置的文件数量与segment存在以下关系:
(1) 只有一个文件(通配符计为一个文件)
每个segment都会请求该文件的数据,当数据量小时,有的segment可能获取不到数据,这不会对表的读取造成任何影响。
(2) 配置两个以上文件
- 文件数量 < segment数量
postgresql会给每个segment分配一个文件进行读取。
- 文件数量 > segment
gpfdist报错,读表失败。
gpfdist原理解析的更多相关文章
- [原][Docker]特性与原理解析
Docker特性与原理解析 文章假设你已经熟悉了Docker的基本命令和基本知识 首先看看Docker提供了哪些特性: 交互式Shell:Docker可以分配一个虚拟终端并关联到任何容器的标准输入上, ...
- 【算法】(查找你附近的人) GeoHash核心原理解析及代码实现
本文地址 原文地址 分享提纲: 0. 引子 1. 感性认识GeoHash 2. GeoHash算法的步骤 3. GeoHash Base32编码长度与精度 4. GeoHash算法 5. 使用注意点( ...
- Web APi之过滤器执行过程原理解析【二】(十一)
前言 上一节我们详细讲解了过滤器的创建过程以及粗略的介绍了五种过滤器,用此五种过滤器对实现对执行Action方法各个时期的拦截非常重要.这一节我们简单将讲述在Action方法上.控制器上.全局上以及授 ...
- Web APi之过滤器创建过程原理解析【一】(十)
前言 Web API的简单流程就是从请求到执行到Action并最终作出响应,但是在这个过程有一把[筛子],那就是过滤器Filter,在从请求到Action这整个流程中使用Filter来进行相应的处理从 ...
- GeoHash原理解析
GeoHash 核心原理解析 引子 一提到索引,大家脑子里马上浮现出B树索引,因为大量的数据库(如MySQL.oracle.PostgreSQL等)都在使用B树.B树索引本质上是对索引字段 ...
- alibaba-dexposed 原理解析
alibaba-dexposed 原理解析 使用参考地址: http://blog.csdn.net/qxs965266509/article/details/49821413 原理参考地址: htt ...
- 支付宝Andfix 原理解析
支付宝Andfix 原理解析 使用参考地址: http://blog.csdn.net/qxs965266509/article/details/49802429 原理参考地址: http://blo ...
- JavaScript 模板引擎实现原理解析
1.入门实例 首先我们来看一个简单模板: <script type="template" id="template"> <h2> < ...
- Request 接收参数乱码原理解析三:实例分析
通过前面两篇<Request 接收参数乱码原理解析一:服务器端解码原理>和<Request 接收参数乱码原理解析二:浏览器端编码原理>,了解了服务器和浏览器编码解码的原理,接下 ...
随机推荐
- git仓库更换远程地址
首先进入项目所在文件夹,右键git bash (1)查看当前的远程地址 git remote -v (2)删除当前的远程地址 git remote rm origin (3)添加远程地址 git re ...
- ucosIII学习笔记——钩子函数
一开始听见钩子函数感觉很莫名其妙,更不知道它有何作用,这是第一篇博客,也是学习ucosIII操作系统的一个开始吧. 在系统中有开发者自己创建的任务也有系统内部任务 ,UCOSIII中有五个系统任务,分 ...
- VS中使用TreeView的Checked属性问题
VS中使用TreeView,当需要用到Checked属性,并需要同步子节点和父节点的Checked属性时,若使用AfterCheck事件会导致死循环,这里我使用的是NodeMouseClick事件.代 ...
- C++中函数的形式参数引用
形式参数的传递方式 值传递 值传递是将数值传递到程序中,这种方式传递是单向传递 但是如果想要双向传递,这种视频无法满足: 引用传递 引用传递可以实现双向的传递 为了对比处两个之间的差异,这里举出两个例 ...
- MYSQL查询和插入数据的流程是怎样的
一个查询语句经过哪些步骤 这次我们从MySQL的整体架构来讲SQL的执行过程,如下图: 在整体分为两部分Server和引擎层,这里引擎层我使用InnoDB去代替,引擎层的设计是插件形式的,可以任意替代 ...
- Gradle & Java
Gradle & Java Gradle Build Tool I Modern Open Source Build Automation https://gradle.org/ https: ...
- codepen iframe theme id
codepen iframe theme id iframe css theme demos See the Pen css margin collapsing (1. 相邻兄弟元素) by xgqf ...
- SVG 与 Canvas 对比
SVG 与 Canvas 对比 技术选型 SVG vs Canvas 应用场景 性能 GPU 加速 XML 数据存储 Canvas 2D Canvas 3D WebGL / OpenGL ES thr ...
- LeetCode & list cycle
LeetCode & list cycle 链表是否存在环检测 singly-linked list 单链表 "use strict"; /** * * @author x ...
- git merge all in one
git merge all in one you can follow below steps 1. merge origin/master branch to feature branch # st ...