隐马尔科夫模型(HMM)原理详解
隐马尔可夫模型(Hidden Markov Model,HMM)是可用于标注问题的统计学习模型,描述由隐藏的马尔可夫链随机生成观测序列的过程,属于生成模型。HMM在语音识别、自然语言处理、生物信息、模式识别等领域都有着广泛的应用。
一、 HMM模型的定义
HMM模型是关于时序的概率模型,描述由一个隐藏的马尔可夫链随机生成不可观测的状态随机序列,再由各个状态生成一个观测而产生观测随机序列的过程。隐藏的马尔可夫链随机生成的状态的序列称为状态序列(state sequence);每个状态生成一个观测,再由此产生的观测的随机序列,称为观测序列(observation sequence。序列的每一个位置可以看作是一个时刻。
HMM模型由初始概率分布、状态转移概率分布、观测概率分布确定。设$Q$是所有可能的状态的集合,$V$是所有可能的观测的集合,即:
$Q=\left\{q_{1}, q_{2}, \cdots, q_{N}\right\}, \quad V=\left\{v_{1}, v_{2}, \cdots, v_{M}\right\}$
其中,$N$是可能的状态数,$M$是可能的观测数。记$I$是长度为$T$的状态序列,$O$是对应的观测序列,即:
$I=\left(i_{1}, i_{2}, \cdots, i_{T}\right), \quad O=\left(o_{1}, o_{2}, \cdots, o_{T}\right)$
记$A$为状态转移概率矩阵:
$A=\left[a_{i j}\right]_{N \times N}$
其中,$a_{i j}=P\left(i_{t+1}=q_{j} | i_{t}=q_{i}\right), \quad i=1,2, \cdots, N ; j=1,2, \cdots, N$,即在时刻$t$处于状态$q_{i}$的条件下在时刻$t+1$转移到状态$q_{j}$的概率。
记$B$观测概率矩阵:
$B=\left[b_{j}(k)\right]_{N \times \mu}$
其中,$b_{j}(k)=P\left(o_{t}=v_{k} | i_{t}=q_{j}\right), \quad k=1,2, \cdots, M ; j=1,2, \cdots, N$,$N$是在时刻$t$处于状态$q_{j}$的条件下生成观测$v_{k}$的概率。
记$\pi $为初始状态概率向量:
$\pi=\left(\pi_{i}\right)$
其中,$\pi_{i}=P\left(i_{1}=q_{i}\right), \quad i=1,2, \cdots, N$,表示时刻$t=1$处于状态$q_{i}$的概率。
因此,HMM模型$\lambda$可以用三元符号表示,即:
$\lambda=(A, B, \pi)$
$A, B, \pi$称为HMM模型的三要素。
举例说明
假设有4个盒子,每个盒子都有红白两种颜色的球,球的数量如下:
盒子 1 2 3 4
红球数 5 3 6 8
白球数 5 7 4 2 按下面的方法抽取球:
开始时,从4个盒子中等概率地抽取一个,再从盒子中随机抽一个球,记录颜色后放回。然后从当前盒子转移到下一个盒子,如果当前为盒子1,下一个盒子一定是2;如果当前为盒子2或3,以概率0.4和0.6转移到左边或右边的盒子;如果当前为盒子4,各以0.5概率停留在盒子4或转移到盒子3。转移后,再从盒子中随机抽一个球,记录颜色后放回。
现在假设我们要连续地抽5次。抽取结果如下:
$O$=( 红 , 红 , 白 , 白 , 红 )
这个例子中有两个随机序列:
盒子序列(状态序列)和球颜色序列(观测序列)。前者是隐藏的,后者是可观测的。
则状态集合$Q$和观测集合$V$为:
$Q$=(盒子1,盒子2,盒子3,盒子4), $V$=(红,白)
状态序列和观测序列长度T=5。
开始时,从4个盒子中等概率地抽取一个,则初始概率分布$\pi $为:
$\pi=(0.25,0.25,0.25,0.25)^{\mathrm{T}}$
状态转移概率分布$A$为(由盒子转移规则得出):
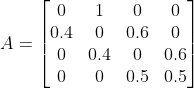
观测概率分布$B$为(由每个盒子红白球比例计算得出):
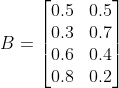
二、两个基本假设和三个基本问题
隐马尔可夫模型做了两个基本假设:
- 齐次马尔可夫性假设,即假设隐藏的马尔可夫链在任意时刻t的状态只依赖于其前一时刻的状态,与其他时刻的状态及观测无关,也与时刻t无关,即:
$P\left(i_{t} | i_{t-1}, o_{t-1}, \cdots, i_{1}, o_{1}\right)=P\left(i_{t} | i_{t-1}\right), \quad t=1,2, \cdots, T$ - 观测独立性假设,即假设任意时刻的观测只依赖于该时刻的马尔可夫链的状态,与其他的观测和状态无关,即:
$P\left(o_{t} | i_{T}, o_{T}, i_{T-1}, o_{T-1}, \cdots, i_{t+1}, o_{t+1}, i_{t-1}, i_{t-1}, \cdots, i_{1}, o_{1}\right)=P\left(o_{t} | i_{t}\right)$
隐马尔可夫模型有3个基本问题:
1、概率计算问题 给定模型λ和观测序列$O$,计算在模型$\lambda $下观测序列$O$出现的慨率$P(O\mid \lambda)$。
2、学习问题 已知观测序列$O$,估计模型$\lambda $的参数,使得在该模型下观测序列概率$P(O\mid \lambda)$最大。即用极大似然估计的方法估计参数。
3、预测问题,也称为解码问题 已知模型λ和观测序列$O$,求对给定观测序列条件概率$P(I\mid O)$最大的状态序列。即给定观测序列,求最有可能的对应的状态序列。
三、概率计算问题:概率计算方法
概率计算即给定模型$\lambda=(A, B, \pi)$和观测序列$O=\left(o_{1}, o_{2}, \cdots, o_{T}\right)$,计算在模型$\lambda $下,观测序列$o$出现的概率$P(O | \lambda)$。
3.1 直接计算法
直接计算法是通过列举所有可能的长度为$T$的状态序列$I=\left(i_{1}, i_{2}, \cdots, i_{T}\right)$,求各个状态序列I II和观测序列$O=\left(o_{1}, o_{2}, \cdots, o_{T}\right)$的联合概率$P(O, I | \lambda)$,然后对所有可能的状态序列求和,得到$P(O | \lambda)$。
状态序列$I=\left(i_{1}, i_{2}, \cdots, i_{T}\right)$的概率为:
$P(I | \lambda)=\pi_{i_{1}} a_{i_{1} i_{2}} a_{i_{2} i_{3}} \cdots a_{i_{T-1} i_{T}}$
对固定的状态序列$I=\left(i_{1}, i_{2}, \cdots, i_{T}\right)$,观测序列$O=\left(o_{1}, o_{2}, \cdots, o_{T}\right)$的概率为$P(O | I, \lambda)$:
$P(O | I, \lambda)=b_{i_{1}}\left(o_{1}\right) b_{i_{2}}\left(o_{2}\right) \cdots b_{i_{T}}\left(o_{T}\right)$
$O$和$I$同时出现的l联合概率为:

对所有可能的状态序列$I$求和,得到观测序列$O$的概率$P(O | \lambda)$,即:

但是,通过这种计算方式的计算量非常大,其复杂度为$O\left(T N^{r}\right)$,因此是不可行的。在真实情况下,一般采用更有效的算法,即前向-后向算法。
3.2 前向算法
前向概率:给定隐马尔可夫模型$\lambda$,定义到时刻$t$部分观测序列为$o_{1}, o_{2}, \cdots, o_{t}$且状态为$q_{i}$的概率为前向概率,记作:
$\alpha_{t}(i)=P\left(o_{1}, o_{2}, \cdots, o_{t}, i_{t}=q_{i} | \lambda\right)$
观测序列概率的前向算法:
1、输入:隐马尔可夫模型$\lambda $,观测序列$O$;
2、输出:观测序列概率$P(O | \lambda)$
3、初值:
$\alpha_{1}(i)=\pi_{i} b_{i}\left(o_{1}\right), \quad i=1,2, \cdots, N$
4、递推:对$t=1,2, \cdots, T-1$,
$\alpha_{t+1}(i)=\left[\sum_{j=1}^{N} \alpha_{t}(j) a_{j i}\right] b_{i}\left(o_{t+1}\right), \quad i=1,2, \cdots, N$
5、终止:
$P(O | \lambda)=\sum_{i=1}^{N} \alpha_{T}(i)$
前向算法之所以可以提高HMM的观测序列概率计算速度,是因为在每一个时刻计算时,都可以直接引用上一个时刻的计算结果,因此,其时间复杂度是$O(\left(N^{2} T\right)$,比直接计算法小很多。
3.3 后向算法
后向概率:给定隐马尔可夫模型$\lambda$,定义在时刻$t$状态为$q_{i}$的条件下,从t+1到T的部分观测序列为$o_{t+1}, o_{t+2}, \cdots, o_{T}$的概率为后向概率,记作
$\beta_{t}(i)=P\left(o_{t+1}, o_{t+2}, \cdots, o_{T} | i_{t}=q_{i}, \lambda\right)$
观测序列概率的后向算法:
1、输入:隐马尔可夫模型$\lambda $,观测序列$O$;
2、输出:观测序列概率$P(O | \lambda)$
3、初值:
$\beta_{T}(i)=1, \quad i=1,2, \cdots, N$
4、递推:对$t=T-1, T-2, \cdots, 1$,
$\beta_{t}(i)=\sum_{j=1}^{N} a_{i j} b_{j}\left(o_{t+1}\right) \beta_{t+1}(j), \quad i=1,2, \cdots, N$
5、终止:$P(O | \lambda)=\sum_{i=1}^{N} \pi_{i} b_{i}\left(o_{1}\right) \beta_{1}(i)$
根据前向概率和后向概率的定义,可以将观测序列概率$P(O | \lambda)$统一写成:
$P(O | \lambda)=\sum_{i=1}^{N} \sum_{j=1}^{N} \alpha_{t}(i) a_{i j} b_{j}\left(o_{t+1}\right) \beta_{t+1}(j), \quad t=1,2, \cdots, T-1$
3.4 一些概率值与期望的计算
给定模型$\lambda$和观测O,在时刻t处于状态$q_{i}$的概率,记:
$\gamma_{t}(i)=P\left(i_{t}=q_{i} | O, \lambda\right)=\frac{P\left(i_{t}=q_{i}, O | \lambda\right)}{P(O | \lambda)}$
由前向概率和后向概率的定义可知:
$\alpha_{t}(i) \beta_{t}(i)=P\left(i_{t}=q_{i}, O | \lambda\right)$
因此有:
$\gamma_{t}(i)=\frac{\alpha_{t}(i) \beta_{t}(i)}{P(O | \lambda)}=\frac{\alpha_{t}(i) \beta_{t}(i)}{\sum_{j=1}^{N} \alpha_{t}(j) \beta_{t}(j)}$
给定模型$\lambda$和观测O,在时刻t处于状态$q_{i}$且在时刻t+1处于状态$q_{j}$的概率,记为:
$\xi_{t}(i, j)=P\left(i_{t}=q_{i}, i_{t+1}=q_{j} | O, \lambda\right)$
可以通过前向后向概率计算:
$\xi_{i}(i, j)=\frac{P\left(i_{t}=q_{i}, i_{t+1}=q_{j}, O | \lambda\right)}{P(O | \lambda)}=\frac{P\left(i_{t}=q_{i}, i_{t+1}=q_{j}, O | \lambda\right)}{\sum_{i=1}^{N} \sum_{j=1}^{N} P\left(i_{t}=q_{i}, i_{t+1}=q_{j}, O | \lambda\right)}$
而
$P\left(i_{t}=q_{i}, i_{t+1}=q_{j}, O | \lambda\right)=\alpha_{t}(i) a_{i j} b_{j}\left(o_{t+1}\right) \beta_{t+1}(j)$
因此有
$\xi_{t}(i, j)=\frac{\alpha_{t}(i) a_{i j} b_{j}\left(o_{t+1}\right) \beta_{t+1}(j)}{\sum_{i=1}^{N} \sum_{j=1}^{N} \alpha_{t}(i) a_{i j} b_{j}\left(o_{t+1}\right) \beta_{t+1}(j)}$
四、学习算法
HMM的学习算法是指对模型的参数$\pi$、A、B进行估计,一般根据训练数据是包括观测序列和对应的状态序列还是只包括观测序列,可以分别由监督学习和非监督学习实现。
4.1 监督学习方法
假设已给训练数据集包含S个长度相同的观测序列和对应的状态序列$\left\{\left(O_{1}, I_{1}\right),\left(O_{2}, I_{2}\right), \cdots,\left(O_{s}, I_{s}\right)\right\}$,那么可以利用极大似然估计法来估计隐马尔可夫模型的参数。具体的方法如下:
1、转移概率$a_{i j}$的估计:设样本中时刻t处于状态i ii时刻t+1转移到状态j的频数为$A_{i j}$,那么状态转移概率$a_{i j}$的估计是:
$\hat{a}_{i j}=\frac{A_{y}}{\sum_{j=1}^{N} A_{i j}}, \quad i=1,2, \cdots, N ; j=1,2, \cdots, N$
2、观测概率$b_{j}(k)$的估计:设样本中状态为$jb$并观测为k的频数是$B_{j k}$,那么状态为j观测为k的概率$b_{j}(k)$的估计为:
$\hat{b}_{j}(k)=\frac{B_{j k}}{\sum_{k=1}^{M} B_{j k}}, \quad j=1,2, \cdots, N_{i} \quad k=1,2, \cdots, M$
3、初始状态概率$\pi_{i}$的估计:$\hat{\pi}_{i}$为S个样本中初始状态为$q_{i}$的频率。
4.2 非监督学习方法——Baum-Welch算法
由于监督学习需要大量的标注数据,需要耗费很多的人力物力,因此,有时会采用非监督学习方法来进行参数估计。假设给定训练数据集只包含S个长度为T的观测序列$\left\{O_{1}, O_{2}, \cdots, O_{s}\right\}$而没有对应的状态序列,我们将观测序列看作观测数据O,而状态序列看作不可观测的隐数据I,这样一来,HMM模型就可以看作是一个含有隐变量的概率模型:
$P(O | \lambda)=\sum_{I} P(O | I, \lambda) P(I | \lambda)$
因此,可以采用EM算法来进行参数估计。
1、确定完全数据的对数似然函数:所有观测数据写成$O=\left(o_{1}, o_{2}, \cdots, o_{T}\right)$,所有隐数据写成$I=\left(i_{1}, i_{2}, \cdots, i_{T}\right)$,完全数据为$ (O, I)=\left(o_{1}, o_{2}, \cdots, o_{T}, i_{1}, i_{2}, \cdots, i_{T}\right)$,完全数据的对数似然函数是$\log P(O, I | \lambda)$。
2、E步:求Q函数
$Q(\lambda, \overline{\lambda})=\sum_{I} \log P(O, I | \lambda) P(O, I | \overline{\lambda})$
其中,$\overline{\lambda}$是HMM模型参数的当前估计值,$\lambda$是要极大化的HMM模型参数。
因此,Q函数可以写为:
3、M步:分别对参数进行极大化,第1项可以写为:
$\sum_{I} \log \pi_{i_{b}} P(O, I | \overline{\lambda})=\sum_{i=1}^{N} \log \pi_{i} P\left(O, i_{1}=i | \overline{\lambda}\right)$
根据$\sum_{i=1}^{N} \pi_{i}=1$,利用拉格朗日乘子法,写出拉格朗日函数:
$\sum_{i=1}^{N} \log \pi_{i} P\left(O, i_{1}=i | \overline{\lambda}\right)+\gamma\left(\sum_{i=1}^{N} \pi_{i}-1\right)$
对其求偏导并令其为0可得:
$\pi_{i}=\frac{P\left(O, i_{1}=i | \overline{\lambda}\right)}{P(O | \overline{\lambda})}$
用$\gamma_{t}(i)$, $\quad \xi_{i}(i, j)$表示可以写为:
$\pi_{i}=\gamma_{1}(i)$
同理,对转移概率和观测概率进行求偏导可得:
$a_{i j}=\frac{\sum_{i=1}^{T-1} \xi_{i}(i, j)}{\sum_{i=1}^{T-1} \gamma_{i}(i)}$
$b_{j}(k)=\frac{\sum_{t=1, o_{k}=v_{k}}^{T} \gamma_{t}(j)}{\sum_{t=1}^{T} \gamma_{t}(j)}$
五、预测算法
预测算法是指当给定模型$\lambda$和观测序列O,求概率最大的状态序列。一般有两种算法:近似算法和维特比算法。
5.1 近似算法
近似算法的思想是,在每个时刻t tt选择在该时刻最有可能出现的状态$i_{t}^{*}$,从而得到一个状态序列$I^{*}=\left(i_{1}^{*}, i_{2}^{*}, \cdots, i_{T}^{*}\right)$,将它作为预测的结果。
给定HMM模型$\lambda$和观测序列O,在时刻t处于状态$q_{i}$的概率$\gamma_{t}(i)$为:
$\gamma_{t}(i)=\frac{\alpha_{t}(i) \beta_{t}(i)}{P(O | \lambda)}=\frac{\alpha_{t}(i) \beta_{t}(i)}{\sum_{j=1}^{N} \alpha_{t}(j) \beta_{t}(j)}$
在每一个时刻t最有可能的状态:
$i_{t}^{*}=\arg \max _{1 \leqslant i \leqslant N}\left[\gamma_{t}(i)\right], \quad t=1,2, \cdots, T$
从而得到状态序列
$I^{*}=\left(i_{1}^{*}, i_{2}^{*}, \cdots, i_{T}^{*}\right)$
虽然近似计算思想简单,但是预测的序列可能有实际不发生的部分,即有可能出现转移概率为0的相邻状态,没法保证整体上的状态序列是最有可能的。
5.2 维特比算法
维特比算法则通过动态规划求概率最大的路径,每一条路径即对应着一个状态序列。维特比算法从时刻t=1开始,递推地计算在时刻t状态为$i$的各条部分路径的最大概率,直到得到时刻t=T状态为$i$的各条路径的最大概率,时刻t=T的最大概率记为最优路径的概率$P^{*}$,最优路径的终结点$i_{T}^{*}$也同时得到,之后,从终结点开始,由后向前逐步求得结点$i_{T-1}^{*}, \cdots, i_{1}^{*}$,最终得到最优路径$I^{*}=\left(i_{1}^{*}, i_{2}^{*}, \cdots, i_{T}^{*}\right)$。
首先定义两个变量$\delta$和$\psi$,定义在时刻t状态为$i$的所有单个路径$\left(i_{1}, i_{2}, \cdots, i_{t}\right)$中概率最大值为
$\delta_{t}(i)=\max _{i_{1}, i_{2}, \cdots,_{t-1}} P\left(i_{t}=i, i_{t-1}, \cdots, i_{1}, o_{t}, \cdots, o_{1} | \lambda\right), \quad i=1,2, \cdots, N$
由定义可得$\delta$的递推公式:

定义在时刻t状态为i的所有单个路径$\left(i_{1}, i_{2}, \cdots, i_{t-1}, i\right)$中概率最大的路径的第t−1个结点为:
$\psi_{t}(i)=\arg \max _{1 \leqslant j \leqslant N}\left[\delta_{t-1}(j) a_{j i}\right], \quad i=1,2, \cdots, N$
维特比算法:
1、输入:模型$\lambda=(A, B, \pi)$和观测$O=\left(o_{1}, o_{2}, \cdots, o_{T}\right)$
2、输出:最优路径$I^{*}=\left(i_{1}^{*}, i_{2}^{*}, \cdots, i_{T}^{*}\right)$
3、初始化:
$\delta _{1}(i)=\pi _{i}b_{i}(o_{1})$, $i=1,2,\cdots ,N$
$\psi _{1}(i)=0$, $i=1,2,\cdots ,N$
4、递推,对$t=2,3, \cdots, T$
5、终止: 6、最终路径回溯。对$t=T-1, T-2, \cdots, 1$
6、最终路径回溯。对$t=T-1, T-2, \cdots, 1$
$i_{t}^{*}=\psi_{t+1}\left(i_{t+1}^{*}\right)$
求得最优路径$I^{*}=\left(i_{1}^{*}, i_{2}^{*}, \cdots, i_{T}^{*}\right)$
参考
《统计学习方法(第2版)》 李航 著
https://blog.csdn.net/linchuhai/article/details/91542210
https://blog.csdn.net/zgcr654321/article/details/92639420
隐马尔科夫模型(HMM)原理详解的更多相关文章
- 隐马尔科夫模型HMM学习最佳范例
谷歌路过这个专门介绍HMM及其相关算法的主页:http://rrurl.cn/vAgKhh 里面图文并茂动感十足,写得通俗易懂,可以说是介绍HMM很好的范例了.一个名为52nlp的博主(google ...
- 隐马尔科夫模型HMM(三)鲍姆-韦尔奇算法求解HMM参数
隐马尔科夫模型HMM(一)HMM模型 隐马尔科夫模型HMM(二)前向后向算法评估观察序列概率 隐马尔科夫模型HMM(三)鲍姆-韦尔奇算法求解HMM参数(TODO) 隐马尔科夫模型HMM(四)维特比算法 ...
- 隐马尔科夫模型HMM(四)维特比算法解码隐藏状态序列
隐马尔科夫模型HMM(一)HMM模型 隐马尔科夫模型HMM(二)前向后向算法评估观察序列概率 隐马尔科夫模型HMM(三)鲍姆-韦尔奇算法求解HMM参数 隐马尔科夫模型HMM(四)维特比算法解码隐藏状态 ...
- 用hmmlearn学习隐马尔科夫模型HMM
在之前的HMM系列中,我们对隐马尔科夫模型HMM的原理以及三个问题的求解方法做了总结.本文我们就从实践的角度用Python的hmmlearn库来学习HMM的使用.关于hmmlearn的更多资料在官方文 ...
- 隐马尔科夫模型HMM
崔晓源 翻译 我们通常都习惯寻找一个事物在一段时间里的变化规律.在很多领域我们都希望找到这个规律,比如计算机中的指令顺序,句子中的词顺序和语音中的词顺序等等.一个最适用的例子就是天气的预测. 首先,本 ...
- 猪猪的机器学习笔记(十七)隐马尔科夫模型HMM
隐马尔科夫模型HMM 作者:樱花猪 摘要: 本文为七月算法(julyedu.com)12月机器学习第十七次课在线笔记.隐马尔可夫模型(Hidden Markov Model,HMM)是统计模型,它用来 ...
- 隐马尔科夫模型HMM(二)前向后向算法评估观察序列概率
隐马尔科夫模型HMM(一)HMM模型 隐马尔科夫模型HMM(二)前向后向算法评估观察序列概率 隐马尔科夫模型HMM(三)鲍姆-韦尔奇算法求解HMM参数(TODO) 隐马尔科夫模型HMM(四)维特比算法 ...
- 隐马尔科夫模型HMM(一)HMM模型
隐马尔科夫模型HMM(一)HMM模型基础 隐马尔科夫模型HMM(二)前向后向算法评估观察序列概率 隐马尔科夫模型HMM(三)鲍姆-韦尔奇算法求解HMM参数(TODO) 隐马尔科夫模型HMM(四)维特比 ...
- 机器学习之隐马尔科夫模型HMM(六)
摘要 隐马尔可夫模型(Hidden Markov Model,HMM)是统计模型,它用来描述一个含有隐含未知参数的马尔科夫过程.其难点是从可观察的参数中确定该过程的隐含参数,然后利用这些参数来作进一步 ...
随机推荐
- 超详细!使用 LVS 实现负载均衡原理及安装配置详解---转
负载均衡集群是 load balance 集群的简写,翻译成中文就是负载均衡集群.常用的负载均衡开源软件有nginx.lvs.haproxy,商业的硬件负载均衡设备F5.Netscale.这里主要是学 ...
- Vue--子组件互相传值,子组件来回传值,传值反复横跳
Vue--子组件传值,子组件来回传值,子组件传值反复横跳 我不不仅要子组件之间直接传值,我还要传过去再传回来,传回来再传过去,子组件直接反复横跳 解决问题 给组件传值,并不知道改值的校验结果 同一个组 ...
- 二、初步认识LoadRunner工具
LoadRunner工具有三个组成分别是: Virtual User Generator:用户行为模拟:录制运行脚本. Controller:上面的录制一个用户操作,这个可以将其克隆成多个用户,模拟多 ...
- 第一次软件工程与UML的编程作业
博客班级 https://edu.cnblogs.com/campus/fzzcxy/2018SE1/ 作业要求 https://edu.cnblogs.com/campus/fzzcxy/2018S ...
- Elastic Search 学习之路(二)——inverted index(反向索引)
这是篇翻译文,图画的挺有意思. Elastic使用非常特殊的数据结构,称作反向索引.反向索引中,包括了一组document中出现的唯一的单词,和对应的单词,所出现的位置.反向索引是在ES中,docum ...
- windows宿主机访问ubuntu虚拟机中的docker服务
查看docker容器地址和虚拟机地址 windows主机中添加路由 #route -p add 172.17.0.0 mask 255.255.0.0 虚拟机地址 route -p add 172.1 ...
- 面试 02-CSS盒模型及BFC
02-CSS盒模型及BFC #题目:谈一谈你对CSS盒模型的认识 专业的面试,一定会问 CSS 盒模型.对于这个题目,我们要回答一下几个方面: (1)基本概念:content.padding.marg ...
- [打基础]luogu2181对角线——计数原理
啦啦啦我ysw又回来啦!之后大概会准备打acm,暑假尽量复习复习,因为已经快两年没碰oi了,最多也就高三noip前学弟学妹出题讲题,所以从这一篇blog开始大概会有一系列"打基础" ...
- CSS —— css属性
1.颜色属性 background-color: #CCCCCC; rgba (红色,绿色,蓝色,透明度) background-color: rgba( 0, 0, 0, 5 ) 2.字体属性 fo ...
- prim algorithm
function re=biaoji(j,biao) %判断j点是否已被标记 l=length(biao); for i=1:l if j==biao(i) re=1; return; end end ...