Bilateral Multi-Perspective Matching for Natural Language Sentences---读书笔记
- 自然语言句子的双向、多角度匹配,是来自IBM 2017 年的一篇文章。代码github地址:https://github.com/zhiguowang/BiMPM
- 摘要
- 自然语言句子匹配(Natural language sentence matching ,NLSM)是比较两个句子并且识别它们的关系的任务。
- NLSM 一般有两种架构来解决:
- BiMPM 属于 匹配聚合框架。
- 之前的 匹配聚合框架的局限性:
- BiMPM 对以上的两个局限性进行了改进。
- 任务的定义:
- BiMPM 架构图

- word representstion layer(词表达层):
- context representation layer(上下文表达层):
- matching layer(匹配层)
- aggregation layer(聚合层):
- prediction layer(预测层):
- Multi-perspective Matching Operation(多角度匹配操作):
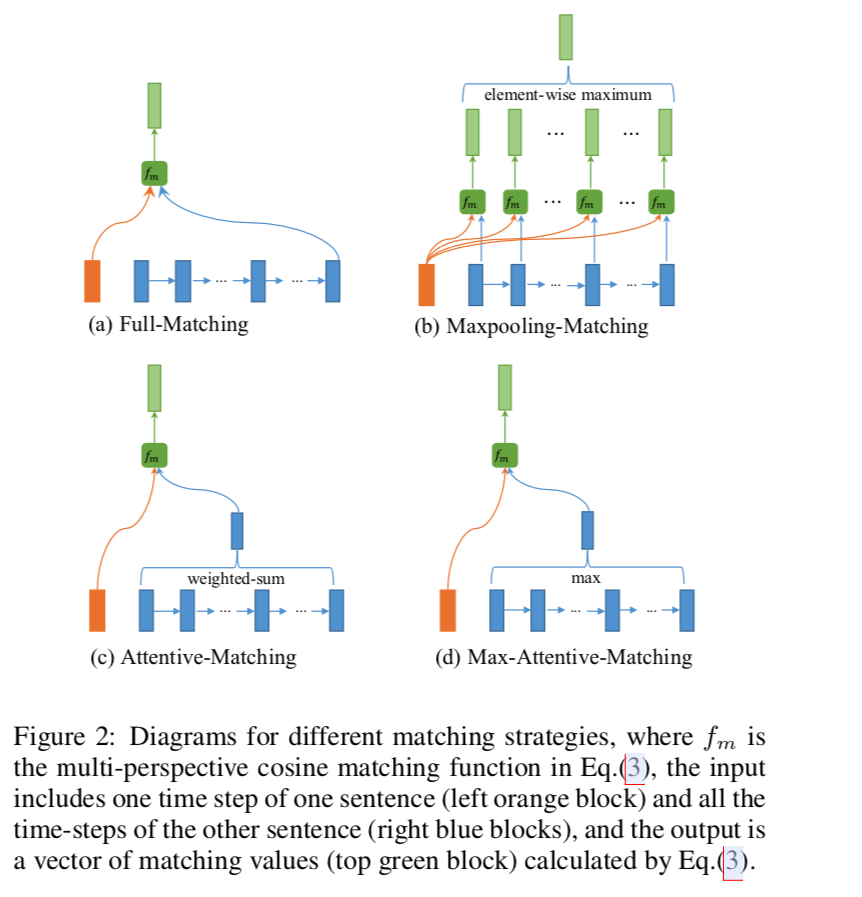
- 实验参数设置:
- Quora Question Pairs(https://www.kaggle.com/quora/question-pairs-dataset)
- quora dataset 训练/验证/测试集的选取
Bilateral Multi-Perspective Matching for Natural Language Sentences---读书笔记的更多相关文章
- 《Bilateral Multi-Perspective Matching for Natural Language Sentences》(句子匹配)
问题: Natural language sentence matching (NLSM),自然语言句子匹配,是指比较两个句子并判断句子间关系,是许多任务的一项基本技术.针对NLSM任务,目前有两种流 ...
- BiMPM:Bilateral Multi-Perspctive Matching for Natural Language Sentences
导言 本论文的工作主要是在 'matching-aggregation'的sentence matching的框架下,通过增加模型的特征(实现P与Q的双向匹配和多视角匹配),来增加NLSM(Natur ...
- Convolutional Neural Network Architectures for Matching Natural Language Sentences
interaction n. 互动;一起活动;合作;互相影响 capture vt.俘获;夺取;夺得;引起(注意.想像.兴趣)n.捕获;占领;捕获物;[计算机]捕捉 hence adv. 从此;因 ...
- 《Convolutional Neural Network Architectures for Matching Natural Language Sentences》句子匹配
模型结构与原理 1. 基于CNN的句子建模 这篇论文主要针对的是句子匹配(Sentence Matching)的问题,但是基础问题仍然是句子建模.首先,文中提出了一种基于CNN的句子建模网络,如下图: ...
- 《The C Programming Language》读书笔记(一)
1. 对这本书的印象 2011年进入大学本科,C语言入门书籍如果我没记错的话应该是谭浩强的<C程序设计>,而用现在的眼光来看,这本书只能算是一本可用的教材,并不能说是一本好书.在自学操作系 ...
- 《PC Assembly Language》读书笔记
本书下载地址:pcasm-book. 前言 8086处理器只支持实模式(real mode),不能满足安全.多任务等需求. Q:为什么实模式不安全.不支持多任务?为什么虚模式能解决这些问题? A: 以 ...
- Parsing Natural Scenes and Natural Language with Recursive Neural Networks-paper
Parsing Natural Scenes and Natural Language with Recursive Neural Networks作者信息: Richard Socher richa ...
- <Natural Language Processing with Python>学习笔记一
Spoken input (top left) is analyzed, words are recognized, sentences are parsed and interpreted in c ...
- (zhuan) Speech and Natural Language Processing
Speech and Natural Language Processing obtain from this link: https://github.com/edobashira/speech-l ...
随机推荐
- .net 后台页面统一验证是否登录
首先新写一个PageBase类 using System; using System.Collections.Generic; using System.Web; namespace Departme ...
- OPT
http://cdn.imgtec.com/sdk-documentation/PowerVR.Performance+Recommendations.pdf 宝贝 https://developer ...
- JavaScript, JQuery事件委托
1.引言 现实当中,前台MM收到快递后,她会判断收件人是谁,然后按照收件人的要求签收,甚至代为付款.(公司也不会容忍那么多员工站在门口就为了等快递); 这种事件委托还有个好处,就是即便公司又来很多员工 ...
- JSONP劫持
发出空refer的POC <!DOCTYPE html> <html> <head> <meta name="referrer" cont ...
- express框架封装前戏
一.开启一文件,这里暂且命名为aexpressclass.js 声明一个app类,用来模仿http模块中的回调函数 //var route = require('http-route'); var u ...
- C# 加载显示ftp上图片方法
ftp://用户名:密码@IP/路径 FTP的一种登陆方式 如ftp://sing:song@192.168.1.133/upload/pic/236.jpg
- HDU 3824/ BZOJ 3963 [WF2011]MachineWorks (斜率优化DP+CDQ分治维护凸包)
题面 BZOJ传送门(中文题面但是权限题) HDU传送门(英文题面) 分析 定义f[i]f[i]f[i]表示在iii时间(离散化之后)卖出手上的机器的最大收益.转移方程式比较好写f[i]=max{f[ ...
- 使用Eclipse进行远程调试(转)
做开发好多年了,Debug大家肯定都不陌生,绝对称得上是家常便饭了.博主虽不敢妄下断言,但是这里也猜一下,肯定有很多人都没有使用过Remote Debug(远程调试).说来惭愧,博主也是工作了3年才用 ...
- decompiler
.NET Reflector trial version http://www.red-gate.com/products/dotnet-development/reflector/ 破解版本 .N ...
- tomcat发布web项目
转:https://www.cnblogs.com/skyblue-li/p/7888951.html Tomcat是一种Web服务器,我们自己做好了一个Web项目,就可以通过Tomcat来发布.服务 ...