Bilateral Multi-Perspective Matching for Natural Language Sentences---读书笔记
- 自然语言句子的双向、多角度匹配,是来自IBM 2017 年的一篇文章。代码github地址:https://github.com/zhiguowang/BiMPM
- 摘要
- 自然语言句子匹配(Natural language sentence matching ,NLSM)是比较两个句子并且识别它们的关系的任务。
- NLSM 一般有两种架构来解决:
- BiMPM 属于 匹配聚合框架。
- 之前的 匹配聚合框架的局限性:
- BiMPM 对以上的两个局限性进行了改进。
- 任务的定义:
- BiMPM 架构图

- word representstion layer(词表达层):
- context representation layer(上下文表达层):
- matching layer(匹配层)
- aggregation layer(聚合层):
- prediction layer(预测层):
- Multi-perspective Matching Operation(多角度匹配操作):
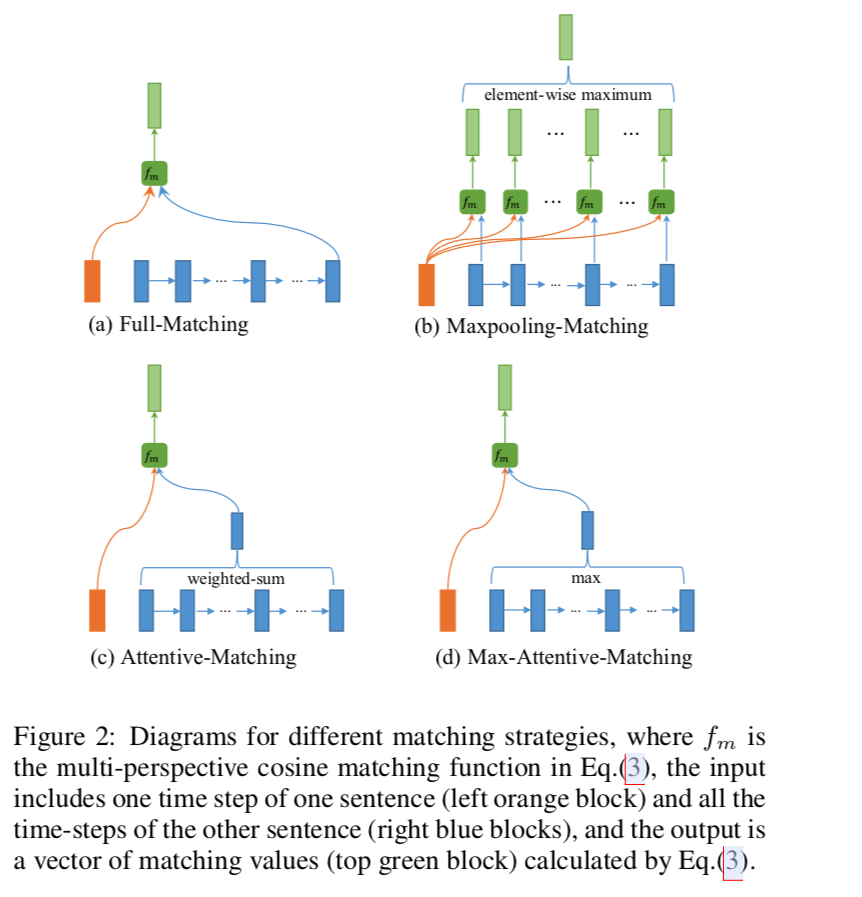
- 实验参数设置:
- Quora Question Pairs(https://www.kaggle.com/quora/question-pairs-dataset)
- quora dataset 训练/验证/测试集的选取
Bilateral Multi-Perspective Matching for Natural Language Sentences---读书笔记的更多相关文章
- 《Bilateral Multi-Perspective Matching for Natural Language Sentences》(句子匹配)
问题: Natural language sentence matching (NLSM),自然语言句子匹配,是指比较两个句子并判断句子间关系,是许多任务的一项基本技术.针对NLSM任务,目前有两种流 ...
- BiMPM:Bilateral Multi-Perspctive Matching for Natural Language Sentences
导言 本论文的工作主要是在 'matching-aggregation'的sentence matching的框架下,通过增加模型的特征(实现P与Q的双向匹配和多视角匹配),来增加NLSM(Natur ...
- Convolutional Neural Network Architectures for Matching Natural Language Sentences
interaction n. 互动;一起活动;合作;互相影响 capture vt.俘获;夺取;夺得;引起(注意.想像.兴趣)n.捕获;占领;捕获物;[计算机]捕捉 hence adv. 从此;因 ...
- 《Convolutional Neural Network Architectures for Matching Natural Language Sentences》句子匹配
模型结构与原理 1. 基于CNN的句子建模 这篇论文主要针对的是句子匹配(Sentence Matching)的问题,但是基础问题仍然是句子建模.首先,文中提出了一种基于CNN的句子建模网络,如下图: ...
- 《The C Programming Language》读书笔记(一)
1. 对这本书的印象 2011年进入大学本科,C语言入门书籍如果我没记错的话应该是谭浩强的<C程序设计>,而用现在的眼光来看,这本书只能算是一本可用的教材,并不能说是一本好书.在自学操作系 ...
- 《PC Assembly Language》读书笔记
本书下载地址:pcasm-book. 前言 8086处理器只支持实模式(real mode),不能满足安全.多任务等需求. Q:为什么实模式不安全.不支持多任务?为什么虚模式能解决这些问题? A: 以 ...
- Parsing Natural Scenes and Natural Language with Recursive Neural Networks-paper
Parsing Natural Scenes and Natural Language with Recursive Neural Networks作者信息: Richard Socher richa ...
- <Natural Language Processing with Python>学习笔记一
Spoken input (top left) is analyzed, words are recognized, sentences are parsed and interpreted in c ...
- (zhuan) Speech and Natural Language Processing
Speech and Natural Language Processing obtain from this link: https://github.com/edobashira/speech-l ...
随机推荐
- C#串口图片传输以及对串口缓冲区的简单理解
第一次接触串口,写点东西加深自己对串口的印象: 通过参考一些网上的实例,我明白了串口怎么简单的进行通信交流,但是我所需要的还是图片等大文件在串口中的传输,串口传输是通过二进制位进行单位传输的,所以传输 ...
- [Luogu P4145] 上帝造题的七分钟2 / 花神游历各国
题目链接 题目简要:我们需要一个能支持区间内每一个数开方以及区间求和的数据结构. 解题思路:说道区间修改区间查询,第一个想到的当然就是分块线段树.数据范围要用long long.本来我是看到区间这两个 ...
- Flutter布局----弹性布局 (Flex)
弹性布局(Flex) 弹性布局允许子组件按照一定比例来分配父容器空间.弹性布局的概念在其它UI系统中也都存在,如H5中的弹性盒子布局,Android中的FlexboxLayout等.Flutter中的 ...
- session.getdefaultinstance和getinstance的区别
如果想要同时使用两个帐号发送javamail,比如使用1@a.com发送1#邮件,使用2@a.com发送2#邮件,这时候,你就需要同时创建两个java.mail.Session对象.但是如果你仍然使用 ...
- Mongodb账户管理
Mongodb账户管理 介绍 Mongodb是一个schema free的非sql类分布式数据库,可以利用它做很多很灵活的存储和操作,最近了解了下它的账户机制,通过设置auth启动方式可以对所有登 ...
- word文档如何选择全部图片粘贴
很多时候我们用一些管理系统的时候,发布新闻.公告等文字类信息时,希望能很快的将word里面的内容直接粘贴到富文本编辑器里面,然后发布出来.减少排版复杂的工作量. 下面是借用百度doc 来快速实现这个w ...
- nc命令用法举
什么是nc nc是netcat的简写,有着网络界的瑞士军刀美誉.因为它短小精悍.功能实用,被设计为一个简单.可靠的网络工具 nc的作用 (1)实现任意TCP/UDP端口的侦听,nc可以作为server ...
- PHP基础--traits的应用
Traits 在PHP中实现在方法的重复使用:Traits与Class相似,但是它能够在Class中使用自己的方法而不用继承: Traits在Class中优先于原Class中的方法,引用PHP Doc ...
- [USACO17JAN] 晋升者计数 dfs序+树状数组
[USACO17JAN] 晋升者计数 dfs序+树状数组 题面 洛谷P3605 题意:一棵有点权的树,找出树中所有\((u,v)\)的对数,其中\(u,v\)满足\(val(u)\le val(v)\ ...
- bbs-admin-自定义admin(二)
本文内容 目的:模仿admin默认配置,自定义配置类 一 查 1 查看数据 2 查看表头 3 分页器 4 search(搜索框) 5 action(批量处理) 6 filter(分类) ...