Ansj与hanlp分词工具对比
一、Ansj
1、利用DicAnalysis可以自定义词库:
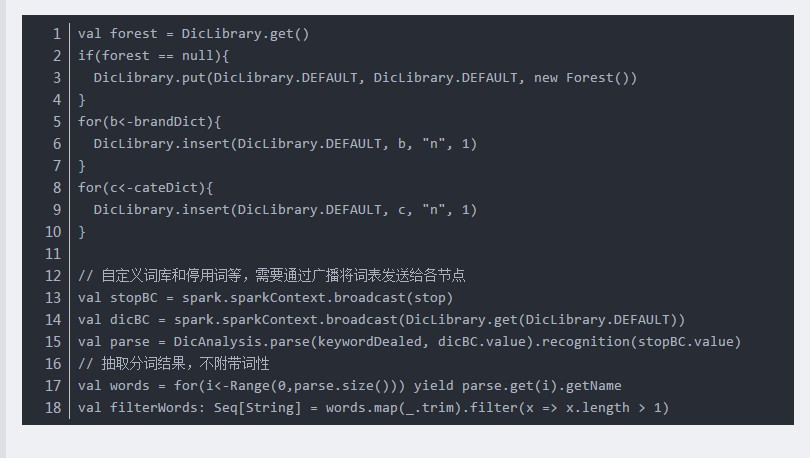
2、但是自定义词库存在局限性,导致有些情况无效:
比如:“不好用“的正常分词结果:“不好,用”。
(1)当自定义词库”好用“时,词库无效,分词结果不变。
(2)当自定义词库
“不好用”时,分词结果为:“不好用”,即此时自定义词库有效。
3、由于版本问题,可能DicAnalysis, ToAnalysis等类没有序列化,导致读取hdfs数据出错
此时需要继承序列化接口
1|case class myAnalysis() extends DicAnalysis with Serializable
2|val seg = new myAnalysis()
二、HanLP
同样可以通过CustomDictionary自定义词库:
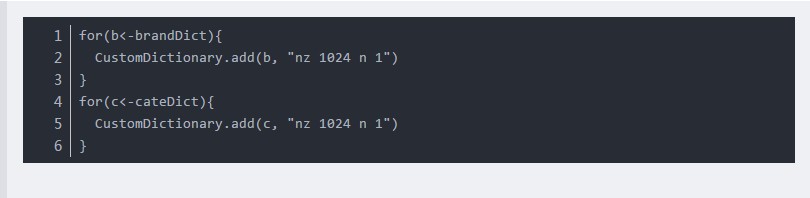
但是在统计分词中,并不保证自定义词典中的词一定被切分出来,因此用户可在理解后果的情况下通过
1|StandardTokenizer.SEGMENT.enableCustomDictionaryForcing(true)强制生效
并发问题:
CustomDictionary是全局变量,不能在各节点中更改,否则会出现并发错误。
但是HanLP.segment(sentence),只有一个参数,不能指定CustomDictionary,导致在各个excutors计算的时候全局CustomDictionary无效。
由于CustomDictionary是全局变量,因此我采用一个方式:每个分区都对CustomDictionary加锁并添加一次词库,性能影响较小:

Ansj与hanlp分词工具对比的更多相关文章
- hanlp分词工具应用案例:商品图自动推荐功能的应用
本篇分享一个hanlp分词工具应用的案例,简单来说就是做一图库,让商家轻松方便的配置商品的图片,最好是可以一键完成配置的. 先看一下效果图吧: 商品单个推荐效果:匹配度高的放在最前面 这个想法很好,那 ...
- HanLP分词工具中的ViterbiSegment分词流程
本篇文章将重点讲解HanLP的ViterbiSegment分词器类,而不涉及感知机和条件随机场分词器,也不涉及基于字的分词器.因为这些分词器都不是我们在实践中常用的,而且ViterbiSegment也 ...
- 开源中文分词工具探析(三):Ansj
Ansj是由孙健(ansjsun)开源的一个中文分词器,为ICTLAS的Java版本,也采用了Bigram + HMM分词模型(可参考我之前写的文章):在Bigram分词的基础上,识别未登录词,以提高 ...
- HanLP分词命名实体提取详解
HanLP分词命名实体提取详解 分享一篇大神的关于hanlp分词命名实体提取的经验文章,文章中分享的内容略有一段时间(使用的hanlp版本比较老),最新一版的hanlp已经出来了,也可以去看看新版 ...
- 中文分词工具探析(二):Jieba
1. 前言 Jieba是由fxsjy大神开源的一款中文分词工具,一款属于工业界的分词工具--模型易用简单.代码清晰可读,推荐有志学习NLP或Python的读一下源码.与采用分词模型Bigram + H ...
- 中文分词工具探析(一):ICTCLAS (NLPIR)
1. 前言 ICTCLAS是张华平在2000年推出的中文分词系统,于2009年更名为NLPIR.ICTCLAS是中文分词界元老级工具了,作者开放出了free版本的源代码(1.0整理版本在此). 作者在 ...
- 开源中文分词工具探析(四):THULAC
THULAC是一款相当不错的中文分词工具,准确率高.分词速度蛮快的:并且在工程上做了很多优化,比如:用DAT存储训练特征(压缩训练模型),加入了标点符号的特征(提高分词准确率)等. 1. 前言 THU ...
- 开源中文分词工具探析(五):FNLP
FNLP是由Fudan NLP实验室的邱锡鹏老师开源的一套Java写就的中文NLP工具包,提供诸如分词.词性标注.文本分类.依存句法分析等功能. [开源中文分词工具探析]系列: 中文分词工具探析(一) ...
- 开源中文分词工具探析(五):Stanford CoreNLP
CoreNLP是由斯坦福大学开源的一套Java NLP工具,提供诸如:词性标注(part-of-speech (POS) tagger).命名实体识别(named entity recognizer ...
随机推荐
- zip:命令行下zip压缩/解压缩
在Ubuntu 18.04下验证,造冰箱的大熊猫@cnblogs 2019/6/6 序号 功能 命令行输入的命令 1 压缩单个文件 zip package.zip file 2 压缩多个文件 zip ...
- hdu 5187 zhx's contest (快速幂+快速乘)
zhx's contest Time Limit: 2000/1000 MS (Java/Others) Memory Limit: 65536/65536 K (Java/Others) To ...
- Python基础之基本数据类型的总结
基本数据类型的总结 1. 按照存储空间的占用分(从低到高) 数字 字符串 集合:无序,即无序存索引相关信息 元组:有序,需要存索引相关信息,不可变 列表:有序,需要存索引相关信息,可变,需要处理数据的 ...
- Codeforces 1009 E. Intercity Travelling(计数)
1009 E. Intercity Travelling 题意:一段路n个点,走i千米有对应的a[i]疲劳值.但是可以选择在除终点外的其余n-1个点休息,则下一个点开始,疲劳值从a[1]开始累加.休息 ...
- 焦虑的 BAT、不安的编程语言,揭秘程序员技术圈生存现状!
[程序人生编者按]在迭代不休的技术圈中,仅在过去的一个月期间,我们见证了有史以来第一张黑洞照片的诞生:经历了为让人义愤填膺的 996:思考了作为程序员的年龄之槛:膜拜了技术大神的成长历程:追逐了如编程 ...
- Flume-安装与 NetCat UDP Source 监控端口
Flume 文档:https://flume.apache.org/FlumeUserGuide.html Flume 下载:https://archive.apache.org/dist/flume ...
- [MySql]MySql中外键设置 以及Java/MyBatis程序对存在外键关联无法删除的规避
在MySql设定两张表,其中product表的主键设定成orderTb表的外键,具体如下: 产品表: create table product(id INT(11) PRIMARY KEY,name ...
- linux如何将某个用户加入到其它组?
答: 在Ubuntu下可以使用以下命令添加: sudo usermod -a -G <group_name> <user_name> 注意: 如何生效呢? 需要重新登陆系统 ...
- LC 900. RLE Iterator
Write an iterator that iterates through a run-length encoded sequence. The iterator is initialized b ...
- 重画GoogleClusterTrace数据
由于项目计划书写作需要,重画了Qi Zhang, Mohamed Faten Zhani, Raouf Boutaba, Joseph L. Hellerstein, Dynamic Heteroge ...