论文笔记:Learning Dynamic Memory Networks for Object Tracking
Learning Dynamic Memory Networks for Object Tracking
ECCV 2018
Updated on 2018-08-05 16:36:30
Paper: arXiv version
Code: https://github.com/skyoung/MemTrack (Tensorflow Implementation)
【Note】This paper is developed based on Siamese Network and DNC(Nature-2016), please check these two papers for details to better understand this paper.
DNC: https://www.cnblogs.com/wangxiaocvpr/p/5960027.html Paper: http://www.nature.com/nature/journal/vaop/ncurrent/pdf/nature20101.pdf
Siamese Network based tracker: https://www.cnblogs.com/wangxiaocvpr/p/5897461.html Paper: Fully-Convolutional Siamese Network for Object Tracking
=================================
Motivation:想利用动态记忆网络(Dynamic Memory Network)来动态的更新 target template,以使得基于孪生网络的跟踪算法可以更好的掌握目标的 feature,可以学习到更好的 appearance model,从而实现更加准确的定位。
Method:主要是基于 Dynamic Memory Network 来实现目标物体的准确更新。通过动态的存储和读写 tracking results,来结合原始的 object patch,基于 Siamese Network Tracker 进行跟踪,速度可以达到:50 FPS。
Approach Details:
Dynamic Memory Networks for Tracking:
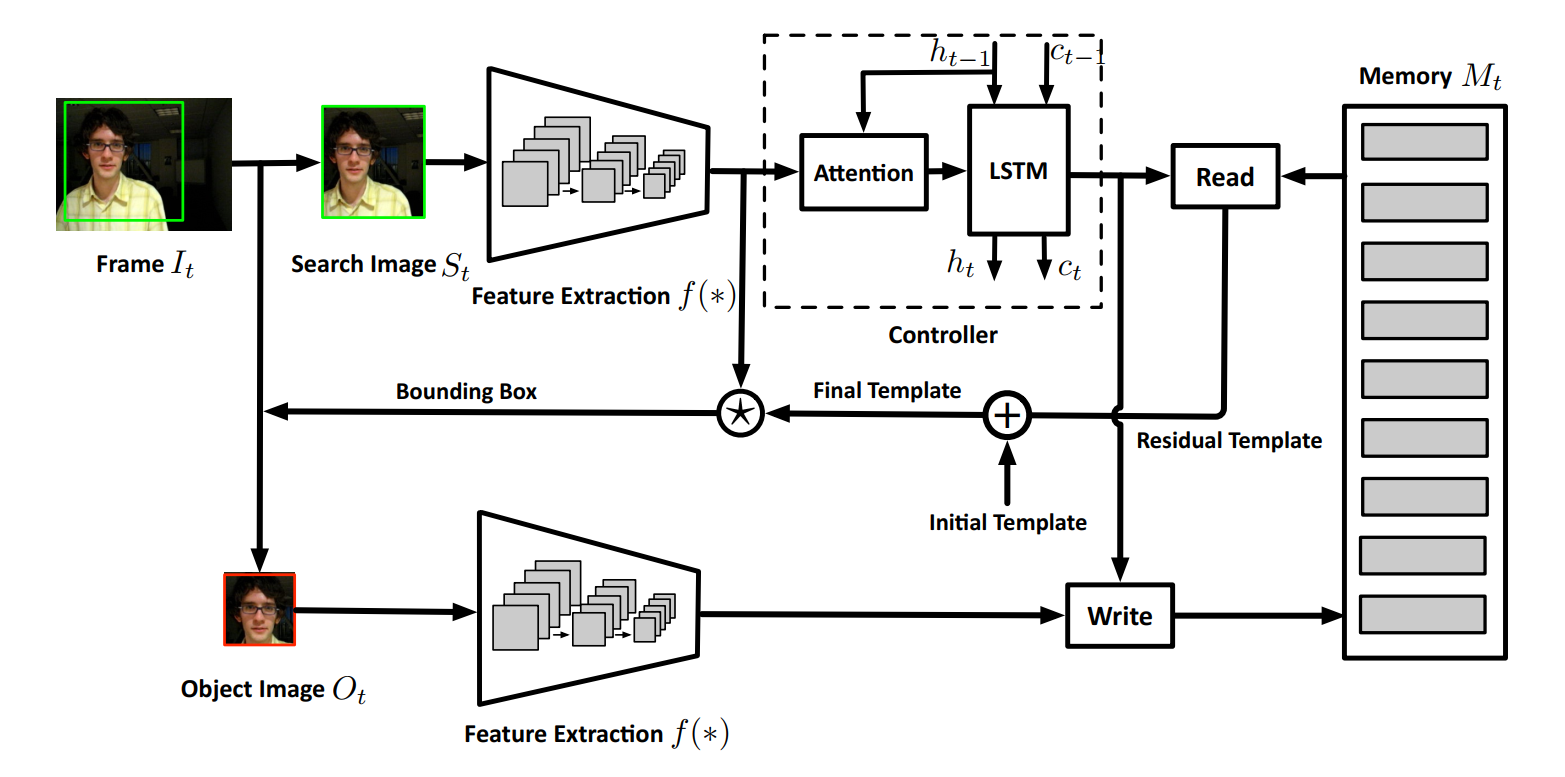
1. Feature Extraction:
本文的特征提取方面,借鉴了 SiamFC;此处不细说。
2. Attention Scheme:
本文介绍 Attention 机制引入的动机为:Since the object information in the search image is needed to retrieve the related template for matching, but the object location is unknown at first, we apply an attention mechanism to make the input of LSTM concentrate more on the target. 简单来讲,就是为了更好的确定所要跟踪的目标的位置,以更加方便的提取 proposals。
作者采用大小为 6*6*256 的 square patch 以滑动窗口的方式,对整个 search image 进行 patch 的划分。为了进一步的减少 square patch 的大小,我们采用了一种 average pooling 的方法:

那么,经过 attend 之后的 feature vector,可以看做是这些特征向量的加权组合(the weighted sum of the feature vectors):

其中,L 是图像块的个数,加权的权重可以通过 softmax 函数计算出来,计算公式如下:
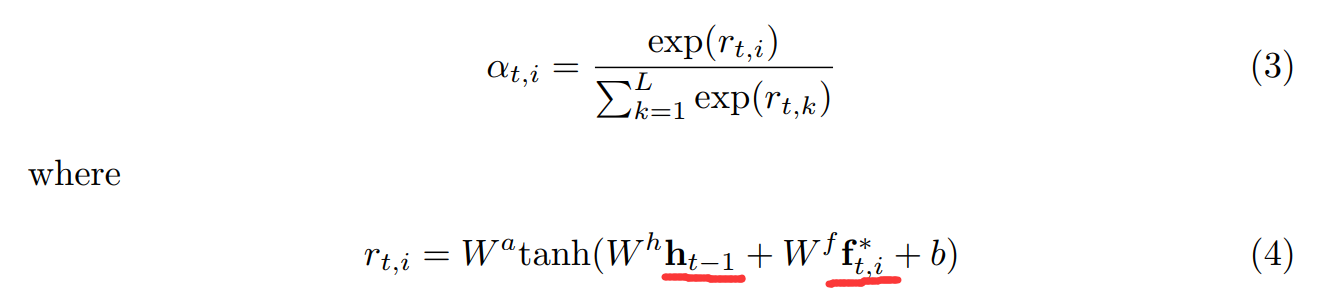
其中,这个就是 attention network,输入是:LSTM 的 hidden state $h_{t-1}$,以及 a square patch。另外的 W 以及 b 都是可以学习的网络权重和偏差。
下图展示了相关的视觉效果:

3. LSTM Memory Controller
此处,该网络的控制也是通过 lstm 来控制的,即:输入是上一个时刻的 hidden state,以及 当前时刻从 attention module 传递过来的 attended feature vector,输出一个新的 hidden state 来计算 memory control signals,即:read key, read strength, bias gates, and decay rate。
4. Memory Reading && Memory Writting && Residual Template Learning:
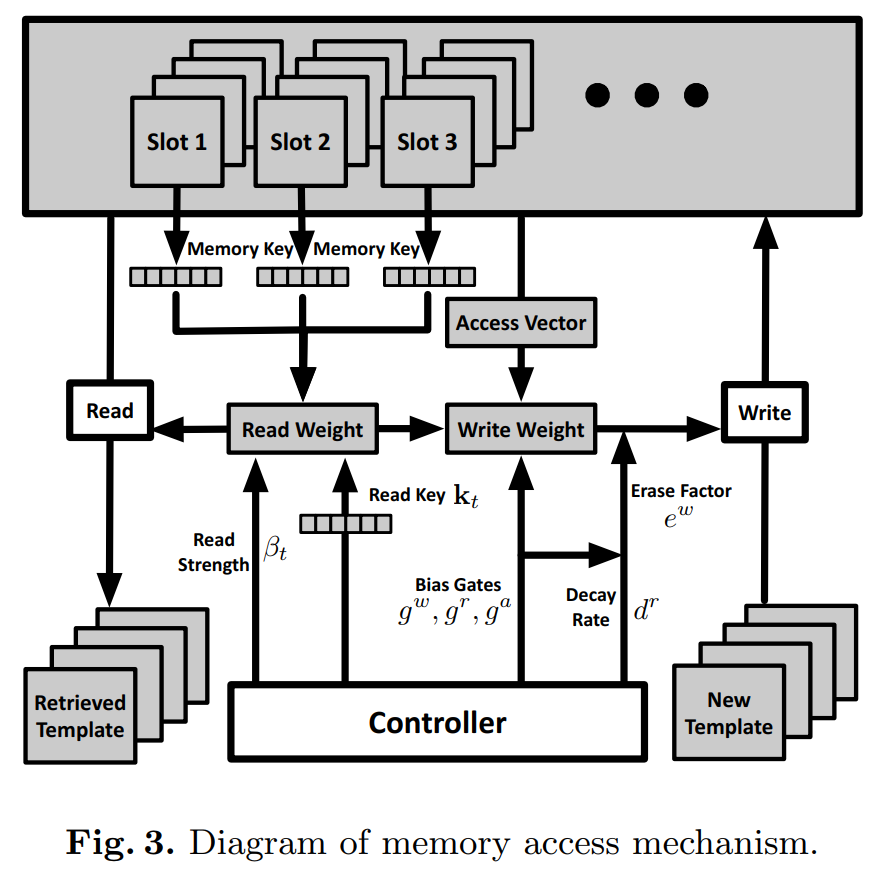
==>> 我们可以从 如下的这两个视角来看点这个 read 和 write 的问题:
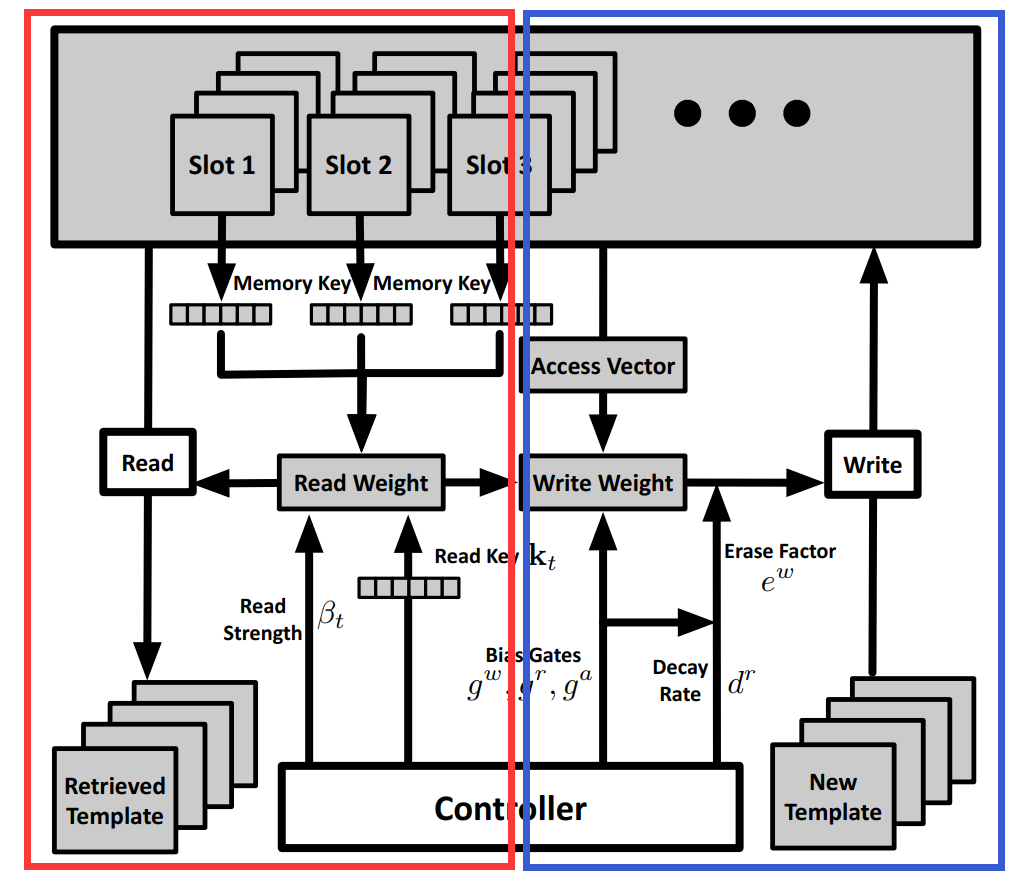
对于 Read,给定 LSTM 的输入信号,我们可以获得 Read Key 及其对应的 read strength,然后根据这个 vector 和 memory 中的记忆片段,进行 read weight 的计算,然后确定是否读取对应的 template;
具体来说:
(1) read key 及其 read strength 的计算可以用如下的公式:
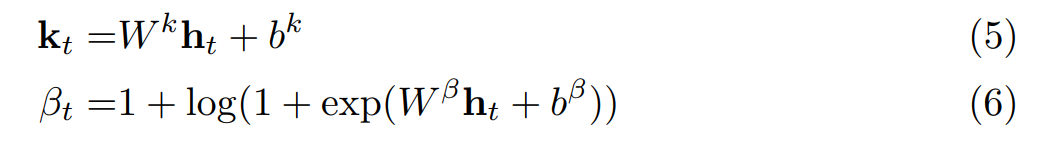
(2)read weight:
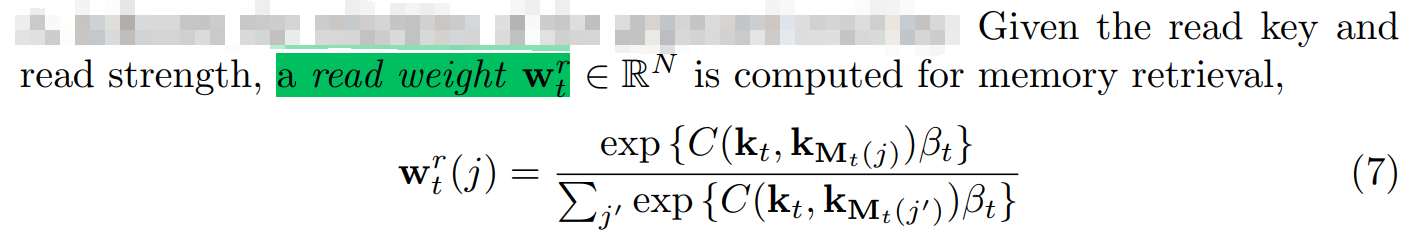
(3)the template is retrieved from memory:
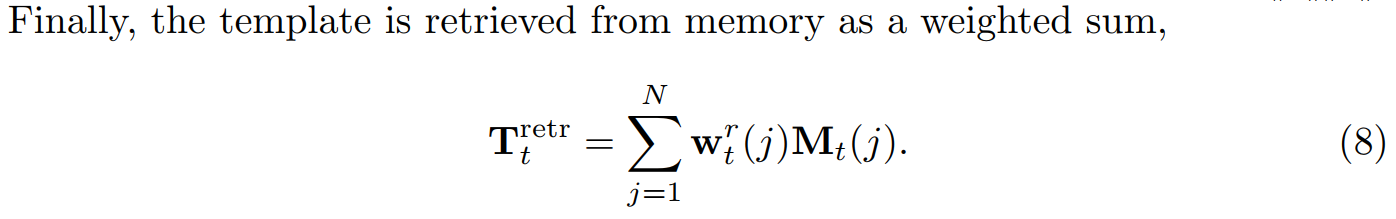
(4)最终模板的学习,可以通过如下公式计算得出:

对于 Write,给定 LSTM 的输入信号,我们可以计算 BiasGates 的三个值,从而知道 衰减率(decay rate),可以计算出 擦除因子(erase factor),我们根据获得的 write weight,来控制是否将 new templates 写入到 memory 中,以及写入多少的问题。、
(1)The write weight:
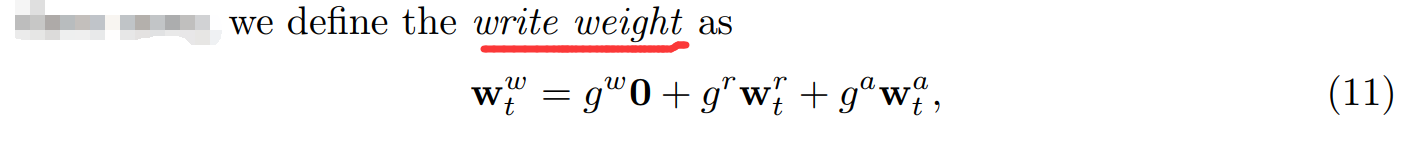
(2)The write gate:

(3)The allocation weight:

(4)最终模板的写入以及写入多少的控制:

==>> Experimental Results:
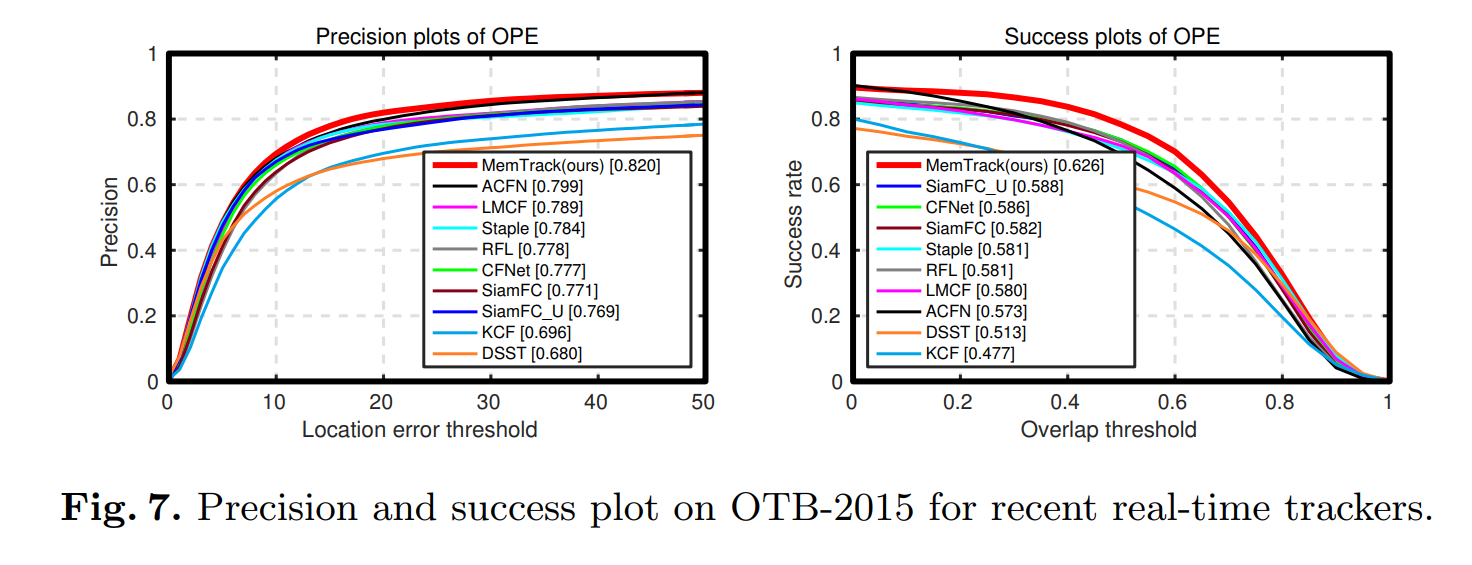
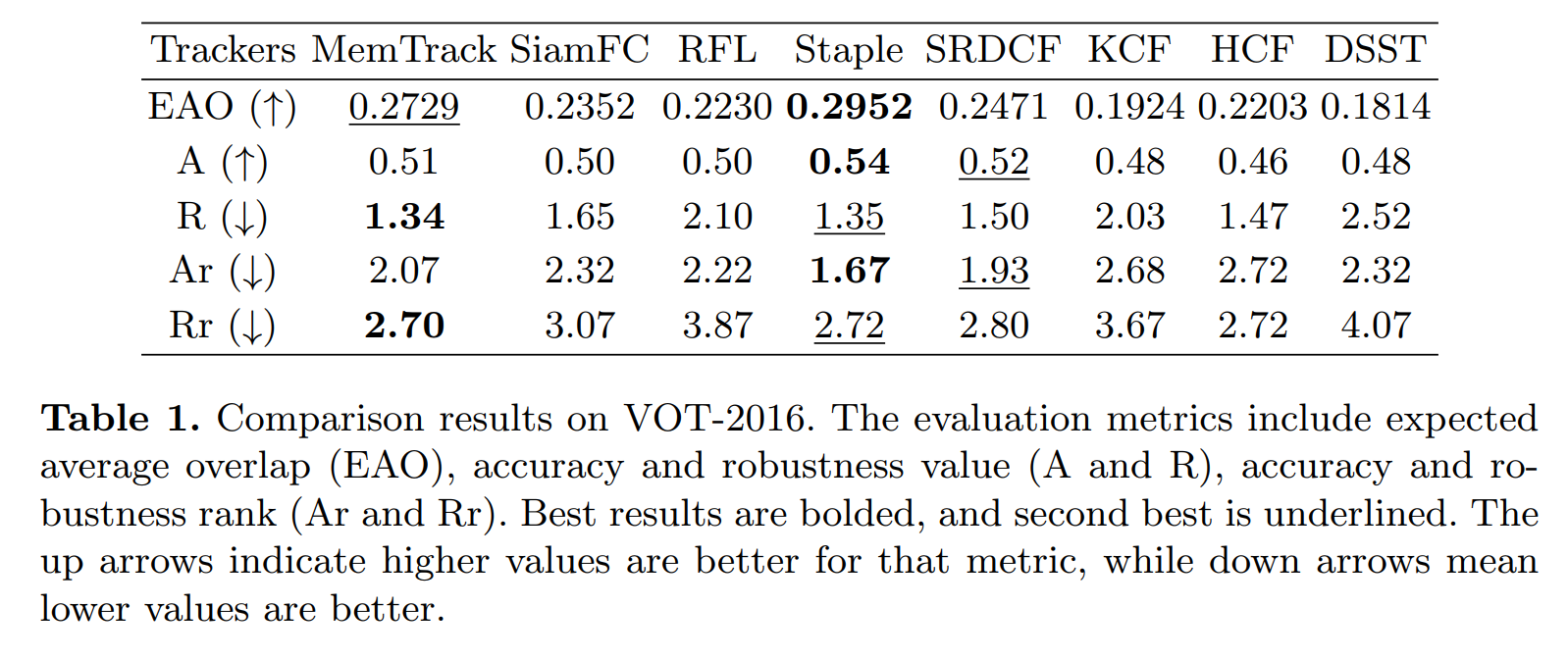
==
论文笔记:Learning Dynamic Memory Networks for Object Tracking的更多相关文章
- 论文笔记:Fully-Convolutional Siamese Networks for Object Tracking
Fully-Convolutional Siamese Networks for Object Tracking 本文作者提出一个全卷积Siamese跟踪网络,该网络有两个分支,一个是上一帧的目标,一 ...
- 论文笔记之:Action-Decision Networks for Visual Tracking with Deep Reinforcement Learning
论文笔记之:Action-Decision Networks for Visual Tracking with Deep Reinforcement Learning 2017-06-06 21: ...
- 论文笔记-Deep Affinity Network for Multiple Object Tracking
作者: ShijieSun, Naveed Akhtar, HuanShengSong, Ajmal Mian, Mubarak Shah 来源: arXiv:1810.11780v1 项目:http ...
- 论文笔记: Dual Deep Network for Visual Tracking
论文笔记: Dual Deep Network for Visual Tracking 2017-10-17 21:57:08 先来看文章的流程吧 ... 可以看到,作者所总结的三个点在于: 1. ...
- 论文笔记《Spatial Memory for Context Reasoning in Object Detection》
好久不写论文笔记了,不是没看,而是很少看到好的或者说值得记的了,今天被xinlei这篇paper炸了出来,这篇被据老大说xinlei自称idea of the year,所以看的时候还是很认真的,然后 ...
- 论文笔记之:Fully-Convolutional Siamese Networks for Object Tracking
gansh Fully-Convolutional Siamese Network for Object Tracking 摘要:任意目标的跟踪问题通常是根据一个物体的外观来构建表观模型.虽然也取得了 ...
- [论文理解] Learning Efficient Convolutional Networks through Network Slimming
Learning Efficient Convolutional Networks through Network Slimming 简介 这是我看的第一篇模型压缩方面的论文,应该也算比较出名的一篇吧 ...
- 论文笔记 — Learning to Compare Image Patches via Convolutional Neural Networks
论文: 引入论文中的一句话来说明对比图像patches的重要性,“Comparing patches across images is probably one of the most fundame ...
- 论文笔记:Heterogeneous Memory Enhanced Multimodal Attention Model for Video Question Answering
Heterogeneous Memory Enhanced Multimodal Attention Model for Video Question Answering 2019-04-25 21: ...
随机推荐
- Windows10上安装Keras 和 TensorFlow-GPU
安装环境: Windows 10 64bit GPU: GeForce gt 720 Python: 3.5.3 CUDA: 8 首先下载Anaconda3的Win10 64bit版,安装Python ...
- codeforces 980C Posterized
题意: 255个像素格子,可以把这个255个分组,每组的大小不能超过k. 给出n个像素,要求每个像素用这组的key代表,并且表示出来的字典序要最小. 思路: 感谢js教本智障. 很自然的会想到贪心,也 ...
- Python+OpenCV图像处理(一)——读取显示一张图片
先在此处先声明,后面学习python+opencv图像处理时均参考这位博主的博文https://blog.csdn.net/u011321546/article/category/7495016/2? ...
- 写出优质Java代码的4个技巧
我们平时的编程任务不外乎就是将相同的技术套件应用到不同的项目中去,对于大多数情况来说,这些技术都是可以满足目标的.然而,有的项目可能需要用到一些特别的技术,因此工程师们得深入研究,去寻找那些最简单但最 ...
- The logback manual #02# Architecture
索引 Logback's architecture Logger, Appenders and Layouts Effective Level(有效等级)又名Level Inheritance Ret ...
- P3243 [HNOI2015]菜肴制作(拓扑排序)
P3243 [HNOI2015]菜肴制作 题目误导你正着做拓扑排序,然鹅你可以手造数据推翻它.于是就只能倒着做 我们开个优先队列,每次把可填的最大的编号取出来搞,最后倒着输出拓扑序就好辣 #inclu ...
- P3302 [SDOI2013]森林(主席树+启发式合并)
P3302 [SDOI2013]森林 主席树+启发式合并 (我以前的主席树板子是错的.......坑了我老久TAT) 第k小问题显然是主席树. 我们对每个点维护一棵包含其子树所有节点的主席树 询问(x ...
- setfacl 设置文件访问控制列表
setfacl 设置文件访问控制列表 用法: setfacl [-bkndRLP] { -m|-M|-x|-X ... } file ... 参数: -m, --modify=acl 更改文件的访问控 ...
- nmap扫描内网存活机器脚本
nmap扫描内网存活机器并保存在指定文件中. host.sh #/usr/bin/bash read -p "Please input scan host or network:" ...
- 让CSS某行不失效
比如百度的分享代码 <div id="bdshare" class="bdshare_t bds_tools get-codes-bdshare"> ...