python网络编程基础(线程与进程、并行与并发、同步与异步、阻塞与非阻塞、CPU密集型与IO密集型)
python网络编程基础(线程与进程、并行与并发、同步与异步、阻塞与非阻塞、CPU密集型与IO密集型)
目录
线程与进程 并行与并发 同步与异步 阻塞与非阻塞 CPU密集型与IO密集型
线程与进程
进程
前言
进程的出现是为了更好的利用CPU资源使到并发成为可能。 假设有两个任务A和B,当A遇到IO操作,CPU默默的等待任务A读取完操作再去执行任务B,这样无疑是对CPU资源的极大的浪费。聪明的老大们就在想若在任务A读取数据时
,让任务B执行,当任务A读取完数据后,再切换到任务A执行。注意关键字切换,自然是切换,那么这就涉及到了状态的保存,状态的恢复,加上任务A与任务B所需要的系统资源(内存,硬盘,键盘等等)是不一样的。自然而然的就
需要有一个东西去记录任务A和任务B分别需要什么资源,怎样去识别任务A和任务B等等。登登登,进程就被发明出来了。通过进程来分配系统资源,标识任务。如何分配CPU去执行进程称之为调度,进程状态的记录,恢复,切换称之
为上下文切换。进程是系统资源分配的最小单位,进程占用的资源有:地址空间,全局变量,文件描述符,各种硬件等等资源。
进程的定义
首先进程不是程序!!!
进程是个抽象的概念
进程:最小的资源单位
进程就是一个程序在一个数据集上的一次动态执行过程
进程一般由程序、数据集、进程控制块三部分组成
我们编写的程序用来描述进程要完成哪些功能以及如何完成
数据集则是程序在执行过程中需要使用的资源。
进程控制块用来记录进程的外部特征。描述进程的执行变化过程,系统可以利用它来控制和管理进程,它是系统感知进程存在的唯一标志。
进程的三种状态
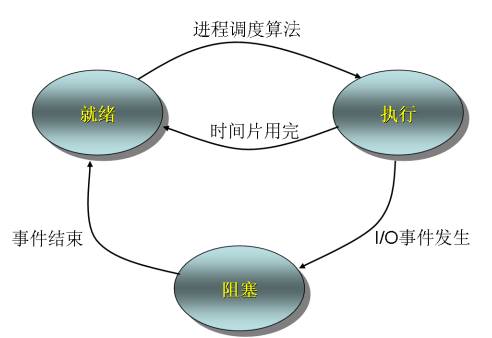
进程的再理解
1)进程上下文:进程的物理实体与支持进程运行的物理环境,包括:地址空间,系统栈,打开文件表,… 2)上下文切换:由一个进程的上下文转到另一个进程的上下文; 3)系统开销:运行操作系统程序完成系统管理工作所花费的时间和空间; 4)一个进程可以包含多个线程。
线程
前言
线程的出现是为了降低上下文切换的消耗,提高系统的并发性,并突破一个进程只能干一样事的缺陷,使到进程内并发成为可能。假设,一个文本程序,需要接受键盘输入,将内容显示在屏幕上,还需要保存信息到硬盘中。若只有一
个进程,势必造成同一时间只能干一样事的尴尬(当保存时,就不能通过键盘输入内容)。若有多个进程,每个进程负责一个任务,进程A负责接收键盘输入的任务,进程B负责将内容显示在屏幕上的任务,进程C负责保存内容到硬盘
中的任务。这里进程A,B,C间的协作涉及到了进程通信问题,而且有共同都需要拥有的东西-------文本内容,不停的切换造成性能上的损失。若有一种机制,可以使任务A,B,C共享资源,这样上下文切换所需要保存和恢复的内
容就少了,同时又可以减少通信所带来的性能损耗,那就好了。是的,这种机制就是线程。线程共享进程的大部分资源,并参与CPU的调度, 当然线程自己也是拥有自己的资源的,例如,栈,寄存器等等。 此时,进程同时也是线程
的容器。线程也是有着自己的缺陷的,例如健壮性差,若一个线程挂掉了,整一个进程也挂掉了,这意味着其它线程也挂掉了,进程却没有这个问题,一个进程挂掉,另外的进程还是活着。
线程的定义
线程:最小的执行单位
一个进程中可以开多个线程,为什么要有进程,而不做成线程呢?因为一个程序中,线程共享一套数据,如果都做成进程,每个进程独占一块内存,那这套数据就要复制好几份给每个程序,不合理,所以有了线程。 线程又叫轻量级进程,是一个基本的cpu执行单元,也是程序执行过程中的最小单元。一个进程最少也会有一个主线程,在主线程中通过threading模块,在开子线程 进程下的执行单位
而进程相当于线程的容器
也需要注意进程下面还可以继续创建进程
当然线程最大的特点就是共享这个进程的所有资源
程序运行的原理
分时调度
所有线程轮流使用 CPU 的使用权,平均分配每个线程占用 CPU 的时间。 抢占式调度
优先让优先级高的线程使用 CPU,如果线程的优先级相同,那么会随机选择一个(线程随机性),Java使用的为抢占式调度。 大部分操作系统都支持多进程并发运行,现在的操作系统几乎都支持同时运行多个程序。比如:现在我们上课一边使用编辑器,一边使用录屏软件,同时还开着画图板,dos窗口等软件。此时,这些程序是在同时运行,”感觉这些软件
好像在同一时刻运行着“。 实际上,CPU(中央处理器)使用抢占式调度模式在多个线程间进行着高速的切换。对于CPU的一个核而言,某个时刻,只能执行一个线程,而 CPU的在多个线程间切换速度相对我们的感觉要快,看上去就是在同一时刻运行。 其实,多线程程序并不能提高程序的运行速度,但能够提高程序运行效率,让CPU的使用率更高。
线程的四种状态及状态转换:
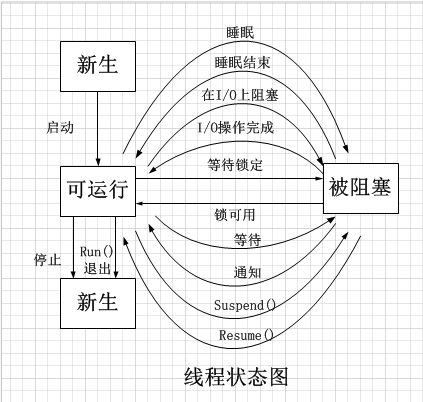
线程与进程的区别?
- 从如何创建的角度:进程是由执行程序后系统进程fork生成的,创建后生成一个PCB;线程是由父进程负责创建的,创建后生成一个TCB
- 从拥有资源的角度:进程拥有内存资源,有独立的地址空间、有独立的数据段、代码段、堆栈段;线程拥有CPU资源,也有自己的局部变量和栈
- 从通信的角度:进程之间的通信只能通过进程通信(共享内存模式、消息传递模式、共享文件模式)进行;同一进程下线程之间的通信是通过共享的数据区进行通信的
- 从执行的角度:进程可以独立执行(通过);但线程必须依附他的父进程执行
总结
1.一个程序至少有一个进程,一个进程至少有一个线程,(进程可以理解成线程的容器)
2.进程在执行过程中拥有独立的内存单元,而多个线程共享内存,从而极大地提高了程序的运行效率
3.线程在执行过程中与进程还是有区别的。每个独立的线程有一个程序运行的入口,顺序执行序列和程序的出口。但是线程不能独立执行,必须依存在应用程序中,由应用程序提供多个线程执行控制
4.进程是具有一定独立功能的程序关于某个数据集合上的一次运行活动,进程是系统进行资源分配和调度的一个独立单位
线程是进程的一个实体,是cpu调度和分配的基本单位,它是比进程更小的能独立运行的基本单位,线程自己基本不拥有系统资源,只拥有一点在运行中必不可少的资源(如程序计数器,一组寄存器和栈)但是它可与同属一个进程的
其他的线程共享进程所拥有的全部资源
5.cpu分配给线程,即真正在cpu上运行的是线程
6.一个线程可以创建和撤销另一个线程:同一个进程中的多个线程之间可以并发
并行与并发
并行
并行就是指同一时刻有两个或两个以上的“工作单位”在同时执行,从硬件的角度上来看就是同一时刻有两条或两条以上的指令处于执行阶段。所以,多核是并行的前提,单线程永远无法达到并行状态。可以利用多线程和度进程到达并
行状态。另外的,Python的多线程由于GIL的存在,对于Python来说无法通过多线程到达并行状态。 并行处理是指计算机系统中能同时执行两个或多个任务的计算方法,并行处理可同时工作于同一程序的不同方面。
并发
并发
对于并发的理解,要从两方面去理解
1.并发设计
2.并发执行。
先说并发设计,当说一个程序是并发的,更多的是指这个程序采取了并发设计。
并发设计的标准:使多个操作可以在重叠的时间段内进行 ,这里的重点在于重叠的时间内, 重叠时间可以理解为一段时间内。例如:在时间1s秒内, 具有IO操作的task1和task2都完成,这就可以说是并发执行。所以呢,单线程
也是可以做到并发运行的。当然啦,并行肯定是并发的。
一个程序能否并发执行,取决于设计,也取决于部署方式。例如, 当给程序开一个线程(协程是不开的),它不可能是并发的,因为在重叠时间内根本就没有两个task在运行。当一个程序被设计成完成一个任务再去完成下一个任务的
时候,即便部署是多线程多协程的也是无法达到并发运行的。
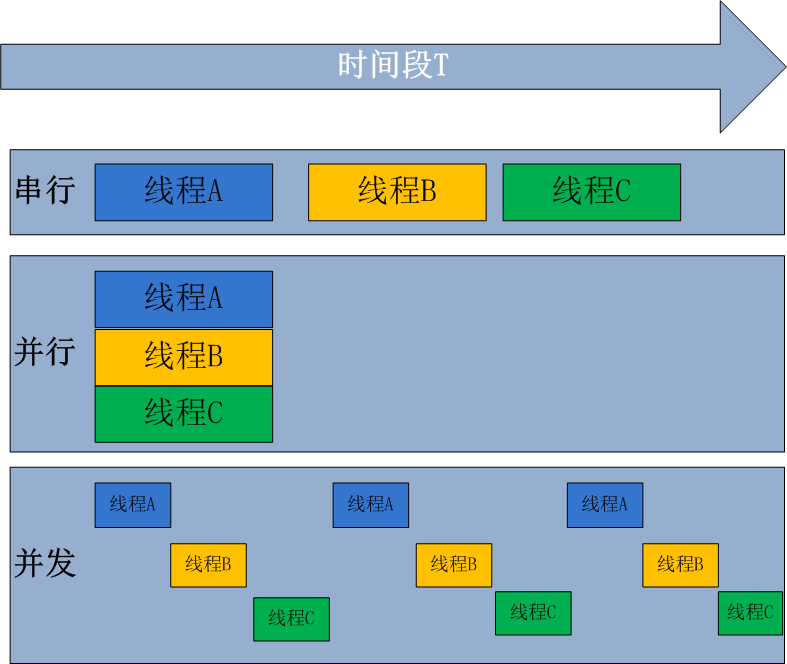
总结
并发:是指系统具有处理多个任务(动作)的能力
并行:是指系统具有同时处理多个任务(动作)的能力
并行与并发的关系: 并发的设计使到并发执行成为可能,而并行是并发执行的其中一种模式
并发处理是同一时间段内有几个程序都在一个cpu中处于运行状态,但任一时刻只有一个程序在cpu上运行。
同步与异步
同步和异步关注的是消息通信机制 (synchronous communication/ asynchronous communication)
同步
所谓同步,就是在发出一个*调用*时,在没有得到结果之前,该*调用*就不返回。但是一旦调用返回,就得到返回值了。
换句话说,就是由*调用者*主动等待这个*调用*的结果。
当进程执行到一个IO操作(等待外部数据)的时候,一直等待外部数据,接收到数据后,再继续运行
异步
异步则是相反,*调用*在发出之后,这个调用就直接返回了,所以没有返回结果。换句话说,当一个异步过程调用发出后,调用者不会立刻得到结果。而是在*调用*发出后,*被调用者*通过状态、通知来通知调用者,或通过回调函数处理这个调用。
当进程执行到一个IO操作(等待外部数据)的时候,不主动等待数据,一边执行别的任务,外部数据发送过来,接收到数据再回来继续运行。
同步查询 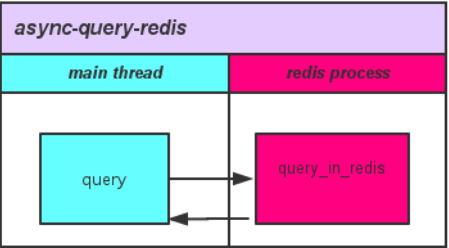 异步查询
异步查询 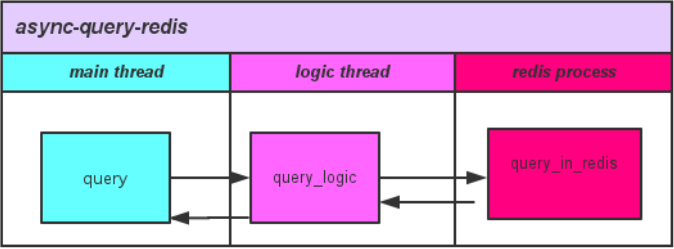
阻塞和非阻塞
阻塞和非阻塞关注的是程序在等待调用结果(消息,返回值)时的状态.
阻塞调用是指调用结果返回之前,当前线程会被挂起。调用线程只有在得到结果之后才会返回。
非阻塞调用指在不能立刻得到结果之前,该调用不会阻塞当前线程。
网络IO
1.对于网络IO主要指socket;
2.socket会在conenct/read/write时发生阻塞。
概念
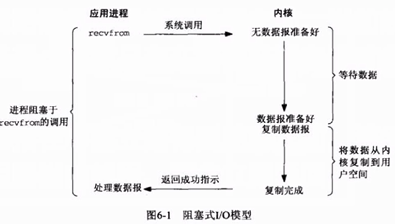
1.阻塞调用是指调用结果返回之前,当前线程会被挂起。函数只有在得到结果之后才会返回
1)connect阻塞
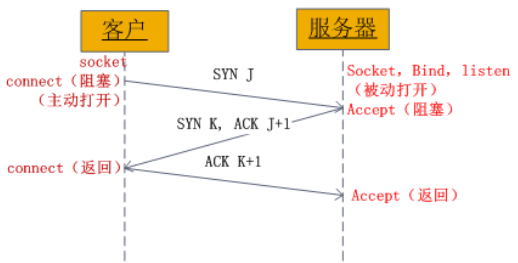
2)接收数据阻塞
2.非阻塞指在不能立刻得到结果之前,该函数不会阻塞当前线程,而会立刻返回
1)接收数据非阻塞
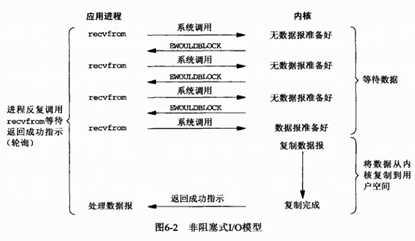
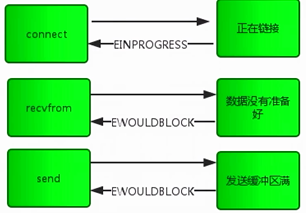
2)非阻塞面临的问题
1.同步与异步
同步和异步关注的是消息通信机制 (synchronous communication/ asynchronous communication)
所谓同步,就是在发出一个*调用*时,在没有得到结果之前,该*调用*就不返回。但是一旦调用返回,就得到返回值了。
换句话说,就是由*调用者*主动等待这个*调用*的结果。
而异步则是相反,*调用*在发出之后,这个调用就直接返回了,所以没有返回结果。换句话说,当一个异步过程调用发出后,调用者不会立刻得到结果。而是在*调用*发出后,*被调用者*通过状态、通知来通知调用者,或通过回调函数处理这个调用。
典型的异步编程模型比如Node.js
举个通俗的例子:
你打电话问书店老板有没有《分布式系统》这本书,如果是同步通信机制,书店老板会说,你稍等,”我查一下",然后开始查啊查,等查好了(可能是5秒,也可能是一天)告诉你结果(返回结果)。
而异步通信机制,书店老板直接告诉你我查一下啊,查好了打电话给你,然后直接挂电话了(不返回结果)。然后查好了,他会主动打电话给你。在这里老板通过“回电”这种方式来回调。
2. 阻塞与非阻塞
阻塞和非阻塞关注的是程序在等待调用结果(消息,返回值)时的状态.
阻塞调用是指调用结果返回之前,当前线程会被挂起。调用线程只有在得到结果之后才会返回。
非阻塞调用指在不能立刻得到结果之前,该调用不会阻塞当前线程。
还是上面的例子,
你打电话问书店老板有没有《分布式系统》这本书,你如果是阻塞式调用,你会一直把自己“挂起”,直到得到这本书有没有的结果,如果是非阻塞式调用,你不管老板有没有告诉你,你自己先一边去玩了, 当然你也要偶尔过几分钟check一下老板有没有返回结果。
在这里阻塞与非阻塞与是否同步异步无关。跟老板通过什么方式回答你结果无关。
如果是关心阻塞 IO/ 异步 IO, 参考 Unix Network Programming View Book
同步异步与阻塞,非阻塞区别 1.阻塞/非阻塞, 它们是程序在等待消息(无所谓同步或者异步)时的状态; 2.同步/异步,是程序获得关注消息通知的机制。 同步异步与阻塞,非阻塞组合 1.同步阻塞 效率最低(日志程序)。 2.同步非阻塞 效率也不高(需要轮询)。 3.异步阻塞 一般模式线程回调。 4.异步非阻塞 IOCP。
举例
老张爱喝茶,废话不说,煮开水。出场人物:老张,水壶两把(普通水壶,简称水壶;会响的水壶,简称响水壶)。
1 老张把水壶放到火上,立等水开。(同步阻塞)老张觉得自己有点傻 2 老张把水壶放到火上,去客厅看电视,时不时去厨房看看水开没有。(同步非阻塞) 老张还是觉得自己有点傻,于是变高端了,买了把会响笛的那种水壶。水开之后,能大声发出嘀~~~~的噪音。
3 老张把响水壶放到火上,立等水开。(异步阻塞)老张觉得这样傻等意义不大 4 老张把响水壶放到火上,去客厅看电视,水壶响之前不再去看它了,响了再去拿壶。(异步非阻塞)
老张觉得自己聪明了。
同步就是烧开水,要自己来看开没开;异步就是水开了,然后水壶响了通知你水开了。阻塞是烧开水的过程中,你不能干其他事情(即你被阻塞住了);非阻塞是烧开水的过程里可以干其他事情。同步与异步说的是你获得水开了的方式不同。阻塞与非阻塞说的是的你得到结果之前能不能干其他事情。
CPU密集型与IO密集型
CPU密集型(CPU-bound) CPU密集型也叫计算密集型,指的是系统的硬盘、内存性能相对CPU要好很多,此时,系统运作大部分的状况是CPU Loading 100%,CPU要读/写I/O(硬盘/内存),I/O在很短的时间就可以完成,而CPU还有许多运算要处理,CPU Loading很高。 在多重程序系统中,大部份时间用来做计算、逻辑判断等CPU动作的程序称之CPU bound。例如一个计算圆周率至小数点一千位以下的程序,在执行的过程当中绝大部份时间用在三角函数和开根号的计算,便是属于CPU bound的程序。 CPU bound的程序一般而言CPU占用率相当高。这可能是因为任务本身不太需要访问I/O设备,也可能是因为程序是多线程实现因此屏蔽掉了等待I/O的时间。 IO密集型(I/O bound) IO密集型指的是系统的CPU性能相对硬盘、内存要好很多,此时,系统运作,大部分的状况是CPU在等I/O (硬盘/内存) 的读/写操作,此时CPU Loading并不高。 I/O bound的程序一般在达到性能极限时,CPU占用率仍然较低。这可能是因为任务本身需要大量I/O操作,而pipeline做得不是很好,没有充分利用处理器能力。 CPU密集型 vs IO密集型 我们可以把任务分为计算密集型和IO密集型。 计算密集型任务的特点是要进行大量的计算,消耗CPU资源,比如计算圆周率、对视频进行高清解码等等,全靠CPU的运算能力。这种计算密集型任务虽然也可以用多任务完成,但是任务越多,花在任务切换的时间就越多,CPU执行任务的效率就越低,所以,要最高效地利用CPU,计算密集型任务同时进行的数量应当等于CPU的核心数。 计算密集型任务由于主要消耗CPU资源,因此,代码运行效率至关重要。Python这样的脚本语言运行效率很低,完全不适合计算密集型任务。对于计算密集型任务,最好用C语言编写。 第二种任务的类型是IO密集型,涉及到网络、磁盘IO的任务都是IO密集型任务,这类任务的特点是CPU消耗很少,任务的大部分时间都在等待IO操作完成(因为IO的速度远远低于CPU和内存的速度)。对于IO密集型任务,任务越多,CPU效率越高,但也有一个限度。常见的大部分任务都是IO密集型任务,比如Web应用。 IO密集型任务执行期间,99%的时间都花在IO上,花在CPU上的时间很少,因此,用运行速度极快的C语言替换用Python这样运行速度极低的脚本语言,完全无法提升运行效率。对于IO密集型任务,最合适的语言就是开发效率最高(代码量最少)的语言,脚本语言是首选,C语言最差。 总之,计算密集型程序适合C语言多线程,I/O密集型适合脚本语言开发的多线程。
挂起与阻塞
挂起:一般是主动的,由系统或程序发出,甚至于辅存中去。(不释放CPU,可能释放内存,放在外存)
阻塞:一般是被动的,在抢占资源中得不到资源,被动的挂起在内存,等待某种资源或信号量(即有了资源)将他唤醒。(释放CPU,不释放内存)
另外,有一段话很形象:
首先这些术语都是对于线程来说的。对线程的控制就好比你控制了一个雇工为你干活。你对雇工的控制是通过编程来实现的。
挂起线程的意思就是你对主动对雇工说:“你睡觉去吧,用着你的时候我主动去叫你,然后接着干活”。
使线程睡眠的意思就是你主动对雇工说:“你睡觉去吧,某时某刻过来报到,然后接着干活”。
线程阻塞的意思就是,你突然发现,你的雇工不知道在什么时候没经过你允许,自己睡觉呢,但是你不能怪雇工,肯定你 这个雇主没注意,本来你让雇工扫地,结果扫帚被偷了或被邻居家借去了,你又没让雇工继续干别的活,他就只好睡觉了。至于扫帚回来后,雇工会不会知道,会不会继续干活,你不用担心,雇工一旦发现扫帚回来了,他就会自己去干活的。因为雇工受过良好的培训。这个培训机构就是操作系统。
挂 起 进程在操作系统中可以定义为暂时被淘汰出内存的进程,机器的资源是有限的,在资源不足的情况下,操作系统对在内存中的程序进行合理的安排,其中有的进程被暂时调离出内存,当条件允许的时候,会被操作系统再次调回内存,重新进入等待被执行的状态即就绪态,系统在超过一定的时间没有任何动作.
操作系统为什么要引入挂起状态?挂起状态涉及到中级调度,因为当内存中的某个程序需要大的内存空间来执行,但这时内存有没有空余空间了,那么操作系统就回根据调度算法把一些进程放到外存中去,以腾出空间给正在执行的程序的数据和程序,所以引如了挂起状态。引起挂起状态的原因有如下几方面:
(1)终端用户的请求。当终端用户在自己的程序运行期间发现有可疑问题时,希望暂停使自己的程序静止下来。亦即,使正在执行的进程暂停执行;若此时用户进程正处于就绪状态而未执行,则该进程暂不接受调度,以便用户研究其执行情况或对程序进行修改。我们把这种静止状态成为“挂起状态”。
(2)父进程的请求。有时父进程希望挂起自己的某个子进程,以便考察和修改子进程,或者协调各子进程间的活动。
(3)负荷调节的需要。当实时系统中的工作负荷较重,已可能影响到对实时任务的控制时,可由系统把一些不重要的进程挂起,以保证系统能正常运行。
(4)操作系统的需要。操作系统有时希望挂起某些进程,以便检查运行中的资源使用情况或进行记账。
(5)对换的需要。为了缓和内存紧张的情况,将内存中处于阻塞状态的进程换至外存上。
下面再说下进程和线程的状态:
进程:一般大家认为是三种状态:运行、阻塞、就绪。也有分为五态的(多了创建和退出状态)
线程:一般认为是四种状态:New Thread(not alive)、Runnable Thread(alive)、Blocked Thread(alive)、Dead Thread(not alive)
python网络编程基础(线程与进程、并行与并发、同步与异步、阻塞与非阻塞、CPU密集型与IO密集型)的更多相关文章
- Python网络编程之线程,进程
一. 线程: 基本使用 线程锁 线程池 队列(生产者消费者模型) 二. 进程: 基本使用 进程锁 进程池 进程数据共享 三. 协程: gevent greenlet 四. 缓存: memcache ...
- Python网络编程基础|百度网盘免费下载|零基础入门学习资料
百度网盘免费下载:Python网络编程基础|零基础学习资料 提取码:k7a1 目录: 第1部分 底层网络 第1章 客户/服务器网络介绍 第2章 网络客户端 第3章 网络服务器 第4章 域名系统 第5章 ...
- Python网络编程基础pdf
Python网络编程基础(高清版)PDF 百度网盘 链接:https://pan.baidu.com/s/1VGwGtMSZbE0bSZe-MBl6qA 提取码:mert 复制这段内容后打开百度网盘手 ...
- 好书推荐---Python网络编程基础
Python网络编程基础详细的介绍了网络编程的相关知识,结合python,看起来觉得很顺畅!!!
- python网络编程基础
一.客户端/服务器架构 网络中到处都应有了C/S架构,我们学习socket就是为了完成C/S架构的开发. 二.scoket与网络协议 如果想要实现网络通信我们需要对tcpip,http等很多网络知识有 ...
- python网络编程基础(一)
一.C/S架构 客户端/服务端架构 二.OSI七层架构 七层模型,亦称OSI(Open System Interconnection)参考模型,是参考模型是国际标准化组织(ISO)制定的一个用于计算机 ...
- Python网络编程基础 PDF 完整超清版|网盘链接内附提取码下载|
点此获取下载地址提取码:y9u5 Python网络编程最好新手入门书籍!175个详细案例,事实胜于雄辩,Sockets.DNS.Web Service.FTP.Email.SMTP.POP.IMAP. ...
- Python网络编程(线程通信、GIL、服务器模型)
什么是进程.进程的概念? 进程的概念主要有两点: 第一,进程是一个实体.每一个进程都有它自己的地址空间, 一般情况下,包括文本区域(text region).数据区域(data region)和堆栈( ...
- 第九章:Python の 网络编程基础(一)
本課主題 何为TCP/IP协议 初认识什么是网络编程 网络编程中的 "粘包" 自定义 MySocket 类 本周作业 何为TCP/IP 协议 TCP/IP协议是主机接入互网以及接入 ...
随机推荐
- D - 文理分科 (网络流->最小割)
题目链接:https://cn.vjudge.net/contest/281959#problem/D 题目大意:中文题目 具体思路:我们需要求出最大的满意值,从另一方面想,我们可以求出总的满意值,然 ...
- linux相关设置
mysql开机自启: [root@workstudio system]# systemctl enable mysqld
- android 服务解析
https://blog.csdn.net/luoyanglizi/article/details/51586437 2.service和Thread的区别 定义上: thread是程序运行的最小单元 ...
- GNU/Linux的GNU是什么意思
这个组织中黑客云集,而且多是掌握核心技术的真正高手,他们的作品多是编译器.词法/语法分析器.底层函数库等大作.更重要的不是他们的技术,而是他们的哲学!他们的哲学就是技术上的“共产主义”——人人为我,我 ...
- jq常用功能操作
//表示所有选中的商品 var $goods=$(".goods:checked"); var arr=[]; for(i=0;i<$goods.length;i++){ a ...
- kafka系列三、Kafka三款监控工具比较
转载原文:http://top.jobbole.com/31084/ 通过研究,发现主流的三种kafka监控程序分别为: Kafka Web Conslole Kafka Manager KafkaO ...
- nagios系列(八)之nagios通过nsclient监控windows主机
nagios通过nsclient监控windows主机 1.下载NSClient -0.3.8-Win32.rar安装在需要被监控的windows主机中 可以设置密码,此处密码留空 2.通过在nagi ...
- Android用户界面开发:Fragment
Android用户界面开发:Fragment 1:注意事项 3.0以前的Android 版本要使用FragmentActivity 来装载Fragment ,使用到support v4包. 3.0 ...
- selenium python2.7安装配置
1:安装python python2.7版本(最新的python版本是3.4,但用户体验没有2.7版本的好,我们选择用2.7版本) 下载地址:https://www.python.org/downlo ...
- Day6------------复习
文件归档:tar cvf test.tar 文件压缩:gzip 目标文件 bzip2 test,tar 文件解压:gunzip test.tar.gz bzip2 test.tar.bz2 文件打包压 ...