HBase(八)HBase的协处理器
一、协处理器简介
1、 起源
Hbase 作为列族数据库最经常被人诟病的特性包括:无法轻易建立“二级索引”,难以执 行求和、计数、排序等操作。比如,在旧版本的(<0.92)Hbase 中,统计数据表的总行数,需 要使用 Counter 方法,执行一次 MapReduce Job 才能得到。虽然 HBase 在数据存储层中集成 了 MapReduce,能够有效用于数据表的分布式计算。然而在很多情况下,做一些简单的相 加或者聚合计算的时候,如果直接将计算过程放置在 server 端,能够减少通讯开销,从而获 得很好的性能提升。于是,HBase 在 0.92 之后引入了协处理器(coprocessors),实现一些激动 人心的新特性:能够轻易建立二次索引、复杂过滤器(谓词下推)以及访问控制等。
2、介绍
协处理器有两种:observer 和 endpoint
Observer 类似于传统数据库中的触发器,当发生某些事件的时候这类协处理器会被 Server 端调用。Observer Coprocessor 就是一些散布在 HBase Server 端代码中的 hook 钩子, 在固定的事件发生时被调用。比如:put 操作之前有钩子函数 prePut,该函数在 put 操作执 行前会被 Region Server 调用;在 put 操作之后则有 postPut 钩子函数
以 HBase0.92 版本为例,它提供了三种观察者接口:
RegionObserver:提供客户端的数据操纵事件钩子:Get、Put、Delete、Scan 等。
WALObserver:提供 WAL 相关操作钩子。
MasterObserver:提供 DDL-类型的操作钩子。如创建、删除、修改数据表等。
到 0.96 版本又新增一个 RegionServerObserver
下图是以 RegionObserver 为例子讲解 Observer 这种协处理器的原理:
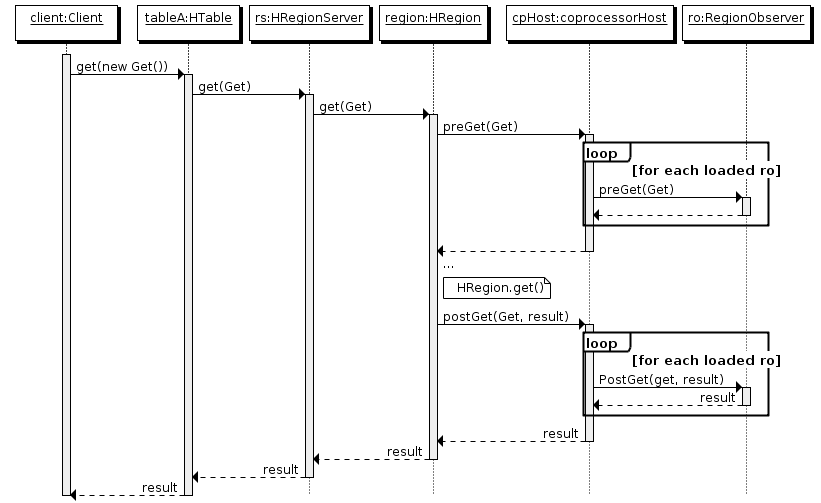
1、客户端发出 put 请求
2、该请求被分派给合适的 RegionServer 和 region
3、coprocessorHost 拦截该请求,然后在该表上登记的每个 RegionObserver 上调用 prePut()
4、如果没有被 prePut()拦截,该请求继续送到 region,然后进行处理
5、region 产生的结果再次被 CoprocessorHost 拦截,调用 postPut()
6、假如没有 postPut()拦截该响应,最终结果被返回给客户端
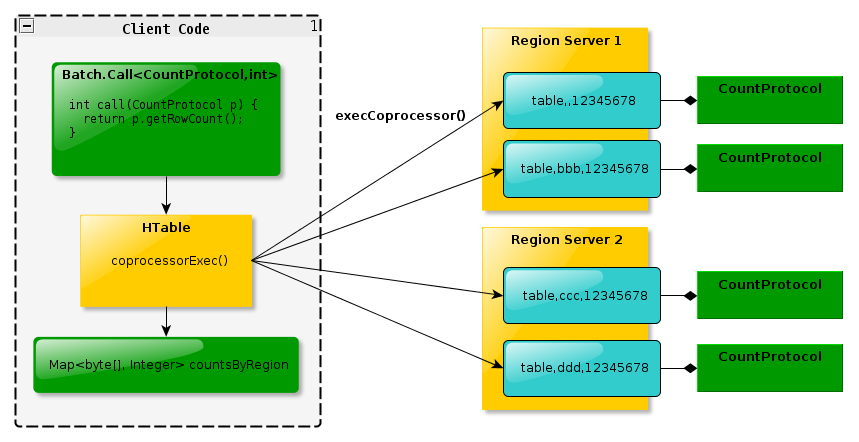
Endpoint 协处理器类似传统数据库中的存储过程,客户端可以调用这些 Endpoint 协处 理器执行一段 Server 端代码,并将 Server 端代码的结果返回给客户端进一步处理,最常见 的用法就是进行聚集操作。如果没有协处理器,当用户需要找出一张表中的最大数据,即 max 聚合操作,就必须进行全表扫描,在客户端代码内遍历扫描结果,并执行求最大值的 操作。这样的方法无法利用底层集群的并发能力,而将所有计算都集中到 Client 端统一执行, 势必效率低下。利用 Coprocessor,用户可以将求最大值的代码部署到 HBase Server 端,HBase 将利用底层 cluster 的多个节点并发执行求最大值的操作。即在每个 Region 范围内执行求最 大值的代码,将每个 Region 的最大值在 Region Server 端计算出,仅仅将该 max 值返回给客 户端。在客户端进一步将多个 Region 的最大值进一步处理而找到其中的最大值。这样整体 的执行效率就会提高很多
下图是 EndPoint 的工作原理:
3、总结
Observer 允许集群在正常的客户端操作过程中可以有不同的行为表现
Endpoint 允许扩展集群的能力,对客户端应用开放新的运算命令
Observer 类似于 RDBMS 中的触发器,主要在服务端工作
Endpoint 类似于 RDBMS 中的存储过程,主要在服务端工作
Observer 可以实现权限管理、优先级设置、监控、ddl 控制、二级索引等功能
Endpoint 可以实现 min、max、avg、sum、distinct、group by 等功能
二、协处理加载方式
协处理器的加载方式有两种,我们称之为静态加载方式(Static Load)和动态加载方式 (Dynamic Load)。静态加载的协处理器称之为 System Coprocessor,动态加载的协处理器称 之为 Table Coprocessor。
1、 静态加载
通过修改 hbase-site.xml 这个文件来实现,启动全局 aggregation,能过操纵所有的表上 的数据。只需要添加如下代码:
<property>
<name>hbase.coprocessor.user.region.classes</name>
<value>org.apache.hadoop.hbase.coprocessor.AggregateImplementation</value>
</property>
为所有 table 加载了一个 cp class,可以用”,”分割加载多个 class
2、 动态加载
启用表 aggregation,只对特定的表生效。通过 HBase Shell 来实现。
(1)停用表 disable 'guanzhu'
(2)添加协处理器 alter 'guanzhu', METHOD => 'table_att', 'coprocessor' => 'hdfs://myha01/hbase/guanzhu.jar|com.study.hbase.cp.HbaseCoprocessorTest|1001|'
(3)启用表 enable 'guanzhu'
3、 协处理器卸载
同样是3步
disable 'mytable'
alter 'mytable',METHOD=>'table_att_unset',NAME=>'coprocessor$1'
enable 'mytable'
案例(二级索引)
说明:二狗子是王宝强的粉丝
关注表:二狗子关注了王宝强 rowKey='ergouzi' cell="star:wangbaoqiang"
put 'guanzhu', 'ergouzi', 'cf:star', 'wangbaoqiang'
粉丝表:二狗子是王宝强的粉丝 rowKey="wangbaoqiang" cell="fensi:ergouzi"
put 'fans', 'wangbaoqiang', 'cf:fensi', 'ergouzi'
java实现代码
public class HbaseCoprocessorTest extends BaseRegionObserver{
static Configuration conf = HBaseConfiguration.create();
static Connection conn = null;
static Table table = null;
static {
conf.set("hbase.zookeeper.quorum", "hadoop1:2181,hadoop2:2181,hadoop3:2181");
try {
conn = ConnectionFactory.createConnection(conf);
table = conn.getTable(TableName.valueOf("fans"));
} catch (IOException e) {
e.printStackTrace();
}
}
/**
* 此方法是在真正的put方法调用之前进行调用
* 参数put为table.put(put)里面的参数put对象,是要进行插入的那条数据
*
* 例如:要向关注表里面插入一条数据 姓名:二狗子 关注的明星:王宝强
* shell语句:put 'guanzhu','ergouzi', 'cf:star', 'wangbaoqiang'
*
* */
@Override
public void prePut(ObserverContext<RegionCoprocessorEnvironment> e, Put put, WALEdit edit, Durability durability)
throws IOException {
//获取put对象里面的rowkey'ergouzi'
byte[] row = put.getRow();
//获取put对象里面的cell
List<Cell> list = put.get("cf".getBytes(), "star".getBytes());
Cell cell = list.get(0);
//创建一个新的put对象
Put new_put = new Put(cell.getValueArray());
new_put.addColumn("cf".getBytes(), "fensi".getBytes(), row);
table.put(new_put);
conn.close();
}
}
打成jar包,命名为guanzhu.jar,将其上传到HDFS目录/hbase下面
[hadoop@hadoop1 ~]$ hadoop fs -put guanzhu.jar /hbase
打开hbase shell命令,按顺序呢执行(提前已经创建好guanzhu和fans表)
hbase(main):001:0> disable 'guanzhu'
0 row(s) in 2.8850 seconds hbase(main):002:0> alter 'guanzhu', METHOD => 'table_att', 'coprocessor' => 'hdfs://myha01/hbase/guanzhu.jar|com.study.hbase.cp.HbaseCoprocessorTest|1001|'
Updating all regions with the new schema...
1/1 regions updated.
Done.
0 row(s) in 2.7570 seconds hbase(main):003:0> enable 'guanzhu'
0 row(s) in 2.3400 seconds hbase(main):004:0> desc 'guanzhu'
Table guanzhu is ENABLED
guanzhu, {TABLE_ATTRIBUTES => {coprocessor$1 => 'hdfs://myha01/hbase/guanzhu.jar|com.study.hbase.cp.HbaseCoproce
ssorTest|1001|'}
COLUMN FAMILIES DESCRIPTION
{NAME => 'cf', BLOOMFILTER => 'ROW', VERSIONS => '1', IN_MEMORY => 'false', KEEP_DELETED_CELLS => 'FALSE', DATA_
BLOCK_ENCODING => 'NONE', TTL => 'FOREVER', COMPRESSION => 'NONE', MIN_VERSIONS => '0', BLOCKCACHE => 'true', BL
OCKSIZE => '65536', REPLICATION_SCOPE => '0'}
1 row(s) in 0.0500 seconds hbase(main):005:0> put 'guanzhu', 'ergouzi', 'cf:star', 'wangbaoqiang'
0 row(s) in 0.3050 seconds hbase(main):006:0> scan 'guanzhu'
ROW COLUMN+CELL
ergouzi column=cf:star, timestamp=1522759023001, value=wangbaoqiang
1 row(s) in 0.0790 seconds hbase(main):007:0> scan 'fans'
ROW COLUMN+CELL
\x00\x00\x00\x19\x00\x00\x00 column=cf:fensi, timestamp=1522759022996, value=ergouzi
\x0C\x00\x07ergouzi\x02cfsta
r\x7F\xFF\xFF\xFF\xFF\xFF\xF
F\xFF\x04wangbaoqiang
1 row(s) in 0.0330 seconds hbase(main):008:0>
HBase(八)HBase的协处理器的更多相关文章
- HBase(八): 表结构设计优化
在 HBase(六): HBase体系结构剖析(上) 介绍过,Hbase创建表时,只需指定表名和至少一个列族,基于HBase表结构的设计优化主要是基于列族级别的属性配置,如下图: 目录: BLOOMF ...
- 区分 hdfs hbase hive hbase适用场景
区分 hdfs hbase hive hbase适用场景 收藏 八戒_o 发表于 11个月前 阅读 308 收藏 1 点赞 0 评论 0 摘要: hdfs hbase hive hbase适用场景 H ...
- 【HBase】HBase Getting Started(HBase 入门指南)
入门指南 1. 简介 Quickstart 会让你启动和运行一个单节点单机HBase. 2. 快速启动 – 单点HBase 这部分描述单节点单机HBase的配置.一个单例拥有所有的HBase守护线程- ...
- Hbase总结(一)-hbase命令,hbase安装,与Hive的区别,与传统数据库的区别,Hbase数据模型
Hbase总结(一)-hbase命令 下面我们看看HBase Shell的一些基本操作命令,我列出了几个常用的HBase Shell命令,如下: 名称 命令表达式 创建表 create '表名称', ...
- HBase学习-HBase原理
1.系统架构 1.1 图解 从HBase的架构图上可以看出,HBase中的组件包括Client.Zookeeper.HMaster.HRegionServer.HRegion.Store.MemS ...
- Hbase理论&&hbase shell&&python操作hbase&&python通过mapreduce操作hbase
一.Hbase搭建: 二.理论知识介绍: 1Hbase介绍: Hbase是分布式.面向列的开源数据库(其实准确的说是面向列族).HDFS为Hbase提供可靠的底层数据存储服务,MapReduce为Hb ...
- Hbase启动hbase shell运行命令报Class path contains multiple SLF4J bindings.错误
1:Hbase启动hbase shell运行命令报Class path contains multiple SLF4J bindings.错误,是因为jar包冲突了,所以对于和hadoop的jar包冲 ...
- Hbase记录-Hbase shell使用
HBase Shell HBase包含可以与HBase进行通信的Shell. HBase使用Hadoop文件系统来存储数据.它拥有一个主服务器和区域服务器.数据存储将在区域(表)的形式.这些区域被分割 ...
- Hbase记录-Hbase基础概念
HBase是什么? HBase是建立在Hadoop文件系统之上的分布式面向列的数据库.它是一个开源项目,是横向扩展的. HBase是一个数据模型,类似于谷歌的大表设计,可以提供快速随机访问海量结构化数 ...
- File /hbase/.tmp/hbase.version could only be replicated to 0 nodes instead of minReplication (=1).
File /hbase/.tmp/hbase.version could only be replicated to 0 nodes instead of minReplication (=1). 这 ...
随机推荐
- Linux各种重要配置文件详解
1:网卡文件/etc/sysconfig/network-scripts/ifcfg-eth0 [root@Gin scripts]# cat /etc/sysconfig/network-scrip ...
- python基础之collections模块
Counter Counter是一个简单的计数器,可以统计一段字符串中各个元素出现的次数: import collections counter_1=collections.Counter('kjsd ...
- Hadoop基础-HDFS分布式文件系统的存储
Hadoop基础-HDFS分布式文件系统的存储 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 一.HDFS数据块 1>.磁盘中的数据块 每个磁盘都有默认的数据块大小,这个磁盘 ...
- Java基础-MySQL数据库扫盲篇
Java基础-MySQL数据库扫盲篇 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 一.数据库概述 1>.什么是数据库 数据库就是存储数据的仓库,其本质是一个文件系统,数据按 ...
- springmvc转springboot过程中访问jsp报Whitelabel Error Page错误
前言: 虽然springboot内嵌了一个tomcat,但是这个内嵌的tomcat不支持jsp页面,所以需要引入其他包 解决: maven引入以下包即可 <dependency> < ...
- phpcms 仿站小结
1.title<title>{if isset($SEO['title']) && !empty($SEO['title'])}{$SEO['title']}{/if}{$ ...
- DNS域传送漏洞
nslookup -type=ptr 8.8.8.8 #查询一个IP地址对应的域名 nslookup -type=ns baidu.com #查询baidu.c ...
- DataTable转任意类型对象List数组-----工具通用类(利用反射和泛型)
public class ConvertHelper<T> where T : new() { /// <summary> /// 利用反射和泛型 /// </summa ...
- 20155303 2016-2017-2 《Java程序设计》第一周学习总结
20155303 2016-2017-2 <Java程序设计>第一周学习总结 教材学习内容总结 浏览教材,根据自己的理解每章提出一个问题 Chapter1 Java平台概论:MyProgr ...
- Android获取手机分辨率DisplayMetircs类
关于Android中手机分辨率的使用 Android 可设置为随着窗口大小调整缩放比例,但即便如此,手机程序设计人员还是必须知道手机屏幕的边界,以避免缩放造成的布局变形问题. 手机的分辨率信息是手机的 ...