机器学习简史brief history of machine learning
BRIEF HISTORY OF MACHINE LEARNING
 My subjective ML timeline (click for larger)
My subjective ML timeline (click for larger)
Since the initial standpoint of science, technology and AI, scientists following Blaise Pascal and Von Leibniz ponder about a machine that is intellectually capable as much as humans. Famous writers like JulesVerne , Frank Baum (Wizard of OZ), Marry Shelly (Frankenstein), George Lucas (Star Wars) dreamed artificial beings resembling human behaviors or even more, swamp humanized skills in different contexts.
 Pascal's machine performing subtraction and summation - 1642
Pascal's machine performing subtraction and summation - 1642
Machine Learning is one of the important lanes of AI which is very spicy hot subject in the research or industry. Companies, universities devote many resources to advance their knowledge. Recent advances in the field propel very solid results for different tasks, comparable to human performance (98.98% at Traffic Signs - higher than human-).
Here I would like to share a crude timeline of Machine Learning and sign some of the milestones by no means complete. In addition, you should add "up to my knowledge" to beginning of any argument in the text.
First step toward prevalent ML was proposed by Hebb, in 1949, based on a neuropsychological learning formulation. It is called Hebbian Learning theory. With a simple explanation, it pursues correlations between nodes of a Recurrent Neural Network (RNN). It memorizes any commonalities on the network and serves like a memory later. Formally, the argument states that;
Let us assume that the persistence or repetition of a reverberatory activity (or "trace") tends to induce lasting cellular changes that add to its stability.… When an axon of cell A is near enough to excite a cell B and repeatedly or persistently takes part in firing it, some growth process or metabolic change takes place in one or both cells such that A's efficiency, as one of the cells firing B, is increased.[1]
 Arthur Samuel
Arthur Samuel
In 1952, Arthur Samuel at IBM, developed a program playing Checkers. The program was able to observe positions and learn a implicit model that gives better moves for the latter cases. Samuel played so many games with the program and observed that the program was able to play better in the course of time.
With that program Samuel confuted the general providence dictating machines cannot go beyond the written codes and learn patterns like human-beings. He coined “machine learning, ” which he defines as;
a field of study that gives computer the ability without being explicitly programmed.
 F. Rosenblatt
F. Rosenblatt
In 1957, Rosenblatt's Perceptron was the second model proposed again with neuroscientific background and it is more similar to today's ML models. It was a very exciting discovery at the time and it was practically more applicable than Hebbian's idea. Rosenblatt introduced the Perceptron with the following lines;
The perceptron is designed to illustrate some of the fundamental properties of intelligent systems in general, without becoming too deeply enmeshed in the special, and frequently unknown, conditions which hold for particular biological organisms.[2]
After 3 years later, Widrow [4] engraved Delta Learning rule that is then used as practical procedure for Perceptron training. It is also known as Least Square problem. Combination of those two ideas creates a good linear classifier. However, Perceptron's excitement was hinged by Minsky[3] in 1969 . He proposed the famous XOR problem and the inability of Perceptrons in such linearly inseparable data distributions. It was the Minsky's tackle to NN community. Thereafter, NN researches would be dormant up until 1980s
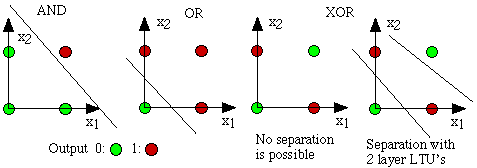 XOR problem which is nor linearly seperable data orientation
XOR problem which is nor linearly seperable data orientation
There had been not to much effort until the intuition of Multi-Layer Perceptron (MLP) was suggested by Werbos[6] in 1981 with NN specific Backpropagation(BP) algorithm, albeit BP idea had been proposed before by Linnainmaa [5] in 1970 in the name "reverse mode of automatic differentiation". Still BP is the key ingredient of today's NN architectures. With those new ideas, NN researches accelerated again. In 1985 - 1986 NN researchers successively presented the idea ofMLP with practical BP training (Rumelhart, Hinton, Williams [7] - Hetch, Nielsen[8])
 From Hetch and Nielsen [8]At the another spectrum, a very-well known ML algorithm was proposed by J. R. Quinlan [9] in 1986 that we callDecision Trees, more specifically ID3 algorithm. This was the spark point of the another mainstream ML. Moreover, ID3 was also released as a software able to find more real-life use case with its simplistic rules and its clear inference, contrary to still black-box NN models.
From Hetch and Nielsen [8]At the another spectrum, a very-well known ML algorithm was proposed by J. R. Quinlan [9] in 1986 that we callDecision Trees, more specifically ID3 algorithm. This was the spark point of the another mainstream ML. Moreover, ID3 was also released as a software able to find more real-life use case with its simplistic rules and its clear inference, contrary to still black-box NN models.
After ID3, many different alternatives or improvements have been explored by the community (e.g. ID4, Regression Trees, CART ...) and still it is one of the active topic in ML.
 From Quinlan [9]One of the most important ML breakthrough was Support Vector Machines (Networks) (SVM), proposed by Vapnik and Cortes[10] in1995 with very strong theoretical standing and empirical results. That was the time separating the ML community into two crowds as NN or SVM advocates. However the competition between two community was not very easy for the NN side after Kernelized version of SVM bynear 2000s .(I was not able to find the first paper about the topic), SVM got the best of many tasks that were occupied by NN models before. In addition, SVM was able to exploit all the profound knowledge of convex optimization, generalization margin theory and kernels against NN models. Therefore, it could find large push from different disciplines causing very rapid theoretical and practical improvements.
From Quinlan [9]One of the most important ML breakthrough was Support Vector Machines (Networks) (SVM), proposed by Vapnik and Cortes[10] in1995 with very strong theoretical standing and empirical results. That was the time separating the ML community into two crowds as NN or SVM advocates. However the competition between two community was not very easy for the NN side after Kernelized version of SVM bynear 2000s .(I was not able to find the first paper about the topic), SVM got the best of many tasks that were occupied by NN models before. In addition, SVM was able to exploit all the profound knowledge of convex optimization, generalization margin theory and kernels against NN models. Therefore, it could find large push from different disciplines causing very rapid theoretical and practical improvements.
 From Vapnik and Cortes [10]NN took another damage by the work of Hochreiter's thesis [40] in 1991 and Hochreiter et. al.[11] in 2001, showing the gradient loss after the saturation of NN units as we apply BP learning. Simply means, it is redundant to train NN units after a certain number of epochs owing to saturated units hence NNs are very inclined to over-fit in a short number of epochs.
From Vapnik and Cortes [10]NN took another damage by the work of Hochreiter's thesis [40] in 1991 and Hochreiter et. al.[11] in 2001, showing the gradient loss after the saturation of NN units as we apply BP learning. Simply means, it is redundant to train NN units after a certain number of epochs owing to saturated units hence NNs are very inclined to over-fit in a short number of epochs.
Little before, another solid ML model was proposed by Freund and Schapire in 1997 prescribed with boosted ensemble of weak classifiers called Adaboost. This work also gave the Godel Prize to the authors at the time. Adaboost trains weak set of classifiers that are easy to train, by giving more importance to hard instances. This model still the basis of many different tasks like face recognition and detection. It is also a realization of PAC (Probably Approximately Correct) learning theory. In general, so called weak classifiers are chosen as simple decision stumps (single decision tree nodes). They introduced Adaboost as ;
The model we study can be interpreted as a broad, abstract extension of the well-studied on-line prediction model to a general decision-theoretic setting...[11]
Another ensemble model explored by Breiman [12] in 2001 that ensembles multiple decision trees where each of them is curated by a random subset of instances and each node is selected from a random subset of features. Owing to its nature, it is called Random Forests(RF). RF has also theoretical and empirical proofs of endurance against over-fitting. Even AdaBoost shows weakness to over-fitting and outlier instances in the data, RF is more robust model against these caveats.(For more detail about RF, refer to my old post.). RF shows its success in many different tasks like Kaggle competitions as well.
Random forests are a combination of tree predictors such that each tree depends on the values of a
random vector sampled independently and with the same distribution for all trees in the forest. The generalization error for forests converges a.s. to a limit as the number of trees in the forest becomes large[12]
As we come closer today, a new era of NN called Deep Learning has been commerced. This phrase simply refers NN models with many wide successive layers. The 3rd rise of NN has begun roughly in 2005 with the conjunction of many different discoveries from past and present by recent mavens Hinton, LeCun, Bengio, Andrew Ng and other valuable older researchers. I enlisted some of the important headings (I guess, I will dedicate complete post for Deep Learning specifically) ;
- GPU programming
- Convolutional NNs [18][20][40]
- Deconvolutional Networks [21]
- Optimization algorithms
- Stochastic Gradient Descent [19][22]
- BFGS and L-BFGS [23]
- Conjugate Gradient Descent [24]
- Backpropagation [40][19]
- Rectifier Units
- Sparsity [15][16]
- Dropout Nets [26]
- Maxout Nets [25]
- Unsupervised NN models [14]
- Deep Belief Networks [13]
- Stacked Auto-Encoders [16][39]
- Denoising NN models [17]
With the combination of all those ideas and non-listed ones, NN models are able to beat off state of art at very different tasks such as Object Recognition, Speech Recognition, NLP etc. However, it should be noted that this absolutely does not mean, it is the end of other ML streams. Even Deep Learning success stories grow rapidly , there are many critics directed to training cost and tuning exogenous parameters of these models. Moreover, still SVM is being used more commonly owing to its simplicity. (said but may cause a huge debate  )
)
Before finish, I need to touch on one another relatively young ML trend. After the growth of WWW and Social Media, a new term, BigData emerged and affected ML research wildly. Because of the large problems arising from BigData , many strong ML algorithms are useless for reasonable systems (not for giant Tech Companies of course). Hence, research people come up with a new set of simple models that are dubbed Bandit Algorithms [27 - 38] (formally predicated with Online Learning) that makes learning easier and adaptable for large scale problems.
I would like to conclude this infant sheet of ML history. If you found something wrong (you should ), insufficient or non-referenced, please don't hesitate to warn me in all manner.
References ----
[1] Hebb D. O., The organization of behaviour.New York: Wiley & Sons.
[2]Rosenblatt, Frank. "The perceptron: a probabilistic model for information storage and organization in the brain." Psychological review 65.6 (1958): 386.
[3]Minsky, Marvin, and Papert Seymour. "Perceptrons." (1969).
[4]Widrow, Hoff "Adaptive switching circuits." (1960): 96-104.
[5]S. Linnainmaa. The representation of the cumulative rounding error of an algorithm as a Taylor
expansion of the local rounding errors. Master’s thesis, Univ. Helsinki, 1970.
[6] P. J. Werbos. Applications of advances in nonlinear sensitivity analysis. In Proceedings of the 10th
IFIP Conference, 31.8 - 4.9, NYC, pages 762–770, 1981.
[7] Rumelhart, David E., Geoffrey E. Hinton, and Ronald J. Williams. Learning internal representations by error propagation. No. ICS-8506. CALIFORNIA UNIV SAN DIEGO LA JOLLA INST FOR COGNITIVE SCIENCE, 1985.
[8] Hecht-Nielsen, Robert. "Theory of the backpropagation neural network." Neural Networks, 1989. IJCNN., International Joint Conference on. IEEE, 1989.
[9] Quinlan, J. Ross. "Induction of decision trees." Machine learning 1.1 (1986): 81-106.
[10] Cortes, Corinna, and Vladimir Vapnik. "Support-vector networks." Machine learning 20.3 (1995): 273-297.
[11] Freund, Yoav, Robert Schapire, and N. Abe. "A short introduction to boosting."Journal-Japanese Society For Artificial Intelligence 14.771-780 (1999): 1612.
[12] Breiman, Leo. "Random forests." Machine learning 45.1 (2001): 5-32.
[13] Hinton, Geoffrey E., Simon Osindero, and Yee-Whye Teh. "A fast learning algorithm for deep belief nets." Neural computation 18.7 (2006): 1527-1554.
[14] Bengio, Lamblin, Popovici, Larochelle, "Greedy Layer-Wise
Training of Deep Networks", NIPS’2006
[15] Ranzato, Poultney, Chopra, LeCun " Efficient Learning of Sparse Representations with an Energy-Based Model ", NIPS’2006
[16] Olshausen B a, Field DJ. Sparse coding with an overcomplete basis set: a strategy employed by V1? Vision Res. 1997;37(23):3311–25. Available at: http://www.ncbi.nlm.nih.gov/pubmed/9425546.
[17] Vincent, H. Larochelle Y. Bengio and P.A. Manzagol, Extracting and Composing Robust Features with Denoising Autoencoders, Proceedings of the Twenty-fifth International Conference on Machine Learning (ICML‘08), pages 1096 - 1103, ACM, 2008.
[18] Fukushima, K. (1980). Neocognitron: A self-organizing neural network model for a mechanism of pattern recognition unaffected by shift in position. Biological Cybernetics, 36, 193–202.
[19] LeCun, Yann, et al. "Gradient-based learning applied to document recognition."Proceedings of the IEEE 86.11 (1998): 2278-2324.
[20] LeCun, Yann, and Yoshua Bengio. "Convolutional networks for images, speech, and time series." The handbook of brain theory and neural networks3361 (1995).
[21] Zeiler, Matthew D., et al. "Deconvolutional networks." Computer Vision and Pattern Recognition (CVPR), 2010 IEEE Conference on. IEEE, 2010.
[22] S. Vishwanathan, N. Schraudolph, M. Schmidt, and K. Mur- phy. Accelerated training of conditional random fields with stochastic meta-descent. In International Conference on Ma- chine Learning (ICML ’06), 2006.
[23] Nocedal, J. (1980). ”Updating Quasi-Newton Matrices with Limited Storage.” Mathematics of Computation 35 (151): 773782. doi:10.1090/S0025-5718-1980-0572855-
[24] S. Yun and K.-C. Toh, “A coordinate gradient descent method for l1- regularized convex minimization,” Computational Optimizations and Applications, vol. 48, no. 2, pp. 273–307, 2011.
[25] Goodfellow I, Warde-Farley D. Maxout networks. arXiv Prepr arXiv …. 2013. Available at: http://arxiv.org/abs/1302.4389. Accessed March 20, 2014.
[26] Wan L, Zeiler M. Regularization of neural networks using dropconnect. Proc …. 2013;(1). Available at: http://machinelearning.wustl.edu/mlpapers/papers/icml2013_wan13. Accessed March 13, 2014.
[27] Alekh Agarwal, Olivier Chapelle, Miroslav Dudik, John Langford, A Reliable Effective Terascale Linear Learning System, 2011
[28] M. Hoffman, D. Blei, F. Bach, Online Learning for Latent Dirichlet Allocation, in Neural Information Processing Systems (NIPS) 2010.
[29] Alina Beygelzimer, Daniel Hsu, John Langford, and Tong Zhang Agnostic Active Learning Without Constraints NIPS 2010.
[30] John Duchi, Elad Hazan, and Yoram Singer, Adaptive Subgradient Methods for Online Learning and Stochastic Optimization, JMLR 2011 & COLT 2010.
[31] H. Brendan McMahan, Matthew Streeter, Adaptive Bound Optimization for Online Convex Optimization, COLT 2010.
[32] Nikos Karampatziakis and John Langford, Importance Weight Aware Gradient Updates UAI 2010.
[33] Kilian Weinberger, Anirban Dasgupta, John Langford, Alex Smola, Josh Attenberg, Feature Hashing for Large Scale Multitask Learning, ICML 2009.
[34] Qinfeng Shi, James Petterson, Gideon Dror, John Langford, Alex Smola, and SVN Vishwanathan, Hash Kernels for Structured Data, AISTAT 2009.
[35] John Langford, Lihong Li, and Tong Zhang, Sparse Online Learning via Truncated Gradient, NIPS 2008.
[36] Leon Bottou, Stochastic Gradient Descent, 2007.
[37] Avrim Blum, Adam Kalai, and John Langford Beating the Holdout: Bounds for KFold and Progressive Cross-Validation. COLT99 pages 203-208.
[38] Nocedal, J. (1980). "Updating Quasi-Newton Matrices with Limited Storage". Mathematics of Computation 35: 773–782.
[39] D. H. Ballard. Modular learning in neural networks. In AAAI, pages 279–284, 1987.
[40] S. Hochreiter. Untersuchungen zu dynamischen neuronalen Netzen. Diploma thesis, Institut f ̈ur In-
formatik, Lehrstuhl Prof. Brauer, Technische Universit ̈at M ̈unchen, 1991. Advisor: J. Schmidhuber.
from: http://www.erogol.com/brief-history-machine-learning/
机器学习简史brief history of machine learning的更多相关文章
- 斯坦福大学公开课机器学习:advice for applying machine learning | diagnosing bias vs. variance(机器学习:诊断偏差和方差问题)
当我们运行一个学习算法时,如果这个算法的表现不理想,那么有两种原因导致:要么偏差比较大.要么方差比较大.换句话说,要么是欠拟合.要么是过拟合.那么这两种情况,哪个和偏差有关.哪个和方差有关,或者是不是 ...
- Brief History of Machine Learning
Brief History of Machine Learning My subjective ML timeline Since the initial standpoint of science, ...
- Andrew Ng机器学习课程11之使用machine learning的建议
Andrew Ng机器学习课程11之使用machine learning的建议 声明:引用请注明出处http://blog.csdn.net/lg1259156776/ 2015-9-28 艺少
- 【原】Coursera—Andrew Ng机器学习—课程笔记 Lecture 11—Machine Learning System Design 机器学习系统设计
Lecture 11—Machine Learning System Design 11.1 垃圾邮件分类 本章中用一个实际例子: 垃圾邮件Spam的分类 来描述机器学习系统设计方法.首先来看两封邮件 ...
- 机器学习---朴素贝叶斯分类器(Machine Learning Naive Bayes Classifier)
朴素贝叶斯分类器是一组简单快速的分类算法.网上已经有很多文章介绍,比如这篇写得比较好:https://blog.csdn.net/sinat_36246371/article/details/6014 ...
- 斯坦福大学公开课机器学习:advice for applying machine learning | model selection and training/validation/test sets(模型选择以及训练集、交叉验证集和测试集的概念)
怎样选用正确的特征构造学习算法或者如何选择学习算法中的正则化参数lambda?这些问题我们称之为模型选择问题. 在对于这一问题的讨论中,我们不仅将数据分为:训练集和测试集,而是将数据分为三个数据组:也 ...
- 斯坦福大学公开课机器学习:advice for applying machine learning - deciding what to try next(设计机器学习系统时,怎样确定最适合、最正确的方法)
假如我们在开发一个机器学习系统,想试着改进一个机器学习系统的性能,我们应该如何决定接下来应该选择哪条道路? 为了解释这一问题,以预测房价的学习例子.假如我们已经得到学习参数以后,要将我们的假设函数放到 ...
- 轻松看懂机器学习十大常用算法 (Machine Learning Top 10 Commonly Used Algorithms)
原文出处: 不会停的蜗牛 通过本篇文章可以对ML的常用算法有个常识性的认识,没有代码,没有复杂的理论推导,就是图解一下,知道这些算法是什么,它们是怎么应用的,例子主要是分类问题. 每个算法都看了 ...
- 斯坦福大学公开课机器学习: advice for applying machine learning | deciding what to try next(revisited)(针对高偏差、高方差问题的解决方法以及隐藏层数的选择)
针对高偏差.高方差问题的解决方法: 1.解决高方差问题的方案:增大训练样本量.缩小特征量.增大lambda值 2.解决高偏差问题的方案:增大特征量.增加多项式特征(比如x1*x2,x1的平方等等).减 ...
随机推荐
- HTTP Status 500 - Request processing failed; nested exception is org.apache.ibatis.binding.BindingException
在使用Maven工程管理工具整合SSM框架时,Mybatis使用逆向工程生成的pojo,mapper接口及映射文件,把mapper接口和映射文件放在DAO工程的同一级src/main/java目录下. ...
- memory_get_usage()查看PHP脚本使用内存
memory_get_usage()可以查看当前php使用的内存大小.对于优化算法提高内存使用效率还是很实用的,尤其是对当下的移动端程序. <?php echo memory_get_usage ...
- JQuery实现最字体的放大缩小
网页常常有对字体放大缩小的需求,我们不妨来看一下下面这段JQuery代码的实现. 假如在html页面代码中我们有这么一段代码: <p>啦啦啦啦啦啦啦啦啦啦</p> 那么JQue ...
- ActiveMQ (二):JMS
1.前言 由于ActiveMQ是一种完全符合JMS规范的一种通信工具,所以在使用ActiveMQ前认识JMS规范就变的十分必要了. 认识JMS主要从以下方面: a. JMS 模型 b. JMS 对象模 ...
- 虚拟多Mac地址工具Multimac
虚拟多Mac地址工具Multimac Mac地址采用唯一标识标记网络的各种设备.在同一个时间内,Linux系统中的网卡只能使用一个Mac地址.在渗透测试中,为了隐藏自己的身份,往往需要以不同的Ma ...
- Django2.0中URL的路由机制
路由是关联url及其处理函数关系的过程.Django的url路由配置在settings.py文件中ROOT_URLCONF变量指定全局路由文件名称. Django的路由都写在urls.py文件中的ur ...
- JMS开发指南
1.JMS消息的异步与同步接收 消息的异步接收: 异步接收是指当消息到达时,主动通知客户端,即当消息到达时转发到客户端.JMS客户端可以通过注册一个实现MessageListener接口的对象到Mes ...
- BZOJ.2286.[SDOI2011]消耗战(虚树 树形DP)
题目链接 BZOJ 洛谷P2495 树形DP,对于每棵子树要么逐个删除其中要删除的边,要么直接断连向父节点的边. 如果当前点需要删除,那么直接断不需要再管子树. 复杂度O(m*n). 对于两个要删除的 ...
- 【洛谷】3469:[POI2008]BLO-Blockade【割点统计size】
P3469 [POI2008]BLO-Blockade 题意翻译 在Byteotia有n个城镇. 一些城镇之间由无向边连接. 在城镇外没有十字路口,尽管可能有桥,隧道或者高架公路(反正不考虑这些).每 ...
- Redis Cluster笔记
Redis Cluster .0搭建与使用 介绍: 特性:使用数据分片(sharding)而非一致性哈希(consistency hashing)来实现: 一个 Redis 集群包含 个哈希槽(has ...