【Hadoop】HBase组件配置
HBase实验步骤:
需要在Hadoop-全分布式配置的基础上进行配置
1、配置时间同步(所有节点)
[root@master ~]# yum -y install chrony
[root@master ~]# vi /etc/chrony.conf
server 0.time1.aliyun.com iburst
#保存
[root@master ~]# systemctl restart chronyd
[root@master ~]# systemctl enable chronyd
Created symlink from /etc/systemd/system/multi-user.target.wants/chronyd.service to /usr/lib/systemd/system/chronyd.service.
[root@master ~]# systemctl status chronyd
● chronyd.service - NTP client/server
Loaded: loaded (/usr/lib/systemd/system/chronyd.service; enabled; vendor preset: enabled)
Active: active (running) since Fri 2022-04-15 15:39:55 CST; 23s ago
Main PID: 1900 (chronyd)
CGroup: /system.slice/chronyd.service
└─1900 /usr/sbin/chronyd
#看到running则表示成功
2、部署HBase(master节点)
先使用xftp上传hbase软件包至/opt/software
# 解压
[root@master ~]# tar xf /opt/software/hbase-1.2.1-bin.tar.gz -C /usr/local/src/
[root@master ~]# cd /usr/local/src/
[root@master src]# mv hbase-1.2.1 hbase
[root@master src]# ls
hadoop hbase hive jdk
# 配置hbase环境变量
[root@master src]# vi /etc/profile.d/hbase.sh
export HBASE_HOME=/usr/local/src/hbase
export PATH=${HBASE_HOME}/bin:$PATH
#保存
[root@master src]# source /etc/profile.d/hbase.sh
[root@master src]# echo $PATH
/usr/local/src/hbase/bin:/usr/local/src/jdk/bin:/usr/local/src/hadoop/bin:/usr/local/src/hadoop/sbin:/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/usr/local/src/hive/bin:/root/bin
#看到环境变量中有hbase的路径则表示成功
3、配置HBase(master节点)
# 配置HBase
[root@master src]# cd /usr/local/src/hbase/conf/
[root@master conf]# vi hbase-env.sh
export JAVA_HOME=/usr/local/src/jdk
export HBASE_MANAGES_ZK=true
export HBASE_CLASSPATH=/usr/local/src/hadoop/etc/hadoop/
#保存
[root@master conf]# vi hbase-site.xml
<configuration>
<property>
<name>hbase.rootdir</name>
<value>hdfs://master:9000/hbase</value>
</property>
<property>
<name>hbase.master.info.port</name>
<value>60010</value>
</property>
<property>
<name>hbase.zookeeper.property.clientPort</name>
<value>2181</value>
</property>
<property>
<name>zookeeper.session.timeout</name>
<value>10000</value>
</property>
<property>
<name>hbase.zookeeper.quorum</name>
<value>master,slave1,slave2</value>
</property>
<property>
<name>hbase.tmp.dir</name>
<value>/usr/local/src/hbase/tmp</value>
</property>
<property>
<name>hbase.cluster.distributed</name>
<value>true</value>
</property>
</configuration>
#保存
[root@master conf]# vi regionservers
192.168.100.20
192.168.100.30
#保存
[root@master conf]# mkdir -p /usr/local/src/hbase/tmp
4、拷贝文件到slave节点
# master节点
[root@master conf]# scp -r /usr/local/src/hbase slave1:/usr/local/src/
[root@master conf]# scp -r /usr/local/src/hbase slave2:/usr/local/src/
[root@master conf]# scp /etc/profile.d/hbase.sh slave1:/etc/profile.d/
[root@master conf]# scp /etc/profile.d/hbase.sh slave2:/etc/profile.d/
5、修改权限,切换用户(所有节点)
# master节点
[root@master conf]# chown -R hadoop.hadoop /usr/local/src
[root@master conf]# ll /usr/local/src/
total 0
drwxr-xr-x. 12 hadoop hadoop 183 Apr 9 09:57 hadoop
drwxr-xr-x 8 hadoop hadoop 171 Apr 15 15:59 hbase
drwxr-xr-x. 11 hadoop hadoop 215 Apr 9 10:40 hive
drwxr-xr-x. 8 hadoop hadoop 255 Sep 14 2017 jdk
[root@master conf]# su - hadoop
# slave1节点
[root@slave1 ~]# chown -R hadoop.hadoop /usr/local/src
[root@slave1 ~]# ll /usr/local/src/
total 0
drwxr-xr-x. 12 hadoop hadoop 183 Apr 9 09:59 hadoop
drwxr-xr-x 8 hadoop hadoop 171 Apr 15 16:19 hbase
drwxr-xr-x. 8 hadoop hadoop 255 Apr 8 17:24 jdk
[root@slave1 ~]# su - hadoop
# slave2节点
[root@slave2 ~]# ll /usr/local/src/
总用量 0
drwxr-xr-x. 12 hadoop hadoop 183 4月 9 09:59 hadoop
drwxr-xr-x 8 hadoop hadoop 171 4月 15 16:19 hbase
drwxr-xr-x. 8 hadoop hadoop 255 4月 8 17:24 jdk
[root@slave2 ~]# su - hadoop
6、启动hadoop(master节点)
#在master上启动分布式hadoop集群
[hadoop@master ~]$ start-all.sh
[hadoop@master ~]$ jps
3210 Jps
2571 NameNode
2780 SecondaryNameNode
2943 ResourceManager
# 查看slave1节点
[hadoop@slave1 ~]$ jps
2512 DataNode
2756 Jps
2623 NodeManager
# 查看slave2节点
[hadoop@slave2 ~]$ jps
3379 Jps
3239 NodeManager
3135 DataNode
#确保master上有NameNode、SecondaryNameNode、 ResourceManager进程, slave节点上要有DataNode、NodeManager进程
7、启动hbase(master节点)
[hadoop@master ~]$ start-hbase.sh
[hadoop@master ~]$ jps
3569 HMaster
2571 NameNode
2780 SecondaryNameNode
3692 Jps
2943 ResourceManager
3471 HQuorumPeer
# 查看slave1节点
[hadoop@slave1 ~]$ jps
2512 DataNode
2818 HQuorumPeer
2933 HRegionServer
3094 Jps
2623 NodeManager
# 查看slave2节点
[hadoop@slave2 ~]$ jps
3239 NodeManager
3705 Jps
3546 HRegionServer
3437 HQuorumPeer
3135 DataNode
#确保master上有HQuorumPeer、HMaster进程,slave节点上要有HQuorumPeer、HRegionServer进程
8、查看浏览器页面
在windows主机上执行:
在C:\windows\system32\drivers\etc\下面把hosts文件拖到桌面上,然后编辑它加入master的主机名与IP地址的映射关系,在浏览器上输入http://master:60010访问hbase的web界面
192.168.100.10 master master.example.com
192.168.100.20 slave1 slave1.example.com
192.168.100.30 slave2 slave2.example.com
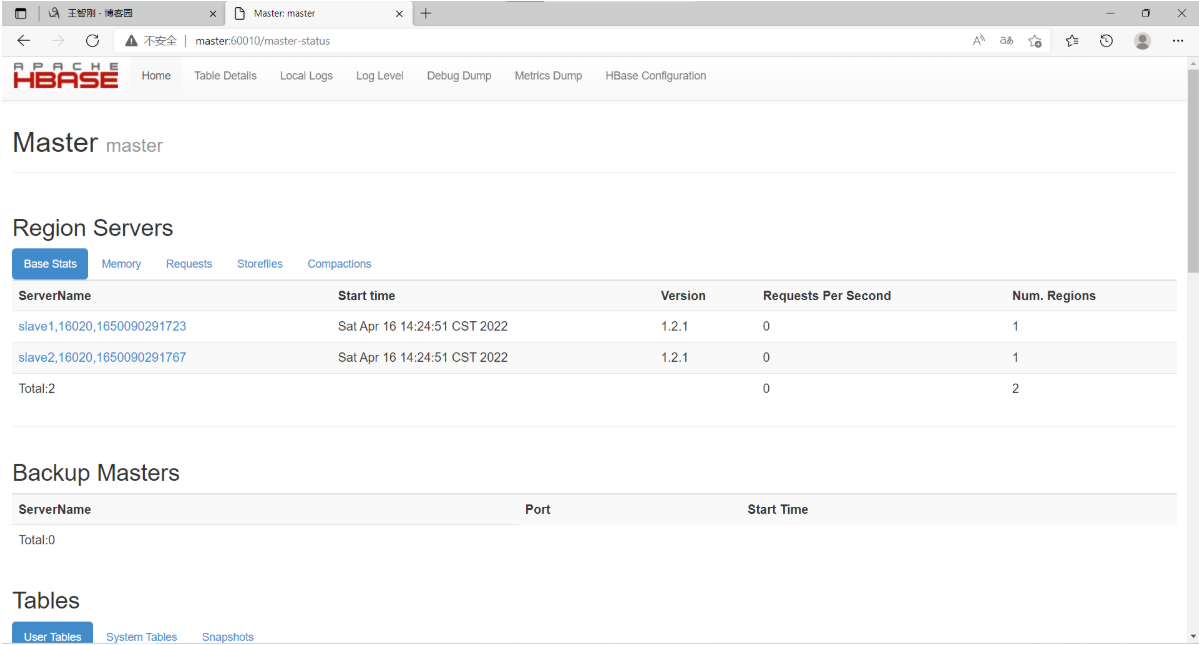
9、hbase语法应用(master节点)
[hadoop@master ~]$ hbase shell
SLF4J: Class path contains multiple SLF4J bindings.
SLF4J: Found binding in [jar:file:/usr/local/src/hbase/lib/slf4j-log4j12-1.7.5.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: Found binding in [jar:file:/usr/local/src/hadoop/share/hadoop/common/lib/slf4j-log4j12-1.7.10.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: See http://www.slf4j.org/codes.html#multiple_bindings for an explanation.
SLF4J: Actual binding is of type [org.slf4j.impl.Log4jLoggerFactory]
HBase Shell; enter 'help<RETURN>' for list of supported commands.
Type "exit<RETURN>" to leave the HBase Shell
Version 1.2.1, r8d8a7107dc4ccbf36a92f64675dc60392f85c015, Wed Mar 30 11:19:21 CDT 2016
# 创建一张名为scores的表,表内有两个列簇
hbase(main):001:0> create 'scores','grade','course'
0 row(s) in 1.3950 seconds
=> Hbase::Table - scores
# 查看hbase状态
hbase(main):002:0> status
1 active master, 0 backup masters, 2 servers, 0 dead, 1.5000 average load
# 查看数据库版本
hbase(main):003:0> version
1.2.1, r8d8a7107dc4ccbf36a92f64675dc60392f85c015, Wed Mar 30 11:19:21 CDT 2016
# 查看表
hbase(main):004:0> list
TABLE
scores
1 row(s) in 0.0150 seconds
=> ["scores"]
# 插入记录
hbase(main):005:0> put 'scores','jie','grade:','146cloud'
0 row(s) in 0.1000 seconds
hbase(main):006:0> put 'scores','jie','course:math','86'
0 row(s) in 0.0160 seconds
hbase(main):007:0> put 'scores','jie','course:cloud','92'
0 row(s) in 0.0120 seconds
hbase(main):008:0> put 'scores','shi','grade:','133soft'
0 row(s) in 0.0120 seconds
hbase(main):009:0> put 'scores','shi','course:math','87'
0 row(s) in 0.0080 seconds
hbase(main):010:0> put 'scores','shi','course:cloud','96'
0 row(s) in 0.0080 seconds
# 读取的记录
hbase(main):011:0> get 'scores','jie'
COLUMN CELL
course:cloud timestamp=1650090459825, value=92
course:math timestamp=1650090453152, value=86
grade: timestamp=1650090446128, value=146cloud
3 row(s) in 0.0190 seconds
hbase(main):012:0> get 'scores','jie','grade'
COLUMN CELL
grade: timestamp=1650090446128, value=146cloud
1 row(s) in 0.0080 seconds
# 查看整个表记录
hbase(main):013:0> scan 'scores'
ROW COLUMN+CELL
jie column=course:cloud, timestamp=1650090459825, value=92
jie column=course:math, timestamp=1650090453152, value=86
jie column=grade:, timestamp=1650090446128, value=146cloud
shi column=course:cloud, timestamp=1650090479946, value=96
shi column=course:math, timestamp=1650090475684, value=87
shi column=grade:, timestamp=1650090464698, value=133soft
2 row(s) in 0.0200 seconds
# 按例查看表记录
hbase(main):014:0> scan 'scores',{COLUMNS=>'course'}
ROW COLUMN+CELL
jie column=course:cloud, timestamp=1650090459825, value=92
jie column=course:math, timestamp=1650090453152, value=86
shi column=course:cloud, timestamp=1650090479946, value=96
shi column=course:math, timestamp=1650090475684, value=87
2 row(s) in 0.0140 seconds
# 删除指定记录
hbase(main):015:0> delete 'scores','shi','grade'
0 row(s) in 0.0190 seconds
# 增加新的名为age的列簇
hbase(main):016:0> alter 'scores',NAME=>'age'
Updating all regions with the new schema...
1/1 regions updated.
Done.
0 row(s) in 1.9080 seconds
# 查看表结构
hbase(main):017:0> describe 'scores'
Table scores is ENABLED
scores
COLUMN FAMILIES DESCRIPTION
{NAME => 'age', BLOOMFILTER => 'ROW', VERSIONS => '1', IN_MEMORY => 'false', KEEP_DELETED_CELLS =
> 'FALSE', DATA_BLOCK_ENCODING => 'NONE', TTL => 'FOREVER', COMPRESSION => 'NONE', MIN_VERSIONS =
> '0', BLOCKCACHE => 'true', BLOCKSIZE => '65536', REPLICATION_SCOPE => '0'}
{NAME => 'course', BLOOMFILTER => 'ROW', VERSIONS => '1', IN_MEMORY => 'false', KEEP_DELETED_CELL
S => 'FALSE', DATA_BLOCK_ENCODING => 'NONE', TTL => 'FOREVER', COMPRESSION => 'NONE', MIN_VERSION
S => '0', BLOCKCACHE => 'true', BLOCKSIZE => '65536', REPLICATION_SCOPE => '0'}
{NAME => 'grade', BLOOMFILTER => 'ROW', VERSIONS => '1', IN_MEMORY => 'false', KEEP_DELETED_CELLS
=> 'FALSE', DATA_BLOCK_ENCODING => 'NONE', TTL => 'FOREVER', COMPRESSION => 'NONE', MIN_VERSIONS
=> '0', BLOCKCACHE => 'true', BLOCKSIZE => '65536', REPLICATION_SCOPE => '0'}
3 row(s) in 0.0230 seconds
# 删除名为age的列簇
hbase(main):018:0> alter 'scores',NAME=>'age',METHOD=>'delete'
Updating all regions with the new schema...
1/1 regions updated.
Done.
0 row(s) in 1.8940 seconds
# 删除表
hbase(main):019:0> disable 'scores'
0 row(s) in 2.2400 seconds
# 退出hbase
hbase(main):020:0> drop 'scores'
0 row(s) in 1.2450 seconds
hbase(main):021:0> list
TABLE
0 row(s) in 0.0040 seconds
=> []
# 退出hbase
hbase(main):022:0> quit
10、关闭hbase(master节点)
# 关闭hbase
[hadoop@master ~]$ stop-hbase.sh
stopping hbase...............
[hadoop@master ~]$ jps
44952 NameNode
45306 ResourceManager
46988 Jps
45150 SecondaryNameNode
# 关闭hadoop
[hadoop@master ~]$ stop-all.sh
This script is Deprecated. Instead use stop-dfs.sh and stop-yarn.sh
Stopping namenodes on [master]
…………
[hadoop@master ~]$ jps
47438 Jps
声明:未经许可,不得转载
原文地址:https://www.cnblogs.com/wzgwzg/p/16152890.html
【Hadoop】HBase组件配置的更多相关文章
- hadoop 各种组件配置参数
********************************************hive*********************************************** hive ...
- cdh版本的hue安装配置部署以及集成hadoop hbase hive mysql等权威指南
hue下载地址:https://github.com/cloudera/hue hue学习文档地址:http://archive.cloudera.com/cdh5/cdh/5/hue-3.7.0-c ...
- [推荐]Hadoop+HBase+Zookeeper集群的配置
[推荐]Hadoop+HBase+Zookeeper集群的配置 Hadoop+HBase+Zookeeper集群的配置 http://wenku.baidu.com/view/991258e881c ...
- hbase安装配置(整合到hadoop)
hbase安装配置(整合到hadoop) 如果想详细了解hbase的安装:http://abloz.com/hbase/book.html 和官网http://hbase.apache.org/ 1. ...
- 远程调试hadoop各组件
远程调试对应用程序开发十分有用.例如,为不能托管开发平台的低端机器开发程序,或在专用的机器上(比如服务不能中断的 Web 服务器)调试程序.其他情况包括:运行在内存小或 CUP 性能低的设备上的 Ja ...
- hadoop端口使用配置总结(非常好的总结)
转自http://www.aboutyun.com/thread-7513-1-1.html Hadoop集群的各部分一般都会使用到多个端口,有些是daemon之间进行交互之用,有些是用于RPC访问以 ...
- Hadoop Hbase理论及实操
Hbase特点 HBase是一个构建在HDFS上的分布式列存储系统:HBase是基于Google BigTable模型开发的,典型的key/value系统:HBase是Apache Hadoop生态系 ...
- 五十九.大数据、Hadoop 、 Hadoop安装与配置 、 HDFS
1.安装Hadoop 单机模式安装Hadoop 安装JAVA环境 设置环境变量,启动运行 1.1 环境准备 1)配置主机名为nn01,ip为192.168.1.21,配置yum源(系统源) 备 ...
- Hadoop(一)阿里云hadoop集群配置
集群配置 三台ECS云服务器 配置步骤 1.准备工作 1.1 创建/bigdata目录 mkdir /bigdatacd /bigdatamkdir /app 1.2修改主机名为node01.node ...
随机推荐
- 西门子STEP7安装过程不断提示电脑重启的解决方法
win+R打开注册表 进入 计算机\HKEY_LOCAL_MACHINE\SYSTEM\CurrentControlSet\Control\Session Manager 删除PendingFileR ...
- 【ASP.NET Core】MVC模型绑定:非规范正文内容的处理
本篇老周就和老伙伴们分享一下,对于客户端提交的不规范 Body 如何做模型绑定.不必多说,这种情况下,只能自定义 ModelBinder 了.而且最佳方案是不要注册为全局 Binder--毕竟这种特殊 ...
- pytest配置文件pytest.ini
说明: pytest.ini是pytest的全局配置文件,一般放在项目的根目录下 是一个固定的文件-pytest.ini 可以改变pytest的运行方式,设置配置信息,读取后按照配置的内容去运行 py ...
- Java基础 - 泛型详解
2022-03-24 09:55:06 @GhostFace 泛型 什么是泛型? 来自博客 Java泛型这个特性是从JDK 1.5才开始加入的,因此为了兼容之前的版本,Java泛型的实现采取了&quo ...
- 不会真有人还不会调用Excel吧?
哈喽,大家好!我是指北君. 大家有没有过这样的经历:开发某个项目,需要调用Excel控件去生成Excel文件.填充数据.改变格式等等,常常在测试环境中一切正常,但在生产环境却无法正常调用Excel,不 ...
- docker知识点扫盲
最近给部门同事培训docker相关的东西,把我的培训内容总结下,发到博客园上,和大家一起分享.我的培训思路是这样的 首先讲解docker的安装.然后讲下docker的基本的原理,最后讲下docker的 ...
- 27.Java 飞机游戏小项目
开篇 游戏项目基本功能开发 飞机类设计 炮弹类设计 碰撞检测设计 爆炸效果的实现 其他功能 计时功能 游戏项目基本功能开发 这里将会一步步实现游戏项目的基本功能. 使用 AWT 技术画出游戏主窗口 A ...
- Dubbo 必须依赖的包有哪些?
Dubbo 必须依赖 JDK,其他为可选.
- spring aware 的个人理解
今天学习到了spring aware ,特地百度了下这方面的知识,现在谈下我的理解. Spring的依赖注入的最大亮点就是你所有的Bean对Spring容器的存在是没有意识的.即你可以将你的容器替换成 ...
- 学习Cobbler(一)
一. http://cobbler.github.io/ Cobbler is a Linux installation server that allows for rapid setup of n ...