NLP论文解读:无需模板且高效的语言微调模型(下)
原创作者 | 苏菲
论文题目:
Prompt-free and Efficient Language Model Fine-Tuning
论文作者:
Rabeeh Karimi Mahabadi
论文地址:
https://openreview.net/pdf?id=6o5ZEtqP2g
02 PERFECT:无需Patterns和Verbalizer的微调模型
这个模型主要包含三个部分:
1)无需pattern的任务描述,使用了一个任务相关的适配器来有效告知模型相关的任务,取代了手工制作的patterns;
2)使用多token的标签向量来有效学习标签的表示,去掉了原来手工设计的verbalizers;
3)基于原型网络思想的有效预测策略,取代了原来的逐个自回归解码方法。如图3所示,该模型固定了预训练语言模型的底层,而仅仅优化新加入模块(图中绿色模块)的参数。这些新加入的模块包括可以适应给定任务的表示的适配器和多token标签表示等等。
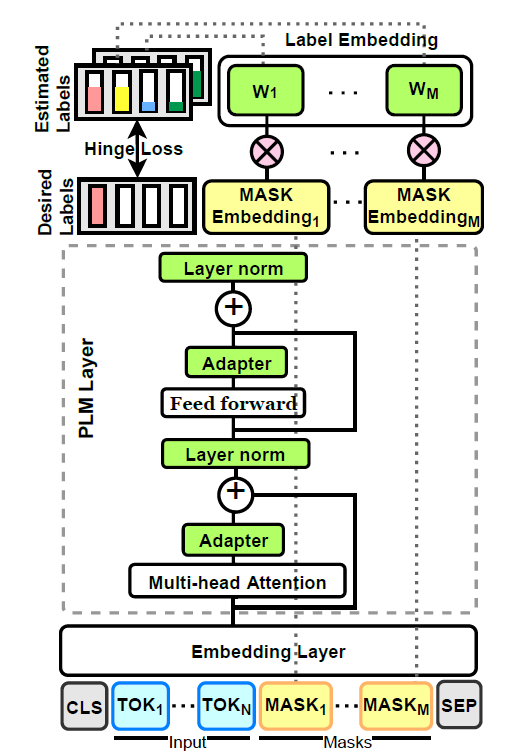
图3
2.1 无需模板的任务描述
该模型使用了面向具体任务的适配层(Adapter Layers),为模型提供学习到的隐式的任务描述。
适配层的加入还额外带来了其它好处:
a)微调预训练语言模型的上百万或几十亿的所有权重参数是样本低效的,在低资源环境下是不稳定的,而适配层的引入可以通过保持预训练语言模型底层参数不变,使得微调是样本高效的;
b)适配层减少了存储和内存的占用空间;
c)增加了模型的稳定性和性能,使得这种方法成为少样本微调的一种好方案。
2.2 多标记标签向量

使用固定的token数M来表示每一个标签,而不是经典模型中可变token长度的verbalizers,可以大大简化模型的实现并提升训练的速度。
2.3 PERFECT的训练
如图3所示,模型通过标签向量的最优化,使得预训练语言模型可以预测得到正确的标签;通过适配器的最优化使得预训练语言模型可以适应给定的任务。
对于标签向量来说,PERFECT模型为每一个token都训练了一个分类器,并使得所有掩码位置的多类别铰链损失平均值最小。

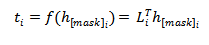

2.4 PERFECT的预测
在预测过程中,PERFECT模型没有使用之前的递归自回归解码方案,而是通过寻找最近的掩码token向量的类别原型来区分一个查询点,如公式(6)所示。
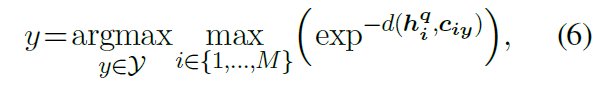

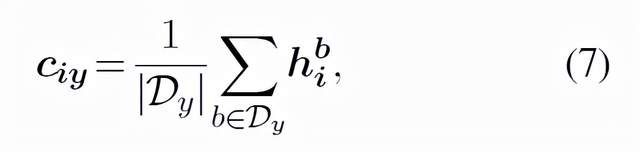

03 实验
数据集:论文作者选择了7个任务(共12个数据集):

对于其它数据集,由于测试集数据无法公开获取,论文作者只是在原始验证集数据上进行了测试,即从训练集中按每个类别分别取16个样本例子,得到16个训练样本和16个验证样本。
3.1 基线模型:

是目前最好的少样本学习系统,采用了手工精心设计的verbalizers和pattern;论文作者给出了使用所有patterns和verbalizers后PET系统的最好结果和平均结果。
微调:采用标准的微调,基于[CLS]加了一个分类器并微调所有参数。
3.2 本文模型:
PERFECT-rand:从标准正态分布随机初始化标签向量L,其中(基于验证集表现),并没有依赖于任何手工制作的模板(patterns)和语言生成器(verbalizers)。
PERFECT-init:作为消融实验之一,论文作者使用预训练语言模型词汇表手工设计了verbalizers,并利用其中的token向量去初始化标签(label)向量,以便研究verbalizers对模型的影响。
PERFECT-prompt:作为消融实验之二,论文作者比较了使用适配层与使用软提示微调的结果,软提示微调是去除适配层并在输入增加可训练的连续提示向量。微调时论文作者仅仅微调了软提示以及标签向量。
3.3 实验细节
论文作者使用了含355M个参数的RoBERTa大模型作为所有方法的基础预训练语言模型(PLM),使用了HuggingFace的PyTorch实现。对基线模型,使用了手工精心设计的patterns和verbalizers。
对于所有的模型方法,评估时使用了5种不同的随机采样去获得训练集或者验证集,并且训练时用了4个不同的随机种子数。
因此,对于PET系统的平均结果,是基于20*5(模板数*语言生成器词汇标签转换数)共100次运行的结果;而PET的最好结果以及论文作者模型的各种结果,都是基于20次运行的结果。
在少样本学习方法中方差通常是很高的,因此论文作者报告了所有运行结果中方差的平均值、最坏情况表现,以及标准差,其中后两个的值对于风险敏感的应用是十分重要的。
3.4 实验结果
表1给出了所有模型及方法的实验结果。其中,论文提出的PERFECT模型得到了最先进的结果,在单句测试中比PET系统的平均得分提高了1.1个百分点,在句子对数据集测试中提高了4.6个百分点。
PERFECT模型的表现甚至超过了PET系统的最好结果(PET-best),这个最好结果是多个手工编制patterns和verbalizers的结果。而且,PERFECT还改善了最低表现,并大幅降低了标准差。
最后,PERFECT也是显著高效率的,它减少了训练时间和预测时间,降低了内存成本和存储成本(见表2)。
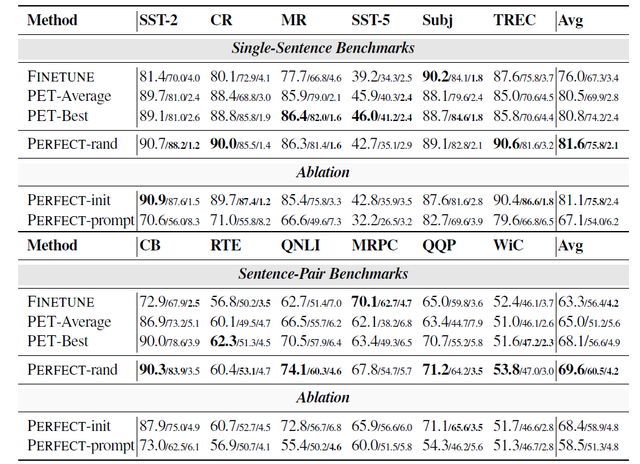
表1
表2给出了PET模型和PERFECT模型的训练参数、内存使用、训练时间和预测时间的对比。可以看到,PERFECT的参数数量下降了99.08%,因此在存储的需求上几乎缩小了100倍。
在内存使用峰值上,PERFECT下降了21.93%,对内存的需求与PET相比也减少了。在训练时间上,PEFECT比原始的PET系统减少了97.22%,比论文作者实现的PET系统则减少了30.85%。
而在预测时间上,PERFECT与PET相比也显著减少了96.76%。
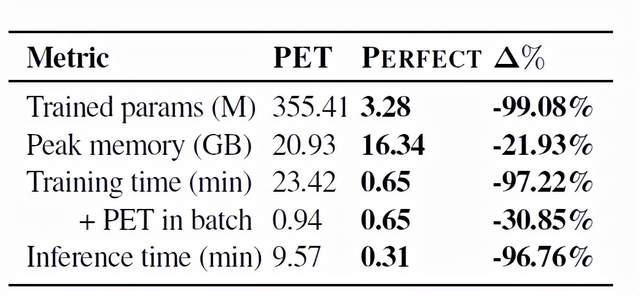
表2
04 结论
这篇论文提出的PERFECT模型及方法,对于预训练语言模型的小样本学习是简单且高效的,该方法并不需要手工的模板和词汇标签映射。
PERFECT使用了面向具体任务的适配层来隐式地学习具体任务的描述,取代了以前的手工的模板;并使用一个连续的多标记标签向量来表示输出的类别。
通过多达12个NLP数据集的实验,论文作者证明了PERFECT模型尽管更加简单,但却更加高效。与当前先进的预训练语言模型小样本学习方法相比,得到了SOTA的结果。
总之,PERFECT的简单性和有效性使其在预训练语言模型的少样本学习方法中前景广阔。
参考文献
[1] Jake Snell, Kevin Swersky, and Richard Zemel. 2017. Prototypical networks for few-shot learning. In NeurIPS.
[2] Richard Socher, Alex Perelygin, Jean Wu, Jason Chuang, Christopher D Manning, Andrew Y Ng, and Christopher Potts. 2013. Recursive deep models for semantic compositionality over a sentiment treebank. In EMNLP.
[3] Bo Pang and Lillian Lee. 2005. Seeing stars: Exploiting class relationships for sentiment categorization with respect to rating scales. In ACL.
[4] Minqing Hu and Bing Liu. 2004. Mining and summarizing customer reviews. In SIGKDD.
[5] Bo Pang and Lillian Lee. 2004. A sentimental education: sentiment analysis using subjectivity summarization based on minimum cuts. In ACL.
[6] Ellen M Voorhees and Dawn M Tice. 2000. Building a question answering test collection. In SIGIR.
[7] Marie-Catherine De Marneffe, Mandy Simons, and Judith Tonhauser. 2019. The commitmentbank: Investigating projection in naturally occurring discourse. In proceedings of Sinn und Bedeutung.
[8] Alex Wang, Yada Pruksachatkun, Nikita Nangia, Amanpreet Singh, Julian Michael, Felix Hill, Omer Levy, and Samuel R Bowman. 2019a. Superglue: a stickier benchmark for general-purpose language understanding systems. In NeurIPS.
[9] Pranav Rajpurkar, Jian Zhang, Konstantin Lopyrev, and Percy Liang. 2016. Squad: 100,000+ questions for machine comprehension of text. In EMNLP.
[10] Mohammad Taher Pilehvar and Jose Camacho-Collados. 2019. Wic: the word-in-context dataset for evaluating context-sensitive meaning representations. In NAACL.
[11] William B Dolan and Chris Brockett. 2005. Automatically constructing a corpus of sentential paraphrases. In IWP.
[12] Timo Schick and Hinrich Schütze. 2021a. Exploiting cloze-questions for few-shot text classification and natural language inference. In EACL.
[13] Timo Schick and Hinrich Schütze. 2021b. It’s not just size that matters: Small language models are also few-shot learners. In NAACL.
NLP论文解读:无需模板且高效的语言微调模型(下)的更多相关文章
- NLP论文解读:无需模板且高效的语言微调模型(上)
原创作者 | 苏菲 论文题目: Prompt-free and Efficient Language Model Fine-Tuning 论文作者: Rabeeh Karimi Mahabadi 论文 ...
- 人工智能论文解读精选 | PRGC:一种新的联合关系抽取模型
NLP论文解读 原创•作者 | 小欣 论文标题:PRGC: Potential Relation and Global Correspondence Based Joint Relational ...
- 从单一图像中提取文档图像:ICCV2019论文解读
从单一图像中提取文档图像:ICCV2019论文解读 DewarpNet: Single-Image Document Unwarping With Stacked 3D and 2D Regressi ...
- itemKNN发展史----推荐系统的三篇重要的论文解读
itemKNN发展史----推荐系统的三篇重要的论文解读 本文用到的符号标识 1.Item-based CF 基本过程: 计算相似度矩阵 Cosine相似度 皮尔逊相似系数 参数聚合进行推荐 根据用户 ...
- AAAI2019 | 基于区域分解集成的目标检测 论文解读
Object Detection based on Region Decomposition and Assembly AAAI2019 | 基于区域分解集成的目标检测 论文解读 作者 | 文永亮 学 ...
- zz扔掉anchor!真正的CenterNet——Objects as Points论文解读
首发于深度学习那些事 已关注写文章 扔掉anchor!真正的CenterNet——Objects as Points论文解读 OLDPAN 不明觉厉的人工智障程序员 关注他 JustDoIT 等 ...
- 注意力论文解读(1) | Non-local Neural Network | CVPR2018 | 已复现
文章转自微信公众号:[机器学习炼丹术] 参考目录: 目录 0 概述 1 主要内容 1.1 Non local的优势 1.2 pytorch复现 1.3 代码解读 1.4 论文解读 2 总结 论文名称: ...
- 论文解读丨基于局部特征保留的图卷积神经网络架构(LPD-GCN)
摘要:本文提出一种基于局部特征保留的图卷积网络架构,与最新的对比算法相比,该方法在多个数据集上的图分类性能得到大幅度提升,泛化性能也得到了改善. 本文分享自华为云社区<论文解读:基于局部特征保留 ...
- CVPR2020论文解读:3D Object Detection三维目标检测
CVPR2020论文解读:3D Object Detection三维目标检测 PV-RCNN:Point-Voxel Feature Se tAbstraction for 3D Object Det ...
随机推荐
- ApacheCN C/C++ 译文集(二) 20211204 更新
编写高效程序的艺术 零.序言 第一部分:性能基础 一.性能和并发性介绍 二.性能测量 三.CPU 架构.资源和性能 四.内存架构和性能 五.线程.内存和并发 第二部分:高级并发 六.并发和性能 七.并 ...
- Tomcat下 session 持久化问题(重启服务器session 仍然存在)
感谢大佬:https://www.iteye.com/blog/xiaolongfeixiang-560800 关于在线人数统计,大都使用SessionListener监听器实现. SessionLi ...
- kebernet--新手填坑
1.安装好kubernet之后,新建rc后,里面的容器一直ImagePullBackOff ,镜像无法拉取: ----需要配置docker镜像为国内镜像,记得在各个Node上都要配置!!! vim / ...
- NSDate分类,把系统返回的时间与现在进行比较---秀清
// // NSDate+Joe.h // WeiBo // // Created by 张秀清 on 15/9/17. // Copyright (c) 2015年 张秀清. All rights ...
- 深入Java微服务之网关系列1:什么是网关
前言 近来,在想着重构一个新的产品.准备采用微服务的技术解决方案,来搭建基础设施框架.网关,是一个必不可少的组件.那么,网关到底是什么? 其又有什么特点或者特性,成为微服务必不可少的组件呢?今天, ...
- 什么是rest?restful?
百度百科解释: rest:REST即表述性状态传递(英文:Representational State Transfer,简称REST)是Roy Fielding博士在2000年他的博士论文中提出来的 ...
- Sublime Python3编译环境修改
http://blog.csdn.net/qq_33304418/article/details/63337602 添加编译环境python3.6 Tools -> Build Syst ...
- 教你用Elastic Search:运行第一条Hello World搜索命令
摘要:Elastic Search可实时对数据库进行全文检索.处理同义词.从同样的数据中生成分析和聚合数据. 本文分享自华为云社区<Elastic Search入门(一): 简介,安装,运行第一 ...
- Note - Powerful Number
Powerful Number 对于 \(n\in\mathbb N_+\),若不存在素数 \(p\) 使得 \(p\mid n~\land~p^2\not\mid n\),则称 \(n\) 为 ...
- 对象到底是怎么new出来的
前言:要想理解本文,必须先了解JVM的内存结构 一.创建对象的方式 new:最常见 反射:Class.newInstance() 使用clone() 反序列化 二.创建对象的步骤(对象在JVM中怎么存 ...