一个 MySQL 隐式转换的坑,差点把服务器整崩溃了
我是风筝,公众号「古时的风筝」,专注于 Java技术 及周边生态。
文章会收录在 JavaNewBee 中,更有 Java 后端知识图谱,从小白到大牛要走的路都在里面。
本来是一个平静而美好的下午,其他部门的同事要一份数据报表临时汇报使用,因为系统目前没有这个维度的功能,所以需要写个SQL马上出一下,一个同事接到这个任务,于是开始在测试环境拼装这条 SQL,刚过了几分钟,同事已经自信的写好了这条SQL,于是拿给DBA,到线上跑一下,用客户端工具导出Excel 就好了,毕竟是临时方案嘛。
就在SQL执行了之后,意外发生了,先是等了一下,发现还没执行成功,猜测可能是数据量大的原因,但是随着时间滴滴答答流逝,逐渐意识到情况不对了,一看监控,CPU已经上去了,但是线上数据量虽然不小,也不至于跑成这样吧,眼看着要跑死了,赶紧把这个事务结束掉了。
什么原因呢?查询的条件和 join 连接的字段基本都有索引,按道理不应该这样啊,于是赶紧把SQL拿下来,也没看出什么问题,于是限制查询条数再跑了一次,很快出结果了,但是结果却大跌眼镜,出来的查询结果并不是预期的。

经过一番检查之后,最终发现了问题所在,是 join 连接中有一个字段写错了,因为这两个字段有一部分名称是相同的,于是智能的 SQL 客户端给出了提示,顺手就给敲上去了。但是接下来,更让人迷惑了,因为要连接的字段是 int 类型,而写错的这个字段是 varchar 类型,难道不应该报错吗?怎么还能正常执行,并且还有预期外的查询结果?
难道是 MySQL 有 bug 了,必须要研究一下了。
复现当时的情景
假设有两张表,这两张表的结构和数据是下面这样的。
第一张 user表。
CREATE TABLE `user` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`name` varchar(50) COLLATE utf8_bin DEFAULT NULL,
`age` int(3) DEFAULT NULL,
`create_time` datetime DEFAULT NULL,
`update_time` datetime DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=2 DEFAULT CHARSET=utf8 COLLATE=utf8_bin;
INSERT INTO `user` VALUES (1, '张三', 28, '2022-09-06 07:40:56', '2022-09-06 07:40:59');
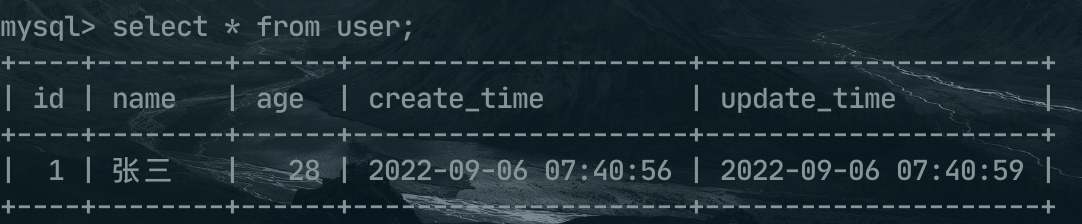
第二张 order表
CREATE TABLE `order` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`user_id` int(11) DEFAULT NULL,
`order_code` varchar(64) COLLATE utf8_bin DEFAULT NULL,
`money` decimal(20,0) DEFAULT NULL,
`title` varchar(255) COLLATE utf8_bin DEFAULT NULL,
`create_time` datetime DEFAULT NULL,
`update_time` datetime DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=2 DEFAULT CHARSET=utf8 COLLATE=utf8_bin;
INSERT INTO `order` VALUES (1, 2, '1d90530e-6ada-47c1-b2fa-adba4545aabd', 100, 'xxx购买两件商品', '2022-09-06 07:42:25', '2022-09-06 07:42:27');

目的是查看所有用户的 order 记录,假设数据量比较少,可以直接查,不考虑性能问题。
本来的 SQL 语句应该是这样子的,查询 order表中用户iduser_id在user表的记录。
select o.* from `user` u
left JOIN `order` o on u.id = o.user_id;
但是呢,因为手抖,将 on 后面的条件写成了 u.id = o.order_code,完全关联错误,这两个字段完全没有联系,而且u.id是 int 类型,o.order_code是varchar类型。
select o.* from `user` u
left JOIN `order` o on u.id = o.order_code;
这样的话, 当我们执行这条语句的时候,会不会查出数据来呢?
我的第一感觉是,不仅不会查出数据,而且还会报错,因为连接的这两个字段类型都不一样,值更不一样。
结果却被啪啪打脸,不仅没有报错,而且还查出了数据。

可以把这个问题简化一下,简化成下面这条语句,同样也会出现问题。
select * from `order` where order_code = 1;

明明这条记录的 order_code 字段的值是 1d90530e-6ada-47c1-b2fa-adba4545aabd,怎么用 order_code=1的条件就把它给查出来了。
根源所在
相信有的同学已经猜出来了,这里是 MySQL 进行了隐式转换,由于查询条件后面跟的查询值是整型的,所以 MySQL 将 order_code字段进行了字符串到整数类型的转换,而转换后的结果正好是 1。
通过 cast函数转换验证一下结果。
select cast('1d90530e-6ada-47c1-b2fa-adba4545aabd' as unsigned);

再用两条 SQL 看一下字符串到整数类型转换的规则。
select cast('223kkk' as unsigned);
select cast('k223kkk' as unsigned);
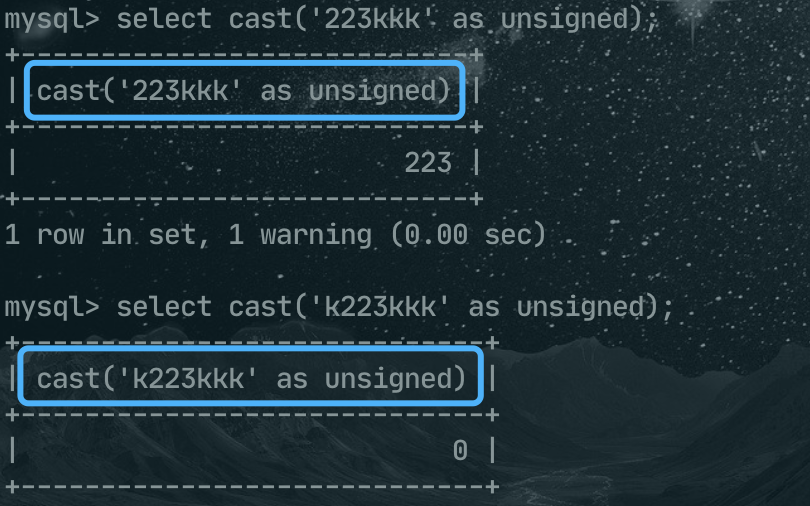
223kkk转换后的结果是 223,而k223kkk转换后的结果是0。总结一下,转换的规则是:
1、从字符串的左侧开始向右转换,遇到非数字就停止;
2、如果第一个就是非数字,最后的结果就是0;
隐式转换的规则
当操作符与不同类型的操作数一起使用的时候,就会发生隐式转换。
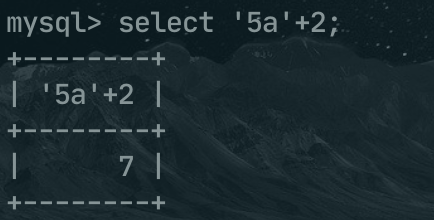
例如算数运算符的前后是不同类型时,会将非数字类型转换为数字,比如 '5a'+2,就会将5a转换为数字类型,然后和2相加,最后的结果就是 7 。
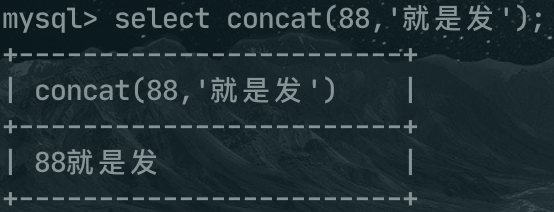
再比如 concat函数是连接两个字符串的,当此函数的参数出现非字符串类型时,就会将其转换为字符串,例如concat(88,'就是发'),最后的结果就是 88就是发。
MySQL 官方文档有以下几条关于隐式转换的规则:
1、两个参数至少有一个是 NULL 时,比较的结果也是 NULL,例外是使用 <=> 对两个 NULL 做比较时会返回 1,这两种情况都不需要做类型转换;
也就是两个参数中如果只有一个是NULL,则不管怎么比较结果都是 NULL,而两个 NULL 的值不管是判断大于、小于或等于,其结果都是1。
2、两个参数都是字符串,会按照字符串来比较,不做类型转换;
3、两个参数都是整数,按照整数来比较,不做类型转换;
4、十六进制的值和非数字做比较时,会被当做二进制字符串;
例如下面这条语句,查询 user 表中name字段是 0x61 的记录,0x是16进制写法,其对应的字符串是英文的 'a',也就是它对应的 ASCII 码。
select * from user where name = 0x61;
所以,上面这条语句其实等同于下面这条
select * from user where name = 'a';
可以用 select 0x61;验证一下。
5、有一个参数是 TIMESTAMP 或 DATETIME,并且另外一个参数是常量,常量会被转换为 时间戳;
例如下面这两条SQL,都是将条件后面的值转换为时间戳再比较了,只不过
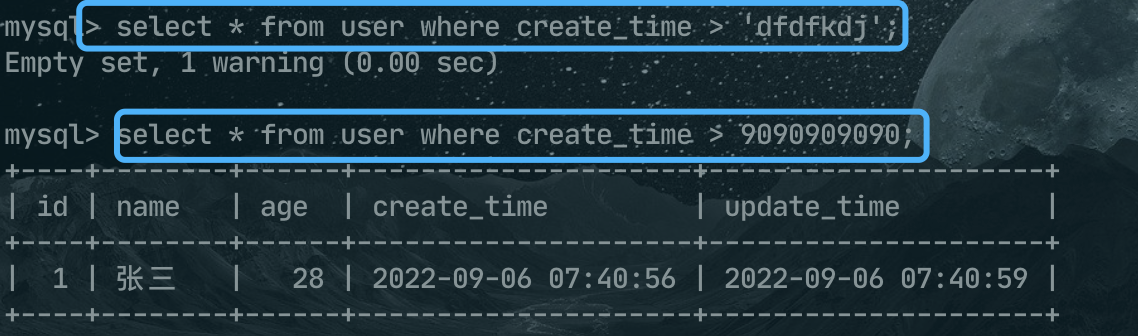
6、有一个参数是 decimal 类型,如果另外一个参数是 decimal 或者整数,会将整数转换为 decimal 后进行比较,如果另外一个参数是浮点数(一般默认是 double),则会把 decimal 转换为浮点数进行比较;
在不同的数值类型之间,总是会向精度要求更高的那一个类型转换,但是有一点要注意,在MySQL 中浮点数的精度只有53 bit,超过53bit之后的话,如果后面1位是1就进位,如果是0就直接舍弃。所以超大浮点数在比较的时候其实只是取的近似值。
7、所有其他情况下,两个参数都会被转换为浮点数再进行比较;
如果不符合上面6点规则,则统一转成浮点数再进行运算
避免进行隐式转换
我们在平时的开发过程中,尽量要避免隐式转换,因为一旦发生隐式转换除了会降低性能外, 还有很大可能会出现不期望的结果,就像我最开始遇到的那个问题一样。
之所以性能会降低,还有一个原因就是让本来有的索引失效。
select * from `order` where order_code = 1;
order_code 是 varchar 类型,假设我已经在 order_code 上建立了索引,如果是用“=”做查询条件的话,应该直接命中索引才对,查询速度会很快。但是,当查询条件后面的值类型不是 varchar,而是数值类型的话,MySQL 首先要对 order_code 字段做类型转换,转换为数值类型,这时候,之前建的索引也就不会命中,只能走全表扫描,查询性能指数级下降,搞不好,数据库直接查崩了。
这位英俊潇洒的少年,如果觉得还不错的话,给个推荐可好!
公众号「古时的风筝」,Java 开发者,全栈工程师,bug 杀手,擅长解决问题。
一个兼具深度与广度的程序员鼓励师,本打算写诗却写起了代码的田园码农!坚持原创干货输出,你可选择现在就关注我,或者看看历史文章再关注也不迟。长按二维码关注,跟我一起变优秀!

一个 MySQL 隐式转换的坑,差点把服务器整崩溃了的更多相关文章
- MySQL隐式转换的坑
MySQL以以下规则描述比较操作如何进行转换: 两个参数至少有一个是 NULL 时,比较的结果也是 NULL,例外是使用 <=> 对两个 NULL 做比较时会返回 1,这两种情况都不需要做 ...
- 关于MySQL隐式转换
一.如果表定义的是varchar字段,传入的是数字,则会发生隐式转换. 1.表DDL 2.传int的sql 3.传字符串的sql 仔细看下表结构,rid的字段类型: 而用户传入的是int,这里会有一个 ...
- Mysql 隐式转换
表定义: CREATE TABLE `ids` ( id ) not null auto_increment, PRIMARY KEY (id) ); 表中存在一些IDs: 111, 112, 113 ...
- MySQL隐式转换测试
Preface There're various data type in MySQL such as number,string,date,time,lob,etc.The data ...
- Mysql隐式类型转换原则
MySQL 的隐式类型转换原则: - 两个参数至少有一个是 NULL 时,比较的结果也是 NULL,例外是使用 <=> 对两个 NULL 做比较时会返回 1,这两种情况都不需要做类型转换 ...
- Scala隐式转换和隐式参数
隐式转换 Scala提供的隐式转换和隐式参数功能,是非常有特色的功能.是Java等编程语言所没有的功能.它可以允许你手动指定,将某种类型的对象转换成其他类型的对象或者是给一个类增加方法.通过这些功能, ...
- MySQL SQL优化之字符串索引隐式转换
之前有用户很不解:SQL语句非常简单,就是select * from test_1 where user_id=1 这种类型,而且user_id上已经建立索引了,怎么还是查询很慢? test_1的表结 ...
- js学习日记-隐式转换相关的坑及知识
隐式转换比较是js中绕不过去的坎,就算有几年经验的工程师也很有可能对这块知识不够熟悉.就算你知道使用===比较从而避免踩坑,但是团队其它成员不一定知道有这样或那样的坑,有后端语言经验的人常常会形成一个 ...
- MySQL性能优化:MySQL中的隐式转换造成的索引失效
数据库优化是一个任重而道远的任务,想要做优化必须深入理解数据库的各种特性.在开发过程中我们经常会遇到一些原因很简单但造成的后果却很严重的疑难杂症,这类问题往往还不容易定位,排查费时费力最后发现是一个很 ...
随机推荐
- 「题解报告」SP16185 Mining your own business
题解 SP16185 Mining your own business 原题传送门 题意 给你一个无向图,求至少安装多少个太平井,才能使不管那个点封闭,其他点都可以与有太平井的点联通. 题解 其他题解 ...
- sys.path的使用场景
起因 在初学python时,经常遇到找不到某个路径下的文件,或者在博客中找到的代码需要暴露出环境变量(如linux中可以export PYTHONPATH="$PYTHON;/carla/b ...
- ifort + mkl + impi (全套intel)编译安装量子化学软件GAMESS 2022 R1版本
说明:linux下编译软件都需要先配置好该软件依赖的系统环境.系统环境可以通过软件的安装说明了解,例如:readme.md等文件或网页.这个前提条件很重要!后面正式编译出错基本都可以归结到系统环境配置 ...
- 通过ftutilx 插件实现流版式文件全文检索
Oracle 支持流版式文件的全文检索,而原生的PostgreSQL是不支持流版式文件全文检索的.KingbaseES 通过ftutilx 插件将流版式文件转换成文本文件,从而支持流版式文件全文检索. ...
- KingbaseES 导入导出blob列数据
KingbaseES兼容了oracle的blob数据类型.通常是用来保存二进制形式的大数据,也可以用来保存其他类型的数据. 下面来验证一下各种数据存储在数据库中形式. 建表 create table ...
- 项目管理构建工具——Maven(基础篇)
项目管理构建工具--Maven(基础篇) 在前面的内容中我们学习了JDBC并且接触到了jar包概念 在后面我们的实际开发中会接触到很多jar包,jar包的导入需要到互联网上进行就会导致操作繁琐 Mav ...
- Python数据科学手册-Pandas:向量化字符串操作、时间序列
向量化字符串操作 Series 和 Index对象 的str属性. 可以正确的处理缺失值 方法列表 正则表达式. Method Description match() Call re.match() ...
- MySQL5.7.15数据库配置主从服务器实现双机热备实例教程
环境说明 程序在:Web服务器192.168.0.57上面 数据库在:MySQL服务器192.168.0.67上面 实现目的:增加一台MySQL备份服务器(192.168.0.68),做为MySQL服 ...
- Centos7主机安装Cockpit管理其他主机
前提条件:需要管理的每台服务器上都需要安装cockpit 假设Centos7主机安装Cockpit的为A,其他主机为B 如果B上有A的公钥,那么直接连接至B,否则,输入B的用户名密码连接. 问题:在A ...
- 使用docker-compose运行nginx容器挂载时遇到的文件/目录问题
单独使用docker run命令指定挂载文件路径运行nginx容器是可以的,但是用在docker-compose中就不行了 报错如下: 原因就是挂载出错,不能直接挂载文件,还有挂载的容器里的目录要正确 ...