【Impala】概念、原理、内外部shell、建库建表、分区、查询、自定义函数、存储压缩

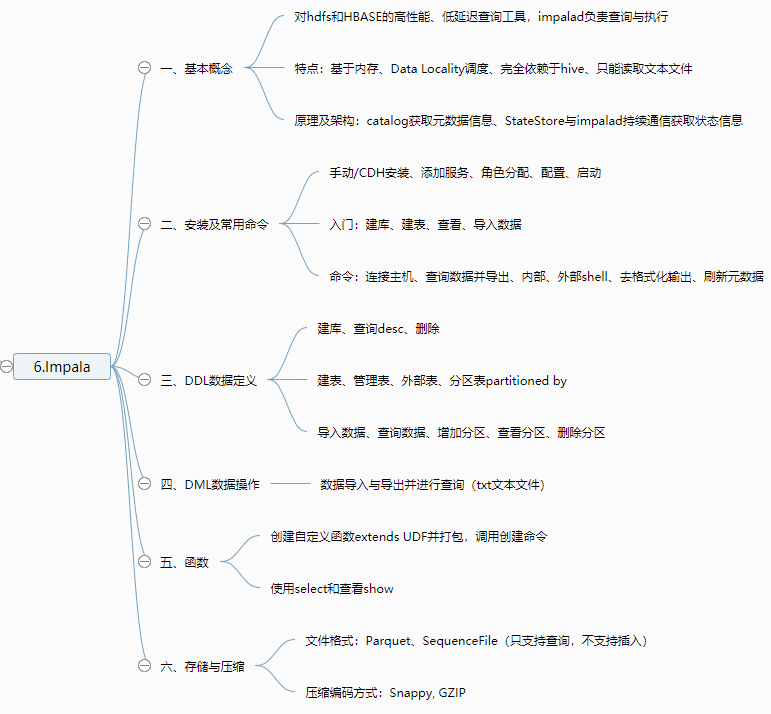
一、基本概念
1、介绍
对HDFS、Hbase数据的高性能、低延迟的交互式SQL查询功能
2、优缺点
优点:基于内存运算,无需写入磁盘,无需转化为MR,支持Data Locality调度(数据和计算在一台机器进行)
缺点:完全依赖于hive,只能读取文本文件
3、组成
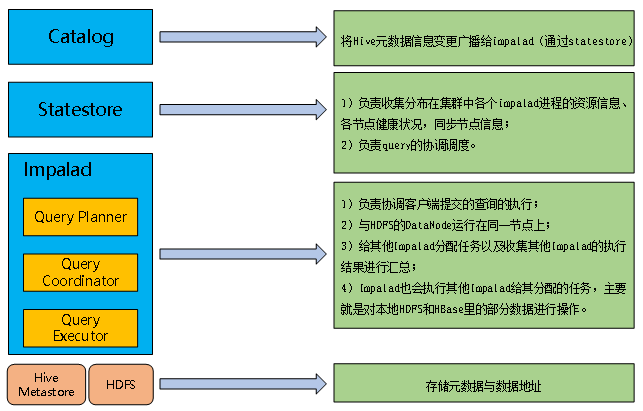
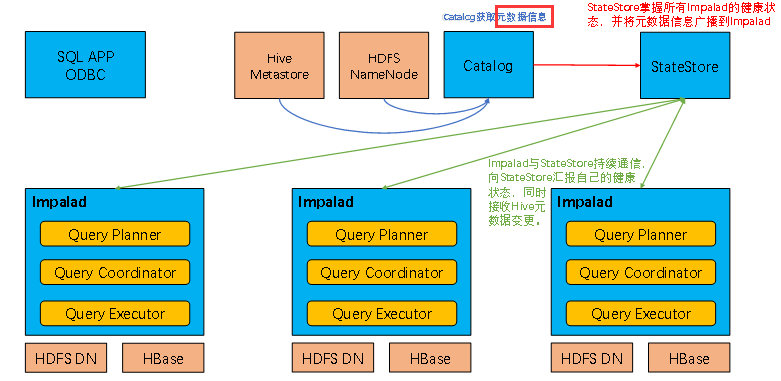
4、原理
二、Impala安装
1、地址
http://impala.apache.org/impala-docs.html
2、安装方式
手动安装与CDH安装-Cloudera Manager
添加服务、角色分配、配置、启动
3、监护管理
StateStore:http://hadoop102:25020/
Catalog:http://hadoop102:25010/
4、入门
启动:impala-shell
查看数据库与表:show databases; / show tables;
导入数据:load data inpath '/student.txt' into table student;
修改hdfs的权限
三、操作命令
1、外部shell
连接指定主机:impala-shell -i hadoop103
查询表中数据并写入文件:impala-shell -q 'select * from student' -o output.txt
建表后刷新元数据:impala-shell -r
显示执行计划:impala-shell -p
去格式化输出:impala-shell -q 'select * from student' -B --output_delimiter="\t" -o output.txt
2、内部shell
查看执行计划:explain select * from student;
查询最近一次的底层信息:profile;
刷新元数据:refresh student;
四、Impala数据类型
|
Hive数据类型 |
Impala数据类型 |
长度 |
|
TINYINT |
TINYINT |
1byte有符号整数 |
|
SMALINT |
SMALINT |
2byte有符号整数 |
|
INT |
INT |
4byte有符号整数 |
|
BIGINT |
BIGINT |
8byte有符号整数 |
|
BOOLEAN |
BOOLEAN |
布尔类型,true或者false |
|
FLOAT |
FLOAT |
单精度浮点数 |
|
DOUBLE |
DOUBLE |
双精度浮点数 |
|
STRING |
STRING |
字符系列。可以指定字符集。可以使用单引号或者双引号。 |
|
TIMESTAMP |
TIMESTAMP |
时间类型 |
|
BINARY |
不支持 |
字节数组 |
五、DDL数据定义
1、创建数据库
CREATE DATABASE [IF NOT EXISTS] database_name
[COMMENT database_comment]
[LOCATION hdfs_path];
2、查询数据库
显示数据库
show databases like 'hive*';
desc database hive_db;
删除数据库
drop database hive_db cascade;
3、创建表
管理表
[hadoop103:21000] > create table if not exists student2(
> id int, name string
> )
> row format delimited fields terminated by '\t'
> stored as textfile
> location '/user/hive/warehouse/student2';
[hadoop103:21000] > desc formatted student2;
外部表
[hadoop103:21000] > create external table stu_external(
> id int,
> name string)
> row format delimited fields terminated by '\t' ;
4、分区表
创建分区表
[hadoop103:21000] > create table stu_par(id int, name string)
> partitioned by (month string)
> row format delimited
> fields terminated by '\t';
表中导入数据
[hadoop103:21000] > alter table stu_par add partition (month='201810');
[hadoop103:21000] > load data inpath '/student.txt' into table stu_par partition(month='201810');
[hadoop103:21000] > insert into table stu_par partition (month = '201811')
> select * from student;
查询数据
增加分区
删除分区
查看分区:show partitions stu_par;
六、DML数据操作
1、数据导入
2、数据导出
impala-shell -q 'select * from student' -B --output_delimiter="\t" -o output.txt
七、查询
与hive语法相似
八、函数
1、自定义函数
导入依赖hive-exec
创建类并打包
package com.atguigu.hive;
import org.apache.hadoop.hive.ql.exec.UDF; public class Lower extends UDF { public String evaluate (final String s) { if (s == null) {
return null;
} return s.toLowerCase();
}
}
创建函数:create function mylower(string) returns string location '/hive_udf-0.0.1-SNAPSHOT.jar' symbol='com.atguigu.hive_udf.Hive_UDF';
使用函数:select ename, mylower(ename) from emp;
通过show functions查看自定义的函数
九、存储和压缩
|
文件格式 |
压缩编码 |
Impala是否可直接创建 |
是否可直接插入 |
|
Parquet |
Snappy(默认), GZIP; |
Yes |
支持:CREATE TABLE, INSERT, 查询 |
|
Text |
LZO,gzip,bzip2,snappy |
Yes. 不指定 STORED AS 子句的 CREATE TABLE 语句,默认的文件格式就是未压缩文本 |
支持:CREATE TABLE, INSERT, 查询。如果使用 LZO 压缩,则必须在 Hive 中创建表和加载数据 |
|
RCFile |
Snappy, GZIP, deflate, BZIP2 |
Yes. |
仅支持查询,在 Hive 中加载数据 |
|
SequenceFile |
Snappy, GZIP, deflate, BZIP2 |
Yes. |
仅支持查询,在 Hive 中加载数据 |
创建parquet格式的表并插入数据进行查询
[hadoop104:21000] > create table student2(id int, name string)
> row format delimited
> fields terminated by '\t'
> stored as PARQUET;
[hadoop104:21000] > insert into table student2 values(1001,'zhangsan');
[hadoop104:21000] > select * from student2;
创建sequenceFile格式的表,插入数据时报错
[hadoop104:21000] > insert into table student3 values(1001,'zhangsan');
Query: insert into table student3 values(1001,'zhangsan')
Query submitted at: 2018-10-25 20:59:31 (Coordinator: http://hadoop104:25000)
Query progress can be monitored at: http://hadoop104:25000/query_plan?query_id=da4c59eb23481bdc:26f012ca00000000
WARNINGS: Writing to table format SEQUENCE_FILE is not supported. Use query option ALLOW_UNSUPPORTED_FORMATS to override.
【Impala】概念、原理、内外部shell、建库建表、分区、查询、自定义函数、存储压缩的更多相关文章
- MySQL建库建表
一直使用SQL SERVER 数据库:最近项目使用MY SQL感觉还是有一点不适应.不过熟悉之后就会好很多. MY SQL 安装之后会有一个管理工具MySQL Workbench 感觉不太好用,数据库 ...
- 【ITOO 2】.NET 动态建库建表:使用SQL字符串拼接方式
导读:在最近接手的项目(高效云平台)中,有一个需求是要当企业用户注册时,给其动态的新建一个库和表.刚开始接手的时候,是一点头绪都没有,然后查了一些资料,也问了问上一版本的师哥师姐,终于有了点头绪.目前 ...
- 【ITOO 3】.NET 动态建库建表:实用EF框架提供的codeFirst实现动态建库
导读:在上篇博客中,介绍了使用SQL字符拼接的方式,实现动态建库建表的方法.这样做虽然也能够实现效果,但是,太麻烦,而且,如果改动表结构,字段的话,会对代码修改很多.但是EF给我们提供了一种代码先行的 ...
- SQL Server建库-建表-建约束
----------------------------------------SQL Server建库-建表-建约束创建School数据库------------------------------ ...
- 使用T-sql建库建表建约束
为什么要使用sql语句建库建表? 现在假设这样一个场景,公司的项目经过测试没问题后需要在客户的实际环境中进行演示,那就需要对数据进行移植,现在问题来了:客户的数据库版本和公司开发阶段使用的数据库不兼容 ...
- mysql那些事(4)建库建表编码的选择
mysql建数据库或者建表的时候会遇到选择编码的问题,以前我们都是习惯性的选择utf8,但是在mysql在5.5.3版本后加了utf8mb4的编码,utf8mb4可以存4个字节Unicode,mb4就 ...
- C# 利用*.SQL文件自动建库建表等的类
/// <summary> /// 自动建库建表 /// </summary> public class OperationSqlFile { SqlConnection sq ...
- Mysql建库建用户建表等常用命令
格式: mysql -h主机地址 -u用户名 -p用户密码 1.连接到本机上的MYSQL.首先打开DOS窗口,然后进入目录mysql\bin,再键入命令mysql -u root -p,回车后提示你输 ...
- oracle 11g 建库 建表 增 删 改 查 约束
一.建库 1.(点击左上角带绿色+号的按钮) 2.(进入这个界面,passowrd为密码.填写完后点击下面一排的Test按钮进行测试,无异常就点击Connect) 二.建表 1-1. create t ...
- SQL_DDL_建库建表
--IF DB_ID('testdb') IS NULL --CREATE DATABASE testdb USE master GO IF EXISTS ( SELECT * FROM sys.da ...
随机推荐
- 使用shell脚本定时重启tomcat服务
#!/bin/bash DATE=`date +%Y-%m-%d-%H-%M-%S` echo "当前时间是:$DATE" # 根据端口号查找进程 PID=`/usr/sbin/l ...
- Elasticsearch与MySQL对应关系表
MySQL 中的数据库(DataBase),等价于 ES 中的索引(Index). MySQL 中一个数据库下面有 N 张表(Table),等价于1个索引 Index 下面有 N 多类型(Type). ...
- 20220929-ArrayList扩容机制源码分析
示例代码 public class ArrayListSource { public static void main(String[] args) { ArrayList arrayList = n ...
- 微信小程序发布与支付
一.小程序的发布流程 小程序协同工作和发布官网链接 1.背景 小程序的平台里,开发者完成开发之后,需要在开发者工具提交小程序的代码包,然后在小程序后台发布小程序. 2.流程 上传代码 代码管理服务器上 ...
- Vue3 Vite3 多环境配置 - 基于 vite 创建 vue3 全家桶项目(续篇)
在项目或产品的迭代过程中,通常会有多套环境,常见的有: dev:开发环境 sit:集成测试环境 uat:用户接收测试环境 pre:预生产环境 prod:生产环境 环境之间配置可能存在差异,如接口地址. ...
- JavaScript之无题之让人烦躁的模块化
我怎么记得我好像写过相关类型的文章,但是我找遍了我的博客没有-那就再写一遍吧,其实模块化的核心内容也算不上是复杂,只不过需要整理一下,规划一下罢了.嘻嘻. 开始写标题的时候我就在纠结一件事情,就是,先 ...
- 利用Java集合实现学生信息的”增删查“
之前学了Java中的集合,打算写一个小程序来消化一下! 那么我们知道,集合相比数组的优点就是可以动态的增加元素,这对比数组来说,十分的便捷: 并且集合为我们封装好一些方法,可以更好的做一些数据操作! ...
- 修改-Python函数-2
一.导入 $$f ( x , y ) = 2 x + 3 y$$ 上面括号里面的就是数学公式里的自变量,自变量就相当于函数里的参数. 二.为什么要有参数 如果一个大楼里有两种尺寸不一的窗户,显然在没有 ...
- 图解 | 聊聊 MyBatis 缓存
首发公众号-悟空聊架构:图解 | 聊聊 MyBatis 缓存 你好,我是悟空. 本文主要内容如下: 一.MyBatis 缓存中的常用概念 MyBatis 缓存:它用来优化 SQL 数据库查询的,但是可 ...
- Mysql+Mycat+NFS+Rsync+LVS+DNS+IPtables综合实验
1.环境准备 服务器 IP地址 作用 系统版本 Mysql-master eth0:10.0.0.58 主数据库 Rocky8.6 Mysql-slave1 eth0:10.0.0.68 备数据库 R ...