自然语言处理NLP程序包(NLTK/spaCy)使用总结
NLTK和SpaCy是NLP的Python应用,提供了一些现成的处理工具和数据接口。下面介绍它们的一些常用功能和特性,便于对NLP研究的组成形式有一个基本的了解。
NLTK
Natural Language Toolkit (NLTK) 由宾夕法尼亚大学开发,提供了超过50种语料库,以及一些常用的文本处理函数,例如分词(Tokenization)、词干(Stemming)、词性标记(Tagging)等。
下面主要介绍WordNet语料库,其它方法和接口等用到了再进行记录。
WordNet
在WordNet中,每个词由于可以有多重词义,因此会被包含在多个同义词集中。每个同义词集中又包含多个这个意思下的所有词汇(Lemma, 词元)。WordNet还对所有词义(动词和名词)进行了包含与被包含关系的层次排序。因此词义之间得以组成一种树状结构。此外,WordNet还包含量化两个词之间相似度的方法。
同义词集
同义词集用三元组表示,如下展示了channel被包含的所有同义词集:
import nltk
from nltk.corpus import wordnet
a = wordnet.synsets('channel')
print(a)

如channel.n.01表示channel的第一个名词词义。此外channel还有impart.v.03词义,表示impart的第三个动词词义。我们可以看同义词集的解释、例子和这个同义词下的所有词元:
a = wordnet.synsets('channel')[0] #获取一个同义词集,
# a = wordnet.synset('channel.n.01') # 或直接用 wordnet.synset('channel.n.01')
print(a.definition())
print(a.examples())
print(a.lemmas())

其中同义词下的词元用四元组表示。
反义词
由于一个词有多种意思,因此获取反义词需要通过四元组词元(lemma)。
synset1 = wordnet.synsets('good')[1]
lemma1 = synset1.lemmas()[0]
print("Lemma 1: ", lemma1)
print("Meaning 1: ", synset1.definition())
lemma2 = lemma1.antonyms()[0]
synset2 = lemma2.synset()
print("Lemma 2: ", lemma2)
print("Meaning 2: ", synset2.definition())

上下位词
根据WordNet的树状结构可以获取某个词集的上下位词集,及其对应的根节点、到根节点的路径。当然只对名词和动词有效,形容词和副词没有上下级的类别层次关系。
syn = wordnet.synsets('knife')[0] #获取某个同义词集
print("Upper: ", syn.hypernyms(), end="\n\n") # 上位词
print("Lower: ", syn.hyponyms(), end="\n\n") # 下位词
print("Root: ", syn.root_hypernyms(), end="\n\n") # 根节点
print("Path: ", syn.hypernym_paths(), end="\n\n") # 到根节点的路径
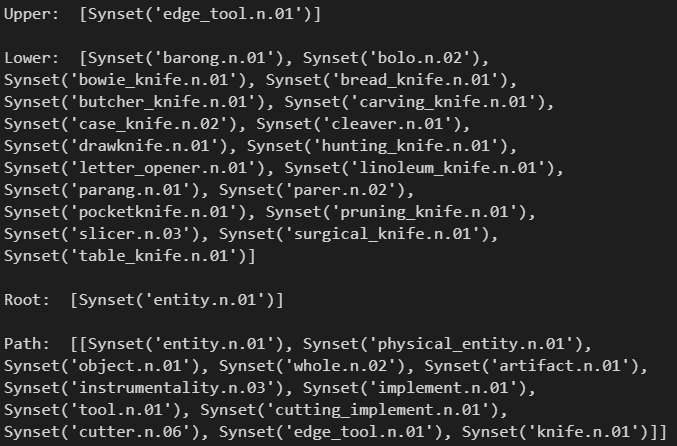
我们可以画出树形结构示意图如下:
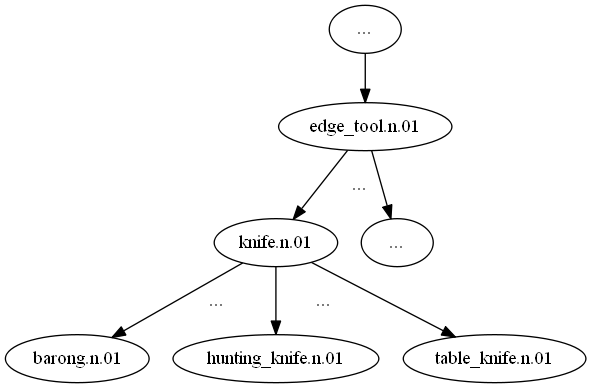
词之间的相似度
利用层次关系,WordNet可以计算名词、动词之间的相似性。
def similarity_with_upper(syn):
a = wordnet.synset(syn)
b = wordnet.synset(syn).hypernyms()[0]
print("Distance: ", a.shortest_path_distance(b)) # 两个同义词集之间的距离
print("Path similarity: ", a.path_similarity(b)) # 路径相似度,由两个词集之间的距离决定
print("Distance to root: ", b.hypernym_paths()[0].__len__()) # 到根节点的路径
print("Wup-Palmer similarity: ", a.wup_similarity(b)) # Wu-Palmer相似度,由两个词集所属的共同最深上位词集的深度决定
print("LCH similarity: ", a.lch_similarity(b)) # LCH相似度,由以上两个指标决定
print() similarity_with_upper('human.n.01')
similarity_with_upper('animal.n.01')
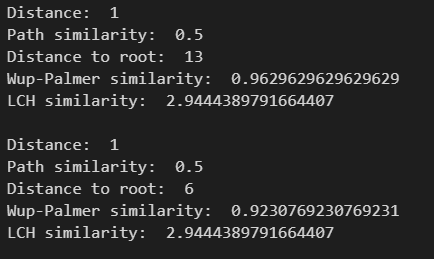
以上分别计算了路径相似度、Wu-Palmer相似度和LCH相似度。可以看出,两个词集所属的共同最深上位词集越深,它们的共同含义越具体,Wup-Palmer相似度越大。另外,经过测试,发现动词集与名词集分别属于不同的树,因此它们之间无法计算相似性。
形容词簇
对于形容词,WordNet将它们的词义分为中心 (Head, a) 同义词集与卫星 (Satellite, s) 同义词集。一个中心通常围绕一个或多个卫星同义词集,从而形成一个簇。而中心同义词集则表示这个整个簇的基本概念。可以通过similar_tos()获取一个中心同义词集的所有卫星。
a = wordnet.synset("glorious.a.01")
a.similar_tos()

结构图如下:

句子词性标注
NLTK用了一些当前推荐的方法来对词性进行标注,内部应该是用了一些人为定义的规则加上神经网络。
s = "A man struck my video camera with a hammer."
text = nltk.word_tokenize(s) # 将句子划分为词列表,英语很简单类似于.split(' '),但其他语言如中文就不一定了
tag1 = nltk.pos_tag(text)
tag2 = nltk.pos_tag(text, tagset='universal')
print("Tag1: ", tag1, end='\n\n')
print("Tag2: ", tag2)

加上universal参数是直接分析单个词的基本词性,不加则默认进行更细粒度的Penn Treebank POS Tags划分。
SpaCy
SpaCy提供了分词(Tokenization)、词性标注(Part-Of-Speech Tagging)、依赖关系分析(Dependency Parsing)、命名实体识别(Named Entity Recognization)、停用词识别(Stop Words)、名词短语提取(Noun Chunks)等方法,以及展示句子依赖关系的可视化工具。
获取神经网络模型
SpaCy的NLP方法主要通过神经网络实现,因此在使用前需要下载安装相应的神经网络模型。SpaCy内部并没有提供模型的下载接口,需要我们通过python调用命令下载安装。各类语言模型的介绍可以通过以下网址查看:
https://github.com/explosion/spacy-models/releases
在SpaCy安装好后(pip直接安装),通过如下命令安装所需的神经网络模型:
python -m spacy download en_core_web_lg
其中en_core_web_lg为模型的名称:en表示英语,如zh表示中文;web表示该模型利用网页数据进行预训练,另外还有news等;lg表示下载大模型,如sm为小模型,trf则为基于transformer的模型。
基本功能
下载好语言模型后导入。然后将需要进行处理的文本输入模型中:
import spacy
model = spacy.load("zh_core_web_lg")
text = '无法改变想法的人,什么事情也改变不了。——萧伯纳'
output = model(text)
分词、词性标注、依赖关系分析、命名实体识别、停用词识别:
print('分词: ', end='\t')
for i in output:
print(i.text, end='\t')
print('\n粗粒度词性: ', end='\t')
for i in output:
print(i.pos_, end='\t')
print('\n细粒度词性: ', end='\t')
for i in output:
print(i.tag_, end='\t')
print('\n依赖关系:', end='\t')
for i in output:
print(i.dep_, end='\t')
print('\n命名实体识别:', end='\t')
for i in output:
print(i.ent_type_, end='\t')
print('\n停用词识别:', end='\t')
for i in output:
print(i.is_stop, end='\t')

名词短语提取在中文模型中没有,英文模型中用output.noun_chunks获取。
另外,可视化方法如下:
from spacy import displacy
html = displacy.render(output, style="ent", jupyter=False) #命名实体可视化
f = open('html1.html', 'w')
f.write(html)
html = displacy.render(output, style="dep", jupyter=False) #依赖关系可视化
f = open('html2.html', 'w')
f.write(html)
输出html矢量图
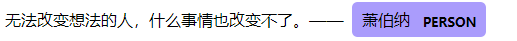

StanfordNLP
另外还有斯坦福的库,以后要用再记录。。特性:支持中文等53种语言、内置许多NLP神经网络模型、包含大量语义分析工具。
自然语言处理NLP程序包(NLTK/spaCy)使用总结的更多相关文章
- 【NLP】Python NLTK获取文本语料和词汇资源
Python NLTK 获取文本语料和词汇资源 作者:白宁超 2016年11月7日13:15:24 摘要:NLTK是由宾夕法尼亚大学计算机和信息科学使用python语言实现的一种自然语言工具包,其收集 ...
- 自然语言处理(NLP) - 数学基础(1) - 排列组合
正如我在<自然语言处理(NLP) - 数学基础(1) - 总述>一文中所提到的NLP所关联的概率论(Probability Theory)知识点是如此的多, 饭只能一口一口地吃了, 我们先 ...
- 【NLP】Python NLTK处理原始文本
Python NLTK 处理原始文本 作者:白宁超 2016年11月8日22:45:44 摘要:NLTK是由宾夕法尼亚大学计算机和信息科学使用python语言实现的一种自然语言工具包,其收集的大量公开 ...
- 【NLP】Python NLTK 走进大秦帝国
Python NLTK 走进大秦帝国 作者:白宁超 2016年10月17日18:54:10 摘要:NLTK是由宾夕法尼亚大学计算机和信息科学使用python语言实现的一种自然语言工具包,其收集的大量公 ...
- 自然语言处理NLP快速入门
自然语言处理NLP快速入门 https://mp.weixin.qq.com/s/J-vndnycZgwVrSlDCefHZA [导读]自然语言处理已经成为人工智能领域一个重要的分支,它研究能实现人与 ...
- R+NLP︱text2vec包——四类文本挖掘相似性指标 RWMD、cosine、Jaccard 、Euclidean (三,相似距离)
要学的东西太多,无笔记不能学~~ 欢迎关注公众号,一起分享学习笔记,记录每一颗"贝壳"~ --------------------------- 在之前的开篇提到了text2vec ...
- 自然语言处理(NLP)
苹果语音助手Siri的工作流程: 听 懂 思考 组织语言 回答 这其中每一步骤涉及的流程为: 语音识别 自然语言处理 - 语义分析 逻辑分析 - 结合业务场景与上下文 自然语言处理 - 分析结果生成自 ...
- 自然语言处理(NLP) - 数学基础(1) - 总述
正如我在<2019年总结>里说提到的, 我将开始一系列自然语言处理(NLP)的笔记. 很多人都说, AI并不难啊, 调现有库和云的API就可以啦. 然而实际上并不是这样的. 首先, AI这 ...
- 国内外自然语言处理(NLP)研究组
国内外自然语言处理(NLP)研究组 *博客地址 http://blog.csdn.net/wangxinginnlp/article/details/44890553 *排名不分先后.收集不全,欢迎 ...
随机推荐
- 解决报错ExecStart=/usr/sbin/mysqld --daemonize --pid-file=/run/mysqld/mysqld.pid (code
问题的由来 MySQL服务没有正常关机,是电脑没电后自动关机产生,记录一下排查过程 1.本以为是pid的问题,上网找了教程,解决不了,然后看日志看了网上各种说是数据库内存溢出 2021-03-12T1 ...
- Java的基础语法01
一. 注释,标识符,关键字 书写注释是一种习惯的养成,当我们一段代码完成后,长时间没有回顾,便会产生遗忘,所以注释是给我们写代码的人看的.1.注释 //单行注释 /*多行注释*/ /**文档注释也叫文 ...
- LCA——树上倍增
首先,什么是LCA? LCA:最近公共祖先 祖先:从当前点到根节点所经过的点,包括他自己,都是这个点的祖先 A和B的公共祖先:同时是A,B两点的祖先的点 A和B的最近公共祖先:深度最大的A和B的公共祖 ...
- python在管道中执行命令
简介 在实际开发中,可能在执行命令过程中,需要在命令的管道中输入相应命令后继续执行,因此需要在执行命令后在命令的管道中输入相应指令 方法一 直接使用communicate向管道传入所需指令,注意如果是 ...
- SpringCloud gateway自定义请求的 httpClient
本文为博主原创,转载请注明出处: 引用 的 spring cloud gateway 的版本为 2.2.5 : SpringCloud gateway 在实现服务路由并请求的具体过程是在 org.sp ...
- 技术分析 | 通过DML语句浅谈binlog和redo log
欢迎来到 GreatSQL社区分享的MySQL技术文章,如有疑问或想学习的内容,可以在下方评论区留言,看到后会进行解答 GreatSQL社区原创内容未经授权不得随意使用,转载请联系小编并注明来源. 1 ...
- DolphinScheduler 荣获 2021 中国开源云联盟优秀开源项目奖!
点击上方 蓝字关注我们 好消息,中国开源云联盟(China Open Source Cloud League,简称"COSCL")于近日公布 2021 杰出开源贡献者.优秀开源项目 ...
- [C#]使用 AltCover 获得代码覆盖率 - E2E Test 和 Unit Test
背景 在 CI/CD 流程当中,测试是 CI 中很重要的部分.跟开发人员关系最大的就是单元测试,单元测试编写完成之后,我们可以使用 IDE 或者 dot cover 等工具获得单元测试对于业务代码的覆 ...
- 大数据Hadoop入门教程 | (一)概论
数据是什么 数据是指对客观事件进行记录并可以鉴别的符号,是对客观事物的性质.状态以及相互关系等进行记载的物理符号或这些物理符号的组合,它是可识别的.抽象的符号. 它不仅指狭义上的数字,还可以是具有一定 ...
- [CSharpTips]判断两条线段是否相交
判断两条线段是否相交 主要用到了通过向量积的正负判断两个向量位置关系 向量a×向量b(×为向量叉乘),若结果小于0,表示向量b在向量a的顺时针方向:若结果大于0,表示向量b在向量a的逆时针方向:若等于 ...