zabbix自定义自动发现模板
需求:
自定义发现磁盘io,并实现监控。其他的业务组件自动发现监控其实也和这个大同小异,自动发现主要逻辑就是你要根据组件规则自动匹配出需要监控的所有组件,再通过传参的方式获取对应组件数据。
自动发现无非分为几个步骤:
写一个脚本获取需要监控的系统信息,如所有磁盘标识或者一些组件名称等,脚本输出json格式到zabbix server,再写一个脚本根据传参,获取单独磁盘监控数据。
1、被监控端编写脚本,输出agent所有的磁盘json格式
vim /etc/zabbix/scripts/disk_discovery.sh
#!/bin/bash
diskarray=(`cat /proc/diskstats |grep -E "\bsd[abcdefg]\b|\bxvd[abcdefg]\b"|grep -i "\b$1\b"|awk '{print $3}'|sort|uniq 2>/dev/null`)
length=${#diskarray[@]}
printf "{\n"
printf '\t'"\"data\":["
for ((i=0;i<$length;i++))
do
printf '\n\t\t{'
printf "\"{#DISK_NAME}\":\"${diskarray[$i]}\"}"
if [ $i -lt $[$length-1] ];then
printf ','
fi
done
printf "\n\t]\n"
printf "}\n"
执行结果:这就获取到了磁盘标识了
[root@YFSJZX scripts]# bash disk_discovery.sh
{
"data":[
{"{#DISK_NAME}":"sda"}
]
}
2、被监控端编写脚本获取相关的io情况
vim disk_status.sh
#/bin/sh
device=$1
DISK=$2
case $DISK in
read.ops)
/bin/cat /proc/diskstats | grep "\b$device\b" | head -1 | awk '{print $4}' #//磁盘读的次数
;;
read.ms)
/bin/cat /proc/diskstats | grep "\b$device\b" | head -1 | awk '{print $7}' #//磁盘读的毫秒数
;;
write.ops)
/bin/cat /proc/diskstats | grep "\b$device\b" | head -1 | awk '{print $8}' #//磁盘写的次数
;;
write.ms)
/bin/cat /proc/diskstats | grep "\b$device\b" | head -1 | awk '{print $11}' #//磁盘写的毫秒数
;;
io.active)
/bin/cat /proc/diskstats | grep "\b$device\b" | head -1 | awk '{print $12}' #//I/O的当前进度,
;;
read.sectors)
/bin/cat /proc/diskstats | grep "\b$device\b" | head -1 | awk '{print $6}' #//读扇区的次数(一个扇区的等于512B)
;;
write.sectors)
/bin/cat /proc/diskstats | grep "\b$device\b" | head -1 | awk '{print $10}' #//写扇区的次数(一个扇区的等于512B)
;;
io.ms)
/bin/cat /proc/diskstats | grep "\b$device\b" | head -1 | awk '{print $13}' #//花费在IO操作上的毫秒数
;;
esac
3、在客户端中的zabbix_agent.conf 中一起配置
UserParameter=disk.discovery,/etc/zabbix/scripts/disk_discovery.sh
UserParameter=disk.status[*],/etc/zabbix/scripts/disk_status.sh $1 $2
要注意的是以上两个文件需要给x 执行权限。
重启zabbix-agent
4、添加模板
首先创建一个新的模板,在新的模板里面点击“探索发现”或者“自动发现”,版本不一样名称不一样。
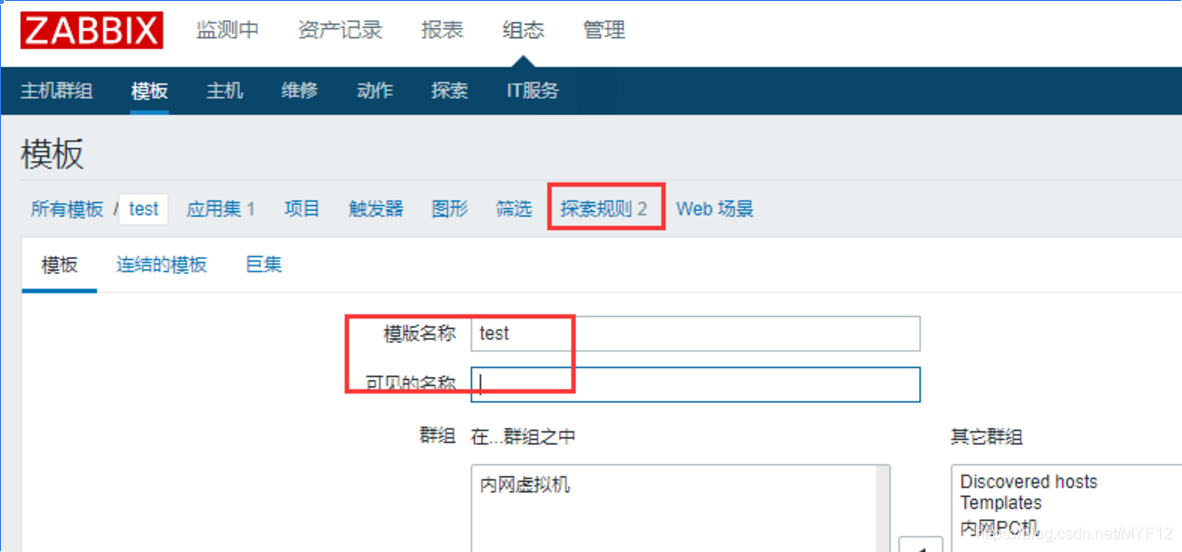
创建发现规则:
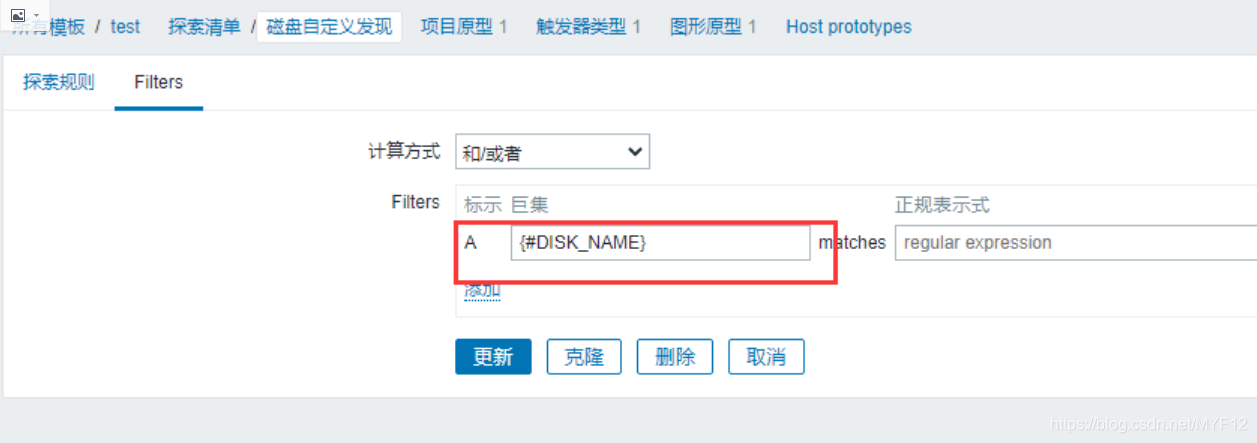
注意:不需要添加过滤器也可以,我添加了两个定义获取不到。取消或者只加一个的话就可以获取。可以尝试加过滤器,不行再取消看看。
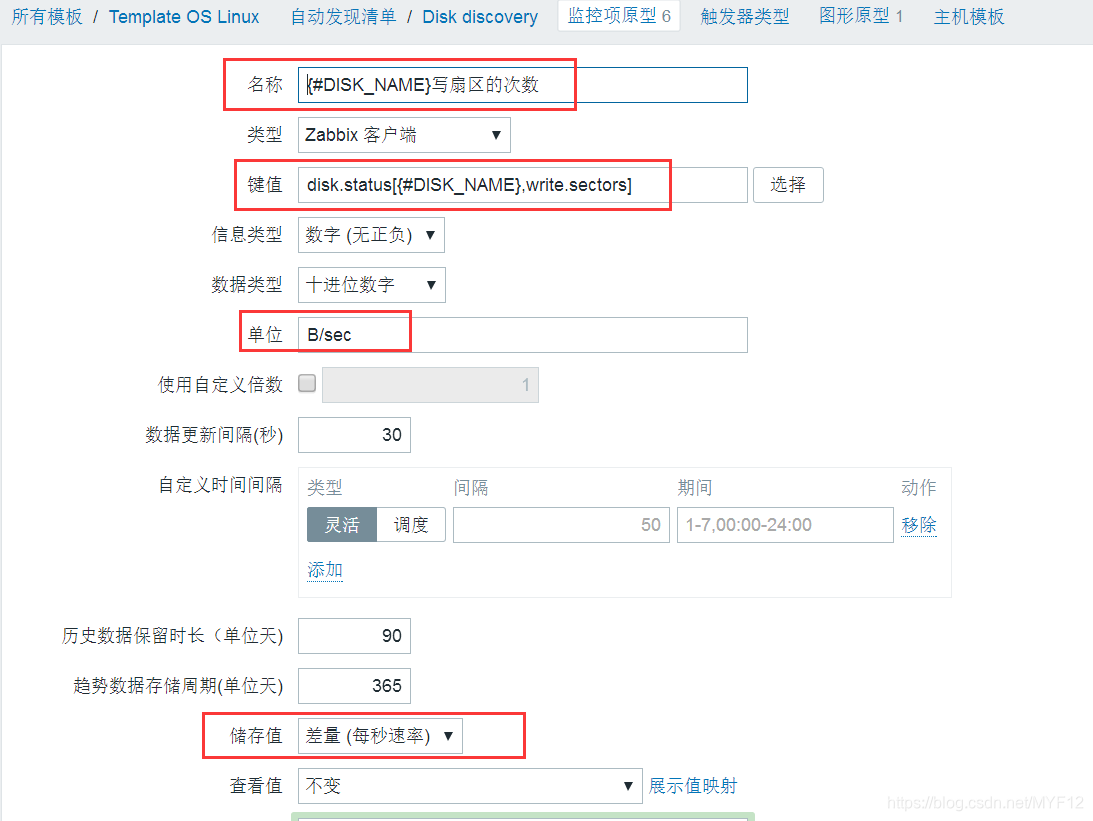
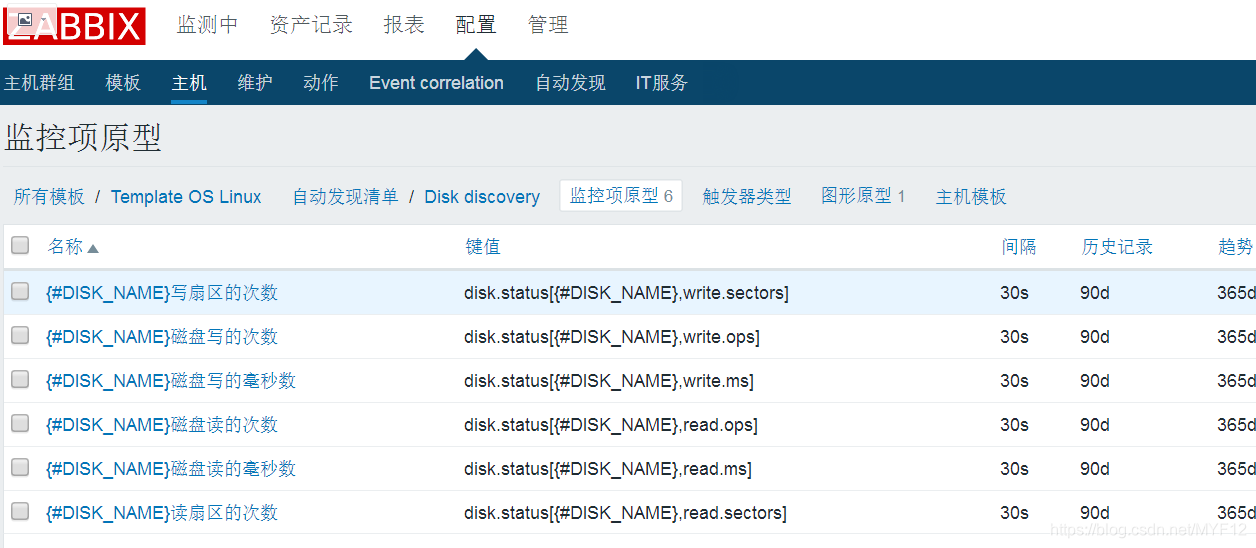
5、添加监控项原型
按照上面的内容添加第一个写扇区的次数监控,接下来按下面的内容添加共6个内容。
内容介绍
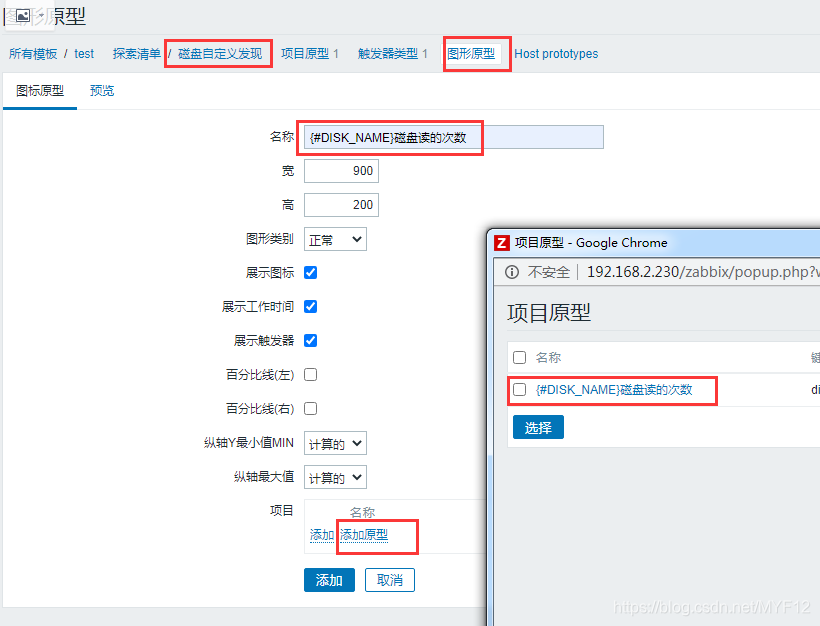
名称: {#DISK_NAME}磁盘读的次数
键值: disk.status[{#DISK_NAME},read.ops]
单位: ops/second
储存值:差量(每秒速率)
名称: {#DISK_NAME}磁盘写的次数
键值: disk.status[{#DISK_NAME},write.ops]
单位: ops/second
储存值:差量(每秒速率)
名称: {#DISK_NAME}磁盘读的毫秒数
键值: disk.status[{#DISK_NAME},read.ms]
单位: ms
储存值:差量(每秒速率)
名称: {#DISK_NAME}磁盘写的毫秒数
键值: disk.status[{#DISK_NAME},write.ms]
单位: ms
储存值:差量(每秒速率)
名称: {#DISK_NAME}读扇区的次数
键值: disk.status[{#DISK_NAME},read.sectors]
单位: B/sec
使用自定义倍数: 512
储存值:差量(每秒速率)
名称: {#DISK_NAME}写扇区的次数
键值: disk.status[{#DISK_NAME},write.sectors]
单位: B/sec
使用自定义倍数: 512
储存值:差量(每秒速率)
6、添加触发器
触发器名称可以这么定义:{#DISK_NAME}磁盘读的次数,{#DISK_NAME}为第1步json格式输出的值。

触发之后是这样样子:{#DISK_NAME}会转化成对应的值
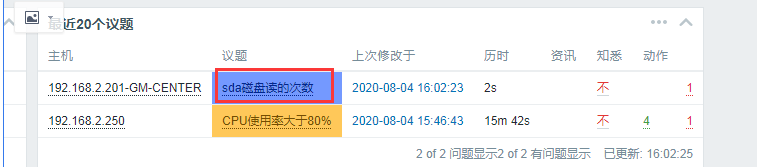
7、添加图形
zabbix自定义自动发现模板的更多相关文章
- zabbix的自动发现、自定义添加监控项目、配置邮件告警
1.zabbix的自动发现这里的自动发现,所显示出来的是规则的上自动了现 然后 可以对其内容进行相关的配制,如时间或周期 注意:对于单个主机的规则,可以自行添加或删除, 但对于已经添加好了的规则,若需 ...
- 01 - zabbix | LLD自动发现
01 - zabbix | LLD自动发现 1. 原理 zabbix支持设置变量,用{#VAR_NAME}来表示.然后有一些系统保留的变量 2. 设置 2.1 交换机电源自动发现 名字写好后进进入 ...
- zabbix使用自动发现监控esxi的磁盘存储storage
zabbix使用自动发现监控esxi的磁盘存储storage 在任意一台可以访问vcenter的zabbix-agent服务器上添加exsi的磁盘监控模板即可 创建模板过程: custom.esxi. ...
- 【Zabbix】Zabbix Server自动发现
Zabbix自动发现 由于有上百台的虚拟机需要监控,如果一个个去添加配置,费时费力.Zabbix的自动发现,可以自动发现需要监控的机器,监控相应指标. 前置条件 安装部署好Zabbix Server. ...
- Zabbix 默认网络发现模板修改(第三篇)
zabbix 默认网络发现模板不能显示ip,我想让他在graph的标题上显示ip,具体要像如下效果 原文地址:http://www.cnblogs.com/caoguo/p/4977254.html ...
- zabbix实现自定义自动发现的流程
前言 本章介绍如何去自定义一个zabbix自动发现的整个流程 过程 首先需要在模板当中创建一个自动发现的规则,这个地方只需要一个名称和一个键值,例如 名称:Ceph Cluster Pool Disc ...
- zabbix mysql自动发现规则
1.配置mysql,添加监控用的账号,授予查看所有用户线程/连接的权限 GRANT PROCESS ON *.* TO 'zabbix'@'127.0.0.1' identified BY '20c1 ...
- zabbix低级自动发现之mysql多实例
1.低级自动发现概述 zabbix的低级自动发现(LLD)适用于监控多实例,监控变化的数据(分区.网卡). 自动发现(LLD)提供了一种在计算机上为不同实体自动创建监控项,触发器和图形的方法.例如,Z ...
- Zabbix自定义监控项(模板)
虽然Zabbix提供了很多的模板(简单理解为监控项的集合),在zabbix界面点击share按钮就可以直接跳到模板大全的官方网站,但是由于模板内的监控项数量太多不好梳理且各种模板质量参差不齐,还是建议 ...
随机推荐
- 软件工程homework-001
一. 回顾你过去将近3年的学习经历 1.当初你报考的时候,是真正喜欢计算机这个专业吗? 答:不喜欢,高中时候就已经对计算机比较抵触了,家里小时候比较富裕,九几年就在日本买了第一批家用台式机 ...
- ArcMap操作随记(11)
1.直方图 在[Spatial Analyst]工具条中 2.分辨率变换 [重采样] :①最近邻法 ②双线性 ③三次卷积 重采样过程中要注意Nodata值 3.用ArcGIS进行监督分类 [影像分类] ...
- 《手把手教你》系列基础篇(七十八)-java+ selenium自动化测试-框架设计基础-TestNG依赖测试- 中篇(详解教程)
1.简介 上一篇讲解了依赖测试的各种方法,今天继续讲解依赖测试的方法,这一篇主要是讲解和分享通过xml文件配置组名依赖方法( 主要是测试组的用法).废话不说,直接上干货. 2.实例 测试组:一个组可包 ...
- hashCode()方法的作用?
hashCode()方法与equals()方法相似,都是来自java.lang.Object类的方法,都允许用户定义的子类重写这两个方法. 一般来说,equals这个方法是给用户调用的,如果你想根据自 ...
- jpg, jpeg和png区别?
jpg是jpeg的缩写, 二者一致 PNG就是为取代GIF而生的, 无损压缩, 占用内存多 jpg牺牲图片质量, 有损, 占用内存小 PNG格式可编辑.如图片中有字体等,可利用PS再 ...
- 面试问题之数据结构与算法:map与unordered_map
转载于:https://blog.csdn.net/u011475134/article/details/75810085 map map是STL的一个关联容器,它提供一对一数据处理能力.map内部自 ...
- MySQL 中 InnoDB 支持的四种事务隔离级别名称,以及逐 级之间的区别?
SQL 标准定义的四个隔离级别为: 1.read uncommited :读到未提交数据 2.read committed:脏读,不可重复读 3.repeatable read:可重读 4.seria ...
- kafka-linux-install
linux按照kafka 必须先按照java jdk包!!!!!!!!!!!! 先安装zookeeper 下载:http://mirrors.hust.edu.cn/apache/zookeeper/ ...
- su 和 sudo的区别
su是一个命令,可切换其他用户进行操作:而 '-' 号则是代表是否完全切换指定的用户环境信息 sudo是一个服务,可通过/etc/sudoers进行配置文件,让被限制的用户只能执行被授予的命令操作.
- RocketMQ实现分布式事务
相关文章:http://www.uml.org.cn/zjjs/201810091.asp(深入理解分布式事务,高并发下分布式事务的解决方案) 三种分布式事务: 1.基于XA协议的两阶段提交 2.消息 ...