torch7框架 深度学习(1)
前面已经安装好了torch,下面就来看看如何在torch框架上搭建深度学习模型,我一直觉得源码结合原理是机器学习最好的学习途径。所以我们从分析一个简单的案例开始吧。
这个例子呢,主要是以有监督的方式构建一个深度学习模型实现对数据集SVHN的分类。
SVHN是 The Street View House Numbers Dataset, 数据集介绍见 SVHN数据集
代码主要分为五个部分
数据的预处理
网络模型的构建
损失函数的定义
训练网络
测试数据
数据的预处理
- require 'torch' -- torch
- require 'image' -- to visualize the dataset
- require 'nn' -- provides a normalization operator
加载头文件
- if not opt then
- print '==> processing options'
- cmd = torch.CmdLine()
- cmd:text()
- cmd:text('SVHN Dataset Preprocessing')
- cmd:text()
- cmd:text('Options:')
- cmd:option('-size', 'small', 'how many samples do we load: small | full | extra')
- cmd:option('-visualize', true, 'visualize input data and weights during training')
- cmd:text()
- opt = cmd:parse(arg or {})
- end
文件的命令行参数。主要有两个参数(文件大小和是否可视化选项),torch.CmdLine()函数参见torch.CmdLine()
- www = 'http://data.neuflow.org/data/housenumbers/'
- train_file = 'train_32x32.t7'
- test_file = 'test_32x32.t7'
- extra_file = 'extra_32x32.t7'
- if not paths.filep(train_file) then
- os.execute('wget ' .. www .. train_file)
- end
- if not paths.filep(test_file) then
- os.execute('wget ' .. www .. test_file)
- end
- if opt.size == 'extra' and not paths.filep(extra_file) then
- os.execute('wget ' .. www .. extra_file)
- end
用于数据集的下载,数据集网址,但是这个网址好像被墙了,访问不了。所以我自己令下载的数据集SVHN,其中只下载了 train_32x32.mat和 test_32x32.mat文件,因为数据太大机子跑得太慢。
顺便说一句上边代码中 os.execute(string)是执行string指令,wget是下载指令,参见linux 应用之wget 命令详解
下载下来的数据是 mat格式的,要转换成 torch使用的t7格式,文档中说可以使用mattorch工具实现,但是我在虚拟机上没有装matlab,所以安装mattorch总是失败。 另外使用matio同样可以实现matlab和torch间数据转换。
下面是安装matio的指令matio-ffi
- sudo apt-get install libmatio2
- sudo luarocks install matio
此时下载的数据是 columns x rows x channels x num ,但image.display()要求的数据组织形式是: num x channels x columns x rows,所以需要进行重组织,由于我也是个刚开始使用torch没一周的人,所以就用较原始的办法重组织了,谁有好办法希望教教我!下面是数据转换的代码
- matio = require'matio'
- loaded = matio.load('/SVHN_Data/train_32x32.mat')
- tempData=loaded.X:permute(4,3,1,2)
- trainData = {
- data = tempData,
- labels = loaded.y[{{},{1}}], -- loaded.y:size() --> 26032 x 1
- size = function() return trsize end
- }
数据存放在'/SVHN_Data'文件夹内
------------------------------------------------------下面一段是用来看数据转换的对不对 --------------------------------
torch 结果

matlab结果
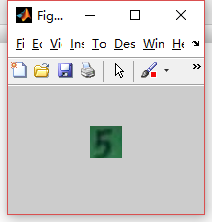
颜色不大一样,一个是在笔记本上跑的,一个是在台机上跑的,不知道是不是机器的原因还是什么原因
---------------------------------------------------------------------END---------------------------------------------------------
- if opt.size == 'extra' then
- print '==> using extra training data'
- trsize = 73257 + 531131
- tesize = 26032
- elseif opt.size == 'full' then
- print '==> using regular, full training data'
- trsize = 73257
- tesize = 26032
- elseif opt.size == 'small' then
- print '==> using reduced training data, for fast experiments'
- trsize = 10000
- tesize = 2000
- end
上面这一段是设置训练集和测试集的大小。
================================================================= START ==================================================
- loaded = torch.load(train_file,'ascii')
- trainData = {
- data = loaded.X:transpose(3,4),
- labels = loaded.y[1],
- size = function() return trsize end
- }
上面这段代码很容易理解,就是分别将数据和标签起别名data和labels方便后续使用,size返回的是训练样本的个数。唯一需要注意的是transpose()函数的使用,这是因为在matlab中数据的表达一般是先列后行,而在torch中数据的表达一般是先行后列,所以这里对后两维进行了转置
这段代码被上面自己下载数据并处理取代
====================================================== END ======================================================
- if opt.size == 'extra' then
- loaded = torch.load(extra_file,'ascii')
- trdata = torch.Tensor(trsize,3,32,32)
- trdata[{ {1,(#trainData.data)[1]} }] = trainData.data
- trdata[{ {(#trainData.data)[1]+1,-1} }] = loaded.X:transpose(3,4)
- trlabels = torch.Tensor(trsize)
- trlabels[{ {1,(#trainData.labels)[1]} }] = trainData.labels
- trlabels[{ {(#trainData.labels)[1]+1,-1} }] = loaded.y[1]
- trainData = {
- data = trdata,
- labels = trlabels,
- size = function() return trsize end
- }
- end
当数据选择extra时,上面对训练集进行拼接。
同样加载测试集
- loaded = matio.load('/SVHN_Data/test_32x32.mat')
- tempData = loaded.X:permute(4,3,1,2)
- testData = {data = tempData, labels =loaded.y, size = function() return tesize end}
- tempData = nil
下面进行数据的预处理
数据的预处理包含三个trick
+ 图像从RGB空间映射到YUV空间
+ Y通道使用 contrastive normalization operator进行局部规范化
+ 对所有的数据在每个通道进行规范化到0,1之间
- -- RGB==>YUV
- for i=1,trainData:size() do
- trainData.data[i] = image.rgb2yuv(trainData.data[i]) -- 等价于 trainData.data[{{i},{},{},{}}]
- end
- for i=1,testData:size() do
- testData.data[i] = image.rgb2yuv(testData.data[i])
- end
- -- Name Channels for convenience
- channels = {'y','u','v'}
- -- 单通道进行规范化
- Mean={}
- Std={}
- for i=1, channel in ipairs(channels) do --此处和for i=1,3 do等价
- Mean[i]= trainData.data[{{},{i},{},{}}]:mean()
- Std[i] = trainData.data[{{},{i},{},{}}]:std()
- trainData.data[{{},{i},{},{}}]=trainData.data[{{},{i},{},{}}]:csub(Mean[i])
- trainData.data[{{},{i},{},{}}]=trainData.data[{{},{i},{},{}}]:div(Std[i])
- end
- for i=1,3 do
- testData.data[{{},{i},{},{}}]:add(-Mean[i]) -- add 和csub
- -- 这个用法见Tensor的手册,改变后替代原来数据,所以和上面是一样的
- testData.data[{{},{i},{},{}}]:div(Std[i])
- end
- -- 至于为什么测试数据使用训练集的统计量归一化,参见机器学习相关理论
Y通道局部的规范化需要使用nn包里的算子
- -- Define the normalization neighborhood:
- neighborhood = image.gaussian1D(7)
- -- Define our local normalization operator (It is an actual nn module,
- -- which could be inserted into a trainable model):
- normalization = nn.SpatialContrastiveNormalization(1, neighborhood):float()
- -- Normalize all Y channels locally:
- for i = 1,trainData:size() do
- trainData.data[{ i,{1},{},{} }] = normalization:forward(trainData.data[{ i,{1},{},{} }]) --前向计算
- end
- for i = 1,testData:size() do
- testData.data[{ i,{1},{},{} }] = normalization:forward(testData.data[{ i,{1},{},{} }])
- end
关于函数 nn.SpatialContrastiveNormalization(1, neighborhood) 参见 torch/nn/SpatialContrastiveNormalization.lua
===================== It's always good practice to verify that data is properly normalized ========================
- for i,channel in ipairs(channels) do
- trainMean = trainData.data[{ {},i }]:mean()
- trainStd = trainData.data[{ {},i }]:std()
- testMean = testData.data[{ {},i }]:mean()
- testStd = testData.data[{ {},i }]:std()
- print('training data, '..channel..'-channel, mean: ' .. trainMean)
- print('training data, '..channel..'-channel, standard deviation: ' .. trainStd)
- print('test data, '..channel..'-channel, mean: ' .. testMean)
- print('test data, '..channel..'-channel, standard deviation: ' .. testStd)
- end
================================================= END ======================================
最后是数据的可视化,显示了前256个数据Y,U,V通道上的效果
- if opt.visualize then
- first256Samples_y = trainData.data[{ {1,256},1 }]
- first256Samples_u = trainData.data[{ {1,256},2 }]
- first256Samples_v = trainData.data[{ {1,256},3 }]
- image.display{image=first256Samples_y, nrow=16, legend='Some training examples: Y channel'}
- image.display{image=first256Samples_u, nrow=16, legend='Some training examples: U channel'}
- image.display{image=first256Samples_v, nrow=16, legend='Some training examples: V channel'}
- end
具体的代码见附件
命令行执行: (1_data.lua)是文件名
- qlua 1_data.lua
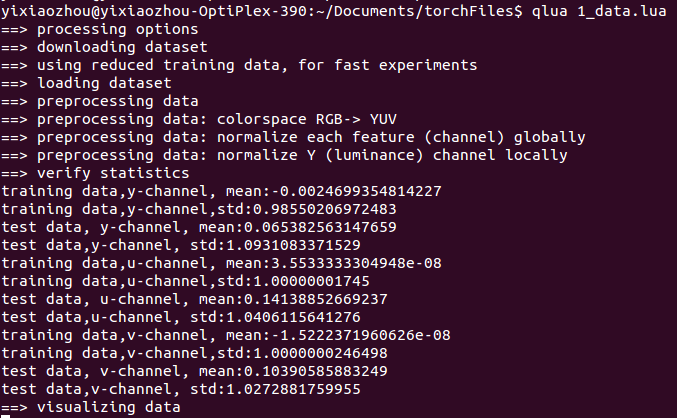
结果见下图(Y通道)
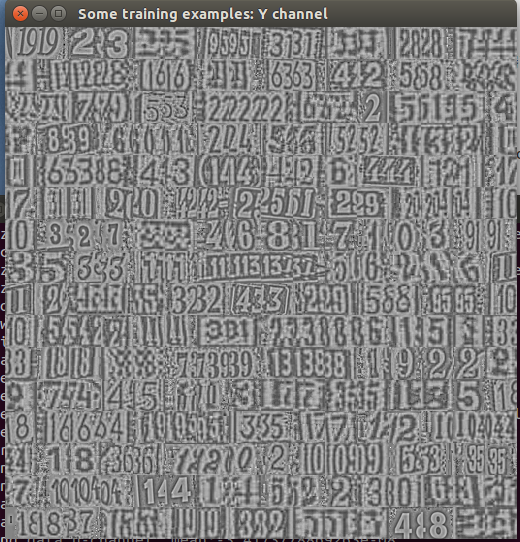
github上给的结果(Y通道)
================================================== 结论 ===================================
torch 挺好用的,和我胃口-
在笔记本上安装虚拟机跑深度学习的代码。。。真是蛮拼的。。。这速度感人啊,直接在ubuntu系统上跑还是蛮快的
===========================================================================================
=
torch7框架 深度学习(1)的更多相关文章
- 通过 DLPack 构建跨框架深度学习编译器
通过 DLPack 构建跨框架深度学习编译器 深度学习框架,如Tensorflow, PyTorch, and ApacheMxNet,快速原型化和部署深度学习模型提供了强大的工具箱.不幸的是,易用性 ...
- 学习笔记︱Nvidia DIGITS网页版深度学习框架——深度学习版SPSS
DIGITS: Deep Learning GPU Training System1,是由英伟达(NVIDIA)公司开发的第一个交互式深度学习GPU训练系统.目的在于整合现有的Deep Learnin ...
- ASP.NET Core框架深度学习(一) Hello World
对于学习Core的框架,对我帮助最大的一篇文章是Artech的<200行代码,7个对象——让你了解ASP.NET Core框架的本质>,最近我又重新阅读了一遍该文.本系列文章就是结合我的阅 ...
- ASP.NET Core框架深度学习(四)宿主对象
11.WebHost 第六个对象 到目前为止我们已经知道了由一个服务器和多个中间件构成的管道是如何完整针对请求的监听.接收.处理和最终响应的,接下来来讨论这样的管道是如何被构建出来的.管道是在作为应 ...
- ASP.NET Core框架深度学习(二) 管道对象
4.HttpContext 第一个对象 我们的ASP.NET Core Mini由7个核心对象构建而成.第一个就是大家非常熟悉的HttpContext对象,它可以说是ASP.NET Core应用开发中 ...
- ASP.NET Core框架深度学习(三) Server对象
8.Server 第五个对象 服务器在管道中的职责非常明确,当我们启动应用宿主的WebHost的时候,服务它被自动启动.启动后的服务器会绑定到指定的端口进行请求监听,一旦有请求抵达,服务器会根据该 ...
- 深度学习调用TensorFlow、PyTorch等框架
深度学习调用TensorFlow.PyTorch等框架 一.开发目标目标 提供统一接口的库,它可以从C++和Python中的多个框架中运行深度学习模型.欧米诺使研究人员能够在自己选择的框架内轻松建立模 ...
- [源码解析] 深度学习分布式训练框架 horovod (7) --- DistributedOptimizer
[源码解析] 深度学习分布式训练框架 horovod (7) --- DistributedOptimizer 目录 [源码解析] 深度学习分布式训练框架 horovod (7) --- Distri ...
- GitHub 上 57 款最流行的开源深度学习项目
转载:https://www.oschina.net/news/79500/57-most-popular-deep-learning-project-at-github GitHub 上 57 款最 ...
随机推荐
- 把当前文件夹的xlsx或xls文件合并到一个excel文件中的不同sheet中
把当前文件夹的xlsx或xls文件合并到一个excel文件中的不同sheet中步骤如下: 把需要合并的文件放到同一个文件夹 在该文件夹中新建一个excel文件 打开新建的excel问价,把鼠标放到sh ...
- Part01、sqlalchemy 使用
一.ORM 连表 一对多 1.创建表,主动指定外键约束. 2.操作. ...
- centos7 vim显示行号
CentOS7下可能有n个账户,让vim显示行号有两种方法:仅让当前用户显示行号和让所有用户显示行号 一.仅让当前用户显示行号 输入命令:vim ~/.vimrc 写入:set nu 保存:wq ...
- 3.MySQL必知必会之检索数据-SELECT语句
本章将介绍如何使用SELECT语句从表中检索一个或多个数据列. 1.SELECT语句 SQL语句是由简单的英语单词构成的.这些单词称为关键字,每个SQL语句都是由一个或多个关键字构成的.大概,最经常使 ...
- Java设计原则—依赖倒置原则(转)
依赖倒置原则(Dependence Inversion Principle,DIP)的原始定义: 高层模块不应该依赖底层模块,两者都应该依赖其抽象: 抽象不应该依赖细节: 细节应该依赖抽象. 依赖倒置 ...
- 【AngularJS】通过jsonp与webmethod交互,实现ajax验证
服务端配置 1:新建一个asp.net的网站 2: 创建一个服务文件:LoginService.asmx 注意:记得取消[System.Web.Script.Services.ScriptServic ...
- peeping tom 在渗透信息收集前的作用。
原本想写个截屏类的脚本,发现已经有了这个 py脚本 名字叫作: peeping tom 想要了解详细,戳:https://bitbucket.org/LaNMaSteR53/peepingtom/ ...
- 谈面向对象的编程(Python)
(注:本文部分内容摘自互联网,由于作者水平有限,不足之处,还望留言指正.) 今天中秋节,也没什么特别的,寻常日子依旧. 谈谈面向对象吧,什么叫面向对象? 那么问题来了,你有对象吗? 嗯,,,那我可 ...
- [转]tomcat之一:指定tomcat运行时JDK版本
今天在做项目的时候,主管让我在本机上启动多个tomcat且指定不同的jdk环境.因为在企业的项目中个,对于同一个服务器中有多个jdk和tomcat,所以就需要手动指定不同的jdk. 在网上找了很多资料 ...
- 应用libjpeg提取jpeg质量因子
http://blog.csdn.net/lzhq28/article/details/7775222 版权声明:本文为博主原创文章,未经博主允许不得转载. data = new BYTE [cinf ...