Machine Learning系列--维特比算法
维特比算法(Viterbi algorithm)是在一个用途非常广的算法,本科学通信的时候已经听过这个算法,最近在看 HMM(Hidden Markov model) 的时候也看到了这个算法。于是决定研究一下这个算法的原理及其具体实现,如果了解动态规划的同学应该很容易了解维特比算法,因为维特比算法的核心就是动态规划。
对于 HMM 而言,其中一个重要的任务就是要找出最有可能产生其观测序列的隐含序列。一般来说,HMM问题可由下面五个元素描述:
- 观测序列(observations):实际观测到的现象序列
- 隐含状态(states):所有的可能的隐含状态
- 初始概率(start_probability):每个隐含状态的初始概率
- 转移概率(transition_probability):从一个隐含状态转移到另一个隐含状态的概率
- 发射概率(emission_probability):某种隐含状态产生某种观测现象的概率
下面以维基百科上的具体例子来说明:
想象一个乡村诊所。村民有着非常理想化的特性,要么健康要么发烧。他们只有问诊所的医生的才能知道是否发烧。 聪明的医生通过询问病人的感觉诊断他们是否发烧。村民只回答他们感觉正常、头晕或冷。
假设一个病人每天来到诊所并告诉医生他的感觉。医生相信病人的健康状况如同一个离散马尔可夫链。病人的状态有两种“健康”和“发烧”,但医生不能直接观察到,这意味着状态对他是“隐含”的。每天病人会告诉医生自己有以下几种由他的健康状态决定的感觉的一种:正常、冷或头晕。这些是观察结果。 整个系统为一个隐马尔可夫模型(HMM)。
医生知道村民的总体健康状况,还知道发烧和没发烧的病人通常会抱怨什么症状。 换句话说,医生知道隐马尔可夫模型的参数。则这些上面提到的五个元素表示如下:
states = ('Healthy', 'Fever')
observations = ('normal', 'cold', 'dizzy')
start_probability = {'Healthy': 0.6, 'Fever': 0.4}
transition_probability = {
'Healthy' : {'Healthy': 0.7, 'Fever': 0.3},
'Fever' : {'Healthy': 0.4, 'Fever': 0.6},
}
emission_probability = {
'Healthy' : {'normal': 0.5, 'cold': 0.4, 'dizzy': 0.1},
'Fever' : {'normal': 0.1, 'cold': 0.3, 'dizzy': 0.6},
}
其对应的状态转移图如下所示:

现在的问题是假设病人连续三天看医生,医生发现第一天他感觉正常,第二天感觉冷,第三天感觉头晕。 于是医生产生了一个问题:怎样的健康状态序列最能够解释这些观察结果。维特比算法解答了这个问题。
首先直观地看这个问题,在HMM中,一个观测现象后面的对应的各个状态都有一个概率值,我们只需要选择概率值最大的那个状态即可,但是这个概率值是跟前面一个状态有关的(马尔科夫假设),因此不能独立考虑每个观测现象。
为了从时间复杂度方面进行比较,现在将问题一般化:假设观测序列的长度为 m,隐含状态个数为 n。则有下面的隐含状态转移图(下图为了便于表示,将只画出n = 3 的图)。

假如采用穷举法,穷举出所有可能的状态序列再比较他们的概率值,则时间复杂度是$O(n^m)$, 显然这样的时间复杂度是无法接受的,而通过维特比算法能把时间复杂度降到$O(m*n^2)$。
从动态规划的问题去考虑这个问题,根据上图的定义,记last_state为上一个观测现象对应的各个隐含状态的概率,curr_state为现在的观测现象对应的各个隐含状态的概率。则求解curr_state实际上只依赖于last_state。而他们的依赖关系可通过下面的python代码表示出来:
for cs in states:
curr_state[cs] = max(last_state[ls] *
transition_probability[ls][cs] *
emission_probability[cs][observation]
for ls in states)
计算过程利用了转移概率transition_probability和发射概率emission_probability,选出那个最有可能产生当前状态cs的上一状态ls。
除了上面的计算,同时要为每个隐含状态维护一个路径path,path[s]表示到达状态s前的最优状态序列。通过前面的计算选出那个最有可能产生当前状态cs的上一状态ls后,往path[cs]中插入ls。则依照这种方法遍历完所有的观测序列后,只需要选择curr_state中概率值最大的那个state作为最终的隐含状态,同时从path中取出path[state]作为该最终隐含状态前面的状态序列。
从上面的分析可知,观测序列只需要遍历一遍,时间复杂度为$O(m)$,而每次要计算当前各个状态最可能的前一状态,时间复杂度为$O(n^2)$,因此总体的时间复杂度为$O(m*n^2)$.
假如在NLP中应用HMM,则将词序列看做是观测到的现象,而词性、标签等信息看做是隐含状态,那么就可以通过维特比算法求解其隐含状态序列,而这也是HMM在分词,词性标注,命名实体识别中的应用。其关键往往是找出上面提到的初始概率(start_probability)、转移概率(transition_probability)、发射概率(emission_probability)。
而在通信领域中,假如将收到的编码信息看作是观测序列,对应的解码信息为隐含状态,那么通过维特比算法也能够找出概率最大的解码信息。
需要注意的是维特比算法适用于多步骤多选择的最优问题,类似于下面的网络,《数学之美》中将其叫做“篱笆网络(Lattice)”。每一步都有多个选择,并且保留了前面一步各个选择的最优解,通过回溯的方法找到最优选择路径。
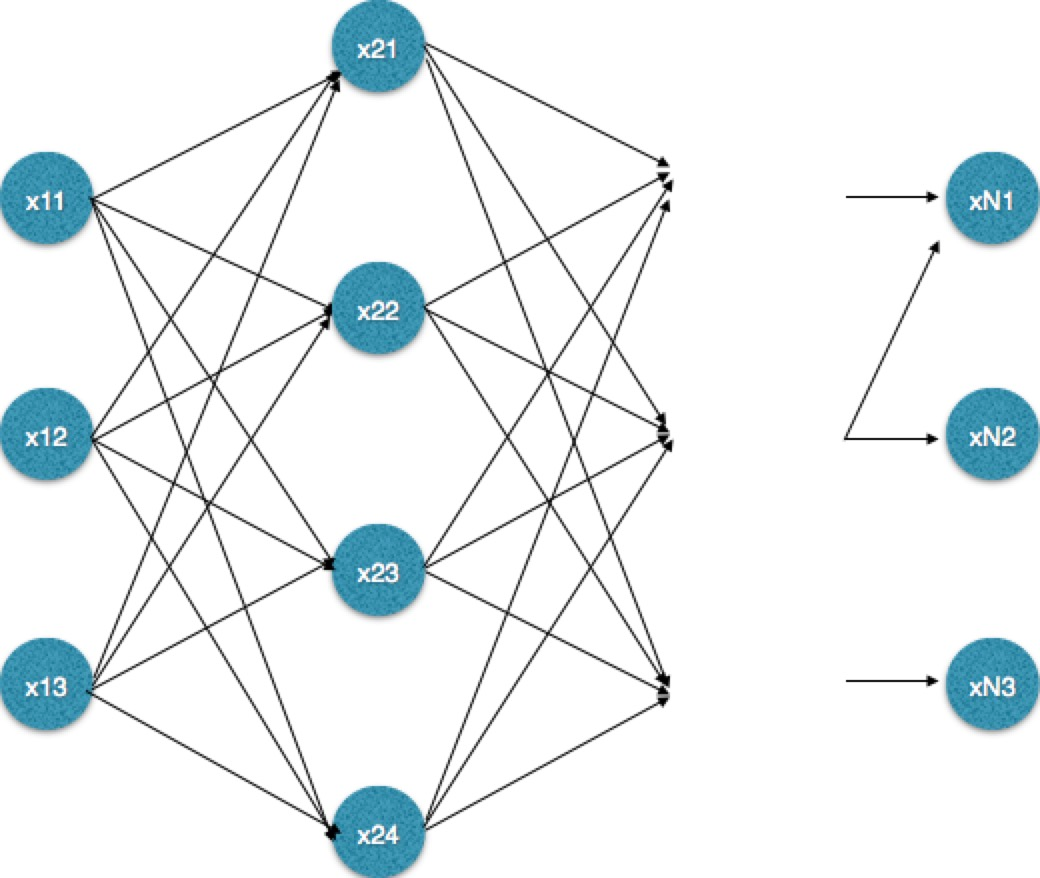
这里要强调的是viterbi算法可以用于解决HMM问题,但是也可以用于解决其他符合上面描述的问题。
转自博文:http://wulc.me/2017/03/02/维特比算法/
Machine Learning系列--维特比算法的更多相关文章
- Machine Learning读书会,面试&算法讲座,算法公开课,创业活动,算法班集锦
Machine Learning读书会,面试&算法讲座,算法公开课,创业活动,算法班集锦 近期活动: 2014年9月3日,第8次西安面试&算法讲座视频 + PPT 的下载地址:http ...
- Machine Learning系列--CRF条件随机场总结
根据<统计学习方法>一书中的描述,条件随机场(conditional random field, CRF)是给定一组输入随机变量条件下另一组输出随机变量的条件概率分布模型,其特点是假设输出 ...
- [Machine Learning] 浅谈LR算法的Cost Function
了解LR的同学们都知道,LR采用了最小化交叉熵或者最大化似然估计函数来作为Cost Function,那有个很有意思的问题来了,为什么我们不用更加简单熟悉的最小化平方误差函数(MSE)呢? 我个人理解 ...
- Machine Learning系列--隐马尔可夫模型的三大问题及求解方法
本文主要介绍隐马尔可夫模型以及该模型中的三大问题的解决方法. 隐马尔可夫模型的是处理序列问题的统计学模型,描述的过程为:由隐马尔科夫链随机生成不可观测的状态随机序列,然后各个状态分别生成一个观测,从而 ...
- Machine Learning系列--EM算法理解与推导
EM算法,全称Expectation Maximization Algorithm,译作最大期望化算法或期望最大算法,是机器学习十大算法之一,吴军博士在<数学之美>书中称其为“上帝视角”算 ...
- Machine Learning系列--L0、L1、L2范数
今天我们聊聊机器学习中出现的非常频繁的问题:过拟合与规则化.我们先简单的来理解下常用的L0.L1.L2和核范数规则化.最后聊下规则化项参数的选择问题.这里因为篇幅比较庞大,为了不吓到大家,我将这个五个 ...
- Machine Learning in Action-chapter2-k近邻算法
一.numpy()函数 1.shape[]读取矩阵的长度 例: import numpy as np x = np.array([[1,2],[2,3],[3,4]]) print x.shape / ...
- Machine Learning系列--TF-IDF模型的概率解释
信息检索概述 信息检索是当前应用十分广泛的一种技术,论文检索.搜索引擎都属于信息检索的范畴.通常,人们把信息检索问题抽象为:在文档集合D上,对于由关键词w[1] ... w[k]组成的查询串q,返回一 ...
- Machine Learning系列--归一化方法总结
一.数据的标准化(normalization)和归一化 数据的标准化(normalization)是将数据按比例缩放,使之落入一个小的特定区间.在某些比较和评价的指标处理中经常会用到,去除数据的单位限 ...
随机推荐
- 秒杀多线程第二篇 多线程第一次亲密接触 CreateThread与_beginthreadex本质区别(续)
由于原作者主要写window上的线程,而我主要学习android,所以本文将分析android方面多线程. 1.Thread: public void Thread1(){ Thread a = ne ...
- 题解 P1478 【陶陶摘苹果(升级版)】
看着你们累死累活得快排.冒泡.结构体特殊冒泡.还有dp... 蒟蒻表示真的不用那么麻烦! 难度:新手村+1 压行情况:0 理解难度:0 首先我们来了解一下优先队列:(自己抄的自己...) 讲元素一个个 ...
- C++解析(30):关于指针判别、构造异常和模板二义性的疑问
0.目录 1.指针的判别 2.构造中的异常 2.1 如果构造函数中抛出异常会发生什么? 2.2 如果析构函数中抛出异常会发生什么? 3.令人迷惑的写法 3.1 模板中的二义性 3.2 函数异常声明 4 ...
- Bond UVA - 11354(并查集按秩合并)
题意: 给你一张无向图,然后有若干组询问,让你输出a->b的最小瓶颈路. 解析: 应该都想过用prime的次小生成树做..但二维数组开不了那么大..所以只能用kruskal了.... #incl ...
- QString::QString 中文乱码
QString::QString 中文乱码 处理方法: 1. QString str = QString::fromLocal8Bit("中文"); // vs2008 vs200 ...
- [CF1103B]Game with modulo
题目大意:交互题,有一个数$a(a\leqslant10^9)$,需要猜出它的值,一次询问为你两个数字$x,y(x,y\in[0,2\times10^9])$: 若$x\bmod a\geqslant ...
- MSSQL代理工作服务器远程命令执行
概述 如果MSSQL数据库中开启了MSSQL Server Agent Job服务的话,攻击者将可以利用MSSQL Server中自带的功能来获取一个shell. SQL Server Agent S ...
- 高性能相关、Scrapy框架
高性能相关 在编写爬虫时,性能的消耗主要在IO请求中,当单进程单线程模式下请求URL时必然会引起等待,从而使得请求整体变慢. import requests def fetch_async(url): ...
- mysql三-6:完整性约束
一 介绍 约束条件与数据类型的宽度一样,都是可选参数 作用:用于保证数据的完整性和一致性 主要分为: PRIMARY KEY (PK) 标识该字段为该表的主键,可以唯一的标识记录 FOREIGN KE ...
- 前端PHP入门-006-表达式和运算符
算术运算 概念 算数运算符,就是大家小学所学绝大多数知识: 符号 描述 示例 + 加号 x+" role="presentation" style="posit ...