Ansible 小手册系列 十(包含和角色)
一、包含 (include)
使用include模块来包含foo文件
tasks:
- include: foo.yml --- foo.yml
- name: test foo
command: echo foo
include 还允许传递变量
- include: wordpress.yml wp_user=timmy
- include: wordpress.yml
vars:
wp_user: timmy
ssh_keys:
- keys/one.txt
- keys/two.txt
动态包含
循环引用3次
- include: foo.yml param={{item}}
with_items:
- 1
- 2
- 3
还可以使用动态变量引入task文件
- include: "{{inventory_hostname}}.yml"
动态包含的一些限制
• 您不能使用notify触发来自动态包含的处理程序名称。
• 您不能使用--start-at-task在动态包含内的任务开始执行。
• 仅存在于动态包含内的标记不会显示在-list-tags输出中。
• 只存在于动态包含内的任务将不会显示在-list-tasks输出中。
为了解决上面限制,2.1版本后引入了static
- include: foo.yml
static: <yes|no|true|false>
默认情况下,在Ansible 2.1及更高版本中,include包含符合以下条件时会自动被视为静态而不是动态:
- include不使用任何循环
- 包含的文件名不使用任何变量
- 静态选项没有显式禁用(即static:no)
- 强制静态包含(见下文)的ansible.cfg选项被禁用
ansible.cfg配置中有两个选项可用于静态包括:
task_includes_static- 将所有在tasks部分中包含的内容都设置为静态。handler_includes_static- 强制所有包括在处理程序部分是静态的。
这些选项允许用户强制playbook的行为与他们在1.9.x和之前一样。
变量包含
include_vars 在task中动态加载yaml或json文件类型中的变量
- include_vars: myvars.yml
根据操作系统类型加载变量文件,如果找不到,则为默认值。
- include_vars: "{{ item }}"
with_first_found:
- "{{ ansible_distribution }}.yml"
- "{{ ansible_os_family }}.yml"
- "default.yml"
角色 ROLE
角色是基于已知文件结构自动加载某些vars_files,任务和处理程序的方法。 按角色分组内容还允许轻松与其他用户共享角色。
文件结构如下
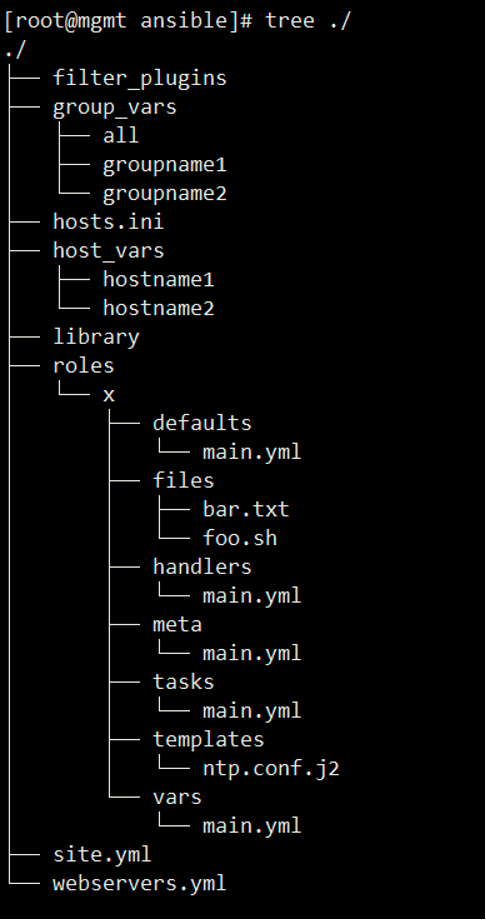
结构说明
- site.yml 主要的playbook
- webservers.yml webservers 得playbook
- hosts.ini 主机清单
- ibrary 如果有任何自定义模块,将其放在这里(可选)
- filter_plugins 如果有任何自定义过滤器插件,将其放在这里(可选)
- 如果group_var/all存在,其中列出的变量将被添加到所有的主机组中
- 如果group_var/groupname1存在,其中列出的变量将被添加到groupname1主机组中-
- 如果host_vars/hostname1存在,其中列出的变量将被添加到hostname1主机组中
这个 playbook 为一个角色 ‘x’ 指定了如下的行为
- 如果 roles/x/tasks/main.yml 存在, 其中列出的 tasks 将被添加到 play 中
- 如果 roles/x/handlers/main.yml 存在, 其中列出的 handlers 将被添加到 play 中
- 如果 roles/x/vars/main.yml 存在, 其中列出的 variables 将被添加到 play 中
- 如果 roles/ x/defaults /main.yml存在,其中列出的变量将被添加到play 中
- 如果 roles/x/meta/main.yml 存在, 其中列出的 “角色依赖” 将被添加到 roles 列表中
- 所有 copy tasks 可以引用 roles/x/files/ 中的文件,不需要指明文件的路径。
- 所有 script tasks 可以引用 roles/x/files/ 中的脚本,不需要指明文件的路径。
- 所有 template tasks 可以引用 roles/x/templates/ 中的文件,不需要指明文件的路径。
- 所有 include tasks 可以引用 roles/x/tasks/ 中的文件,不需要指明文件的路径。
如果 roles 目录下有文件不存在,这些文件将被忽略。
这些目录的加载顺序
- meta/main.yml
- tasks/main.yml
- handlers/main.yml
- vars/main.yml
- defaults/main.yml
如果区分环境使用角色,可以使用下列文档结构

- production/inventory 主机清单
** 运行playbook**
ansible-playbook -i production site.yml
角色定义
在playbook中定义角色
---
- hosts: webservers
roles:
- x
定义角色参数
---
- hosts: webservers
roles:
- { role: x, dir: '/opt/a', app_port: 5000 }
使用条件判断,当主机是Redhat时,才执行角色任务
---
- hosts: webservers
roles:
- { role: some_role, when: "ansible_os_family == 'RedHat'" }
定义角色标签
---
- hosts: webservers
roles:
- { role: x, tags: ["bar", "baz"] }
定义执行角色任务前后执行的动作
--- - hosts: webservers
pre_tasks:
- shell: echo 'hello'
roles:
- { role: some_role }
tasks:
- shell: echo 'still busy'
post_tasks:
- shell: echo 'goodbye'
pre_tasks里的task在roles执行前执行的任务
post_tasks里的task在roles执行完成后执行的任务
角色默认变量
定义角色默认变量,只需在角色目录中添加一个defaults/main.yml文件。角色默认变量优先级最低。
角色依赖
角色依赖性允许您在使用角色时自动提取其他角色。 角色依赖关系存储在角色目录中包含的meta/main.yml文件中。 此文件应包含要在指定角色之前插入的角色和参数的列表,例如角色/myapp/meta/main.yml中的以下内容:
角色依赖性允许您在使用角色时自动提取其他角色。 角色依赖关系存储在角色目录中包含的meta/main.yml文件中。 此文件应包含要在指定角色之前插入的角色和参数的列表,例如角色/myapp/meta/main.yml中的以下内容:
---
dependencies:
- { role: common, some_parameter: 3 }
- { role: apache, apache_port: 80 }
- { role: postgres, dbname: blarg, other_parameter: 12 }
- { role: '/path/to/common/roles/foo', x: 1 }
这里表示myapp这个role依赖于meta里面的role,也就是说如果执行myapp的role之前先执行myapp中meta的role** 角色依赖执行顺序**
角色依赖性始终在包含角色的角色之前执行,并且是递归的。
如上面内容,按照common,apache,postgres,'/path/to/common/roles/foo顺序依次执行,再执行此角色
** 角色依赖嵌套**
默认情况下,在添加依赖其他角色的时候,如果其他角色内也有依赖关系,是不执行其他角色内的依赖关系的。
可以通过allow_duplicates: yes设置来实现执行其他角色内的依赖关系。
实际测试,2.1,2.2版本的ansible,无论加不加这个设置,就只会执行第一次依赖角色,后续的则不执行。

Ansible 小手册系列 十(包含和角色)的更多相关文章
- Ansible 小手册系列 十四(条件判断和循环)
条件判断 When 语句 在when 后面使用Jinja2 表达式,结果为True则执行任务. tasks: - name: "shut down Debian flavored syste ...
- Ansible 小手册系列 十九(常见指令表)
Play 指令 说明 accelerate 开启加速模式 accelerate_ipv6 是否开启ipv6 accelerate_port 加速模式的端口 always_run any_error ...
- Ansible 小手册系列 十八(Lookup 插件)
file:获取文件内容 --- - hosts: all vars: contents: "{{ lookup('file', '/etc/foo.txt') }}" tasks: ...
- Ansible 小手册系列 十二(Facts)
Facts 是用来采集目标系统信息的,具体是用setup模块来采集得. 使用setup模块来获取目标系统信息 ansible hostname -m setup 仅显示与ansible相关的内存信息 ...
- Ansible 小手册系列 十六(Playbook Debug)
debug模块在执行期间打印语句,并且可用于调试变量或表达式,而不必停止playbook. 打印自定义的信息 - debug: msg="System {{ inventory_hostna ...
- Ansible 小手册系列 十五(Blocks 分组)
当我们想在满足一个条件下,执行多个任务时,就需要分组了.而不再每个任务都要用when. tasks: - block: - command: echo 1 - shell: echo 2 - raw: ...
- Ansible 小手册系列 九(Playbook)
playbook是由一个或多个"play"组成的列表.play的主要功能在于将事先归并为一组的主机装扮成事先通过ansible中的task定义好的角色.从根本上来讲所谓task无非 ...
- Ansible 小手册系列 二十(经常遇到的问题)
(1). 怎么为任务设置环境变量? - name: set environment shell: echo $PATH $SOME >> /tmp/a.txt environment: P ...
- Ansible 小手册系列 十一(变量)
变量名约束 变量名称应为字母,数字和下划线. 变量应始终以字母开头. 变量名不应与python属性和方法名冲突. 变量使用 通过命令行传递变量(extra vars) ansible-playbook ...
随机推荐
- for…else和while…else
当while语句配备else子句时,如果while子句内嵌的循环体在整个循环过程中没有执行break语句(循环体中没有break语句,或者循环体中有break语句但是始终未执行),那么循环过程结束后, ...
- android整理的一些基础知识
本篇文章内容大部分是来源于本人实际开发中的心得总结,不是非常全面,咱才疏学浅,如果有错误的地方恳请各位指出哦~ android四大组件 四大组件包括:Activity(活动),Service(服务), ...
- LinQ高级查询、组合查询、IQueryable集合类型
LinQ高级查询: 1.模糊查询(包含) Repeater1.DataSource = con.car.Where(r =>r.name.Contains(s)).ToList(); 2.开头 ...
- Linux ./configure --prefix 命令是什么意思?
源码的安装一般由3个步骤组成:配置(configure).编译(make).安装(makeinstall). Configure是一个可执行脚本,它有很多选项,在待安装的源码路径下使用命令./conf ...
- Python 实例3—三级菜单
老男孩培训学习: ''' Author:Ranxf ''' menu = { '北京': { '海淀': { '五道口': { 'soho': {}, '网易': {}, 'google': {} } ...
- Selenium+Python常见定位方法
参见官网:http://selenium-python.readthedocs.io/locating-elements.html 有多种策略来定位页面中的元素.你可以使用最适合你的情况.Seleni ...
- ThinkPHP 调用后台方法
<a href="__URL__/del/id/{$vo['id']}">删除</a>
- 【Thinking in Java, 4e】访问权限控制
[包:库单元] 编译单元的概念. 一个.java文件就是一个编译单元,一个编译单元只能有一个public类,编译单元中的非public类一般是用于为public类提供支持的,这些类在包外不可见. im ...
- Django学习笔记之uWSGI详解
WSGI是什么? WSGI,全称 Web Server Gateway Interface,或者 Python Web Server Gateway Interface ,是为 Python 语言定义 ...
- tab标签 插件 by 腾讯 jianminlu
/** * @version 0.1 * @author jianminlu * @update 2013-06-19 15:23 */ (function ($) { /** * @name tab ...