大数据量情况下高效比较两个list
比如,对两个list<object>进行去重,合并操作时,一般的写法为两个for循环删掉一个list中重复的,然后再合并。
如果数据量在千条级别,这个速度还是比较快的。但如果数据量超过20W+(比如大批量的导入数据并对数据进行处理)时,则这块代码执行时间会比较长,非常影响用户体验和程序功能。这时我们可以用差集(Except)来处理重复数据。
下面MSDN上的代码示例演示了如何使用 Except<TSource>(IEnumerable<TSource>, IEnumerable<TSource>) 方法来比较两个数字序列,并返回仅在第一个序列中出现的元素。
double[] numbers1 = { 2.0, 2.1, 2.2, 2.3, 2.4, 2.5 };
double[] numbers2 = { 2.2 };
IEnumerable<double> onlyInFirstSet = numbers1.Except(numbers2);
foreach (double number in onlyInFirstSet)
outputBlock.Text += number + "\n";
/*
This code produces the following output:
2
2.1
2.3
2.4
2.5
*/
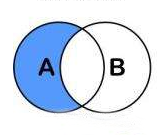
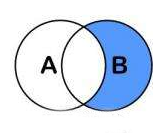
需要注意的是A.Except(B)与B.Except(A)结果是不一样的。
A.Except(B):
B.Except(A):
如果希望比较某种自定义数据类型对象的序列,则必须在您的类中实现 IEqualityComparer<T> 泛型接口。 下面的代码演示了如何在自定义数据类型中实现此接口并提供 GetHashCode 和 Equals 方法。
假设有需求是:在oldlist中过滤掉和list有相同ContractNo值的数据。
public class AssetPoolDataComparer : IEqualityComparer<AssetPoolData>
{
public bool Equals(AssetPoolData x, AssetPoolData y)
{
if (Object.ReferenceEquals(x, y)) return true;
//设置比较条件为两个ContractNo相同
return x != null && y != null && x.ContractNo.Equals(y.ContractNo);
} public int GetHashCode(AssetPoolData obj)
{
int hashContractNo = obj.ContractNo == null ? : obj.ContractNo.GetHashCode();
//主键ID
int hashProductID = obj.Id.GetHashCode(); return hashContractNo ^ hashProductID;
}
} var exceptList = oldlist.Except(list, new AssetPoolDataComparer()).ToList();
修改完代码,测试前后代码块运行时间,效果还是非常可观的。
ByQJL
大数据量情况下高效比较两个list的更多相关文章
- 大数据量情况下求top N的问题
上周五的时候去参加了一个面试,被问到了这个问题.问题描述如下: 假如存在一个很大的文件,文件中的每一行是一个字符串.请问在内存有限的情况下(内存无法加载这个文件中的所有内容),如何计算出出现频率最高的 ...
- phpExcel导入大数据量情况下内存溢出解决方案
PHPExcel版本:1.7.6+ 在不进行特殊设置的情况下,phpExcel将读取的单元格信息保存在内存中,我们可以通过 PHPExcel_Settings::setCacheStorageMeth ...
- phpExcel大数据量情况下内存溢出解决
版本:1.7.6+ 在不进行特殊设置的情况下,phpExcel将读取的单元格信息保存在内存中,我们可以通过 PHPExcel_Settings::setCacheStorageMethod() 来设置 ...
- C#拼接SQL语句,SQL Server 2005+,多行多列大数据量情况下,使用ROW_NUMBER实现的高效分页排序
/// <summary>/// 单表(视图)获取分页SQL语句/// </summary>/// <param name="tableName"&g ...
- MYSQL的大数据量情况下的分页查询优化
最近做的项目需要实现一个分页查询功能,自己先看了别人写的方法: <!-- 查询 --> <select id="queryMonitorFolder" param ...
- 大数据量冲击下Windows网卡异常分析定位
背景 mqtt的服务端ActiveMQ在windows上,多台PC机客户端不停地向MQ发送消息. 现象 观察MQ自己的日志data/activemq.log里显示,TCP链接皆异常断开.此时尝试从服务 ...
- 大数据量场景下storm自定义分组与Hbase预分区完美结合大幅度节省内存空间
前言:在系统中向hbase中插入数据时,常常通过设置region的预分区来防止大数据量插入的热点问题,提高数据插入的效率,同时可以减少当数据猛增时由于Region split带来的资源消耗.大量的预分 ...
- 由“大数据量Excel入库高效方式”瞥见“并联系统”之优势
使用场景: 当你有一个Excel文件,需要把其中的数据高速录入到数据库中,文件中包含10万条以上数据. 设计方案: 我们将整个过程分成三个阶段,A(装载Excel文件). ...
- java 导出Excel 大数据量,自己经验总结!
出处: http://lyjilu.iteye.com/ 分析导出实现代码,XLSX支持: /** * 生成<span style="white-space: normal; back ...
随机推荐
- MySQL安装与使用过程中的相关问题
数据库远程连接拒绝访问解决办法: 1. 改表法.可能是你的帐号不允许从远程登陆,只能在localhost.这个时候只要在localhost的那台电脑,登入mysql后,更改 "mysql&q ...
- Docker安装weblogic
Docker容器安装weblogic详细教程 前提:已经安装后Docker,并且能正常使用 (1)获取镜像: docker pull ismaleiva90/weblogic12 docker pu ...
- day3(while、流程控制)
一.while 语法 white 条件: 执行代码... 小练习: #打印0-100的偶数 count = 0 while count <= 100: if count %2 == 0 : pr ...
- python内置函数-compile()
python的内置函数 compile()--编译. 这个函数有什么用呢? 一个最简单的例子, 就是我们的代码, 会被解释器读取,解释器读取后的其实是字符串, 然后通过compile编译后, 又转换成 ...
- Ansible自动化运维笔记2(Ansible的组件介绍)
1.Ansible Inventory (1)静态主机文件 默认的ansible invetory是/etc/hosts文件,可以通过ANSIBLE_HOSTS环境变量或者通过运行命令的时候加上-i ...
- chrome浏览器Timing内各字段解析
Queueing请求文件顺序的的排序 Stalled是浏览器得到要发出这个请求的指令到请求可以发出的等待时间,一般是代理协商.以及等待可复用的TCP连接释放的时间,不包括DNS查询.建立TCP连接 ...
- (2018干货系列一)最新Java学习路线整合
怎么学Java Java是一门面向对象编程语言,不仅吸收了C++语言的各种优点,还摒弃了C++里难以理解的多继承.指针等概念,因此Java语言具有功能强大和简单易用两个特征. 话不多说,直接上干货: ...
- mysql常用基础操作语法(七)--统计函数和分组查询【命令行模式】
注:文中所有的...代表多个. 1.使用count统计条数:select count(字段名...) from tablename; 2.使用avg计算字段的平均值:select avg(字段名) f ...
- R语言︱决策树族——随机森林算法
每每以为攀得众山小,可.每每又切实来到起点,大牛们,缓缓脚步来俺笔记葩分享一下吧,please~ --------------------------- 笔者寄语:有一篇<有监督学习选择深度学习 ...
- RAPIDIO高速串行协议
RapidIO是由Motorola和Mercury等公司率先倡导的一种高性能. 低引脚数. 基于数据包交换的互连体系结构,是为满足和未来高性能嵌入式系统需求而设计的一种开放式互连技术标准.RapidI ...