spark 机器学习基础 数据类型
spark的机器学习库,包含常见的学习算法和工具如分类、回归、聚类、协同过滤、降维等
使用算法时都需要指定相应的数据集,下面为大家介绍常用的spark ml 数据类型。
1.本地向量(Local Vector)
存储在单台机器上,索引采用0开始的整型表示,值采用Double类型的值表示。Spark MLlib中支持两种类型的矩阵,分别是密度向量(Dense Vector)和稀疏向量(Spasre Vector),密度向量会存储所有的值包括零值,而稀疏向量存储的是索引位置及值,不存储零值,在数据量比较大时,稀疏向量才能体现它的优势和价值
scala> import org.apache.spark.mllib.linalg.{Vector, Vectors}
注意:scala默认会导入scala.collection.immutable.Vector,所以必须显式导入org.apache.spark.mllib.linalg.Vector
1.1密度向量,零值也存储
scala> val dv: Vector = Vectors.dense(1.0, 0.0, 3.0)
1.2.1创建稀疏向量,指定元素的个数、索引及非零值,数组方式
基于索引(0,2)和值(1,3)创建稀疏向量
scala> val sv1: Vector = Vectors.sparse(3, Array(0, 2), Array(1.0, 3.0))
1.2.2 创建稀疏向量,指定元素的个数、索引及非零值,采用序列方式
scala> val sv2: Vector = Vectors.sparse(3, Seq((0, 1.0), (2, 3.0)))
2.带类标签的特征向量(Labeled point)
Labeled point是Spark MLlib中最重要的数据结构之一,它在无监督学习算法中使用十分广泛,它也是一种本地向量,只不过它提供了类的标签,对于二元分类,它的标签数据为0和1,而对于多类分类,它的标签数据为0,1,2,…。它同本地向量一样,同时具有Sparse和Dense两种实现方式
scala> import org.apache.spark.mllib.regression.LabeledPoint
2.1LabeledPoint第一个参数是类标签数据,第二参数是对应的特征数据
//密度
scala> val pos = LabeledPoint(1.0, Vectors.dense(1.0, 0.0, 3.0))
scala> println(pos.features)
scala> println(pos.label)
//稀疏
scala> val neg = LabeledPoint(0.0, Vectors.sparse(3, Array(0, 2), Array(1.0, 3.0)))
注意:第2个特征值为0,从编程的角度来说,这样做可以减少内存的使用,并提高做矩阵内积时的运算速度
3.本地矩阵(Local matrix)
本地向量是由从0开始的整数下标和Double类型的数值组成。它有稠密向量(dense vector)和稀疏向量(sparse vertor)两种。在列的主要顺序中,它的非零输入值存储在压缩的稀疏列(CSC)格式中
在一维数组[1.0、3.0、5.0、2.0、4.0、6.0]中,对应的矩阵大小(3、2):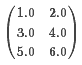
本地矩阵的基类是Matrix,提供了两种实现 DenseMatrix和SparseMatrix. 推荐使用工厂方法实现的Matrices来创建本地矩阵.
scala> import org.apache.spark.mllib.linalg.{Matrix, Matrices}
3.1 创建稠密矩阵
scala> val dm: Matrix = Matrices.dense(3, 2, Array(1.0, 3.0, 5.0, 2.0, 4.0, 6.0))
3.2 创建稀疏矩阵
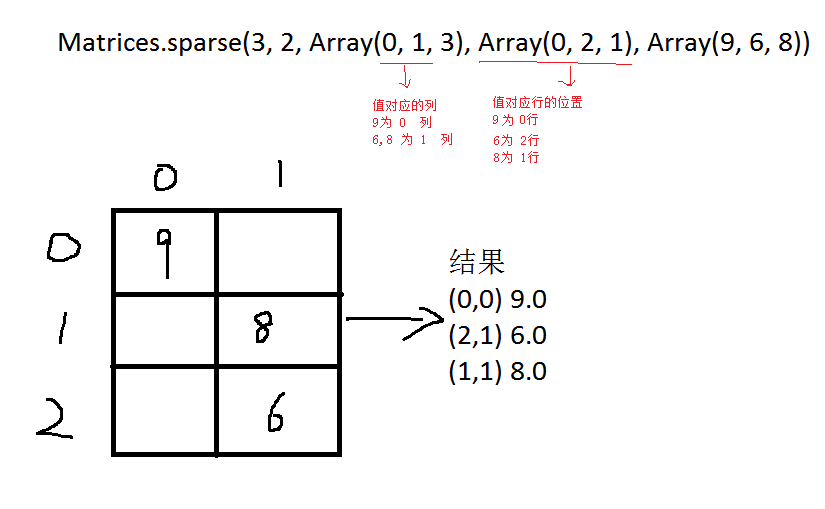
scala> val sm: Matrix = Matrices.sparse(3, 2, Array(0, 1, 3), Array(0, 2, 1), Array(9, 6, 8))
4.分布式矩阵(Distributed matrix)
分布式矩阵有Long类型的行列数据和Double类型值,存储在一个或多个RDDs中
4.1. 行矩阵(RowMatrix)
行矩阵是一个没有行索引的,以行为导向(row-oriented )的分布式矩阵,它的行只支持RDD格式,每一行都是一个本地向量。由于每一行都由一个局部向量表示,所以列的数量是由整数范围所限制的,但是在实际操作中应该要小得多
scala> import org.apache.spark.mllib.linalg.Vector
scala> import org.apache.spark.mllib.linalg.distributed.RowMatrix
scala> import org.apache.spark.mllib.linalg.{Vector, Vectors}
4.1.1 生成DataFrame
scala> val df1 = Seq(
(1.0, 2.0, 3.0),
(1.1, 2.1, 3.1),
(1.2, 2.2, 3.2)).toDF("c1", "c2", "c3")
scala> df1.show
c1 c2 c3
1.0 2.0 3.0
1.1 2.1 3.1
1.2 2.2 3.2
4.1.2 DataFrame转换成RDD[Vector]
scala> val rv1= df1.rdd.map {
x =>Vectors.dense(
x(0).toString().toDouble,
x(1).toString().toDouble,
x(2).toString().toDouble)
}
scala> rv1.collect()
4.1.3 创建行矩阵
scala> val mt1: RowMatrix = new RowMatrix(rv1)
scala> val m = mt1.numRows()
scala> val n = mt1.numCols()
查看:
scala> mt1.rows.collect()
或
scala>mt1.rows.map { x =>
(x(0).toDouble,
x(1).toDouble,
x(2).toDouble)
}.collect()
4.2 CoordinateMatrix坐标矩阵
CoordinateMatrix是一个分布式矩阵,每行数据格式为三元组(i: Long, j: Long, value: Double), i表示行索引,j表示列索引,value表示数值。只有当矩阵的两个维度都很大且矩阵非常稀疏时,才应该使用坐标矩阵。可以通过RDD[MatrixEntry]实例来创建一个CoordinateMatrix。MatrixEntry包装类型(Long, Long, Double)
scala> import org.apache.spark.mllib.linalg.distributed.CoordinateMatrix
scala> import org.apache.spark.mllib.linalg.distributed.MatrixEntry
4.2.1 生成df(行坐标,列坐标,值)
scala> val df = Seq(
(0, 0, 1.1), (0, 1, 1.2), (0, 2, 1.3),
(1, 0, 2.1), (1, 1, 2.2), (1, 2, 2.3),
(2, 0, 3.1), (2, 1, 3.2), (2, 2, 3.3)).toDF("row", "col", "value")
4.2.2 生成入口矩阵
scala> val m1 = df.rdd.map { x =>
val a = x(0).toString().toLong
val b = x(1).toString().toLong
val c = x(2).toString().toDouble
MatrixEntry(a, b, c)
}
scala> m1.collect()
4.2.3 生成坐标矩阵
scala> val m2 = new CoordinateMatrix(m1)
scala> m2.numRows()
scala> m2.numCols()
查看
scala> m2.entries.collect().take(10)
spark 机器学习基础 数据类型的更多相关文章
- Spark机器学习基础三
监督学习 0.线性回归(加L1.L2正则化) from __future__ import print_function from pyspark.ml.regression import Linea ...
- Spark机器学习基础二
无监督学习 0.K-means from __future__ import print_function from pyspark.ml.clustering import KMeans #from ...
- Spark机器学习基础一
特征工程 对连续值处理 0.binarizer/二值化 from __future__ import print_function from pyspark.sql import SparkSessi ...
- Spark机器学习基础-监督学习
监督学习 0.线性回归(加L1.L2正则化) from __future__ import print_function from pyspark.ml.regression import Linea ...
- Spark机器学习基础-无监督学习
0.K-means from __future__ import print_function from pyspark.ml.clustering import KMeans#硬聚类 #from p ...
- Spark机器学习基础-特征工程
对连续值处理 0.binarizer/二值化 from __future__ import print_function from pyspark.sql import SparkSession fr ...
- Spark机器学习MLlib系列1(for python)--数据类型,向量,分布式矩阵,API
Spark机器学习MLlib系列1(for python)--数据类型,向量,分布式矩阵,API 关键词:Local vector,Labeled point,Local matrix,Distrib ...
- Spark机器学习4·分类模型(spark-shell)
线性模型 逻辑回归--逻辑损失(logistic loss) 线性支持向量机(Support Vector Machine, SVM)--合页损失(hinge loss) 朴素贝叶斯(Naive Ba ...
- 掌握Spark机器学习库(课程目录)
第1章 初识机器学习 在本章中将带领大家概要了解什么是机器学习.机器学习在当前有哪些典型应用.机器学习的核心思想.常用的框架有哪些,该如何进行选型等相关问题. 1-1 导学 1-2 机器学习概述 1- ...
随机推荐
- safari浏览器模拟ipone,ipad以及其他浏览器版本
1.打开safari浏览器中的偏好设置 2.在偏好设置中,选择高级,勾选在菜单栏中显示开发菜单 3.打开开发,进入响应式设计模式 4.可以选择iphone 或ipad.浏览器等不同模式,进行模拟 5. ...
- Scrapy爬虫框架第八讲【项目实战篇:知乎用户信息抓取】--本文参考静觅博主所写
思路分析: (1)选定起始人(即选择关注数和粉丝数较多的人--大V) (2)获取该大V的个人信息 (3)获取关注列表用户信息 (4)获取粉丝列表用户信息 (5)重复(2)(3)(4)步实现全知乎用户爬 ...
- java正则使用方法
import java.util.regex.Matcher;import java.util.regex.Pattern; public class RegexMatches{ public ...
- django(权限、认证)系统——User模型
在Django的世界中,在权限管理中有内置的Authentication系统.用来管理帐户,组,和许可.还有基于cookie的用户session.这篇blog主要用来探讨这套内置的Authentica ...
- 第一天 Java语言概述
一.什么是软件 软件就是按照特定的顺序把数据和指令组合在一起,能够完成相应功能的程序. 软件分为两种: 系统软件:专门用户运行其他程序的平台.比如Linux.Windows.MAC等 应用软件:完成相 ...
- Spring_JDBC
//User实体类 package com.tao.pojo; public class User { private int id; private String name; private Str ...
- 【建图+最短路】Bzoj1001 狼抓兔子
Description 现在小朋友们最喜欢的"喜羊羊与灰太狼",话说灰太狼抓羊不到,但抓兔子还是比较在行的,而且现在的兔子还比较笨,它们只有两个窝,现在你做为狼王,面对下面这样一个 ...
- Android代码混淆的问题解决(java.io.FileNotFoundException)
Android Studio(2.3.3) 在给代码混淆时,提示: Warning:Exception while processing task java.io.FileNotFoundExcept ...
- 最新.net和Java调用SAP RFC中间件下载
还记得2012年初我发布的全网络第一个关于.net 连接SAP RFC的NCO3原创博文,用的就是SAP出的最新的.Net Connector 3.0的版本,在那个时候都是普遍用其他蹩脚的方式或Web ...
- 【Java进阶】并发编程
PS:整理自极客时间<Java并发编程> 1. 概述 三种性质 可见性:一个线程对共享变量的修改,另一个线程能立刻看到.缓存可导致可见性问题. 原子性:一个或多个CPU执行操作不被中断.线 ...