Amazon Redshift数据迁移到MaxCompute
Amazon Redshift数据迁移到MaxCompute
Amazon Redshift 中的数据迁移到MaxCompute中经常需要先卸载到S3中,再到阿里云对象存储OSS中,大数据计算服务MaxCompute然后再通过外部表的方式直接读取OSS中的数据。
如下示意图:

前提条件
本文以SQL Workbench/J工具来连接Reshift进行案例演示,其中用了Reshift官方的Query editor发现经常报一些奇怪的错误。建议使用SQL Workbench/J。
- 下载Amazon Redshift JDBC驱动程序,推荐4.2https://s3.amazonaws.com/redshift-downloads/drivers/jdbc/1.2.16.1027/RedshiftJDBC42-1.2.16.1027.jar
- 在SQL Workbench/J中新建Drivers,选择下载的驱动程序jar,并填写Classname为 com.amazon.redshift.jdbc42.Driver。

- 配置新连接,选择新建的Driver,并复制JDBC url地址、数据库用户名和密码并勾选Autocommit。

如果在配置过程中发现一只connection time out,需要在ecs的vpc安全组中配置安全策略。具体详见:https://docs.aws.amazon.com/zh_cn/redshift/latest/gsg/rs-gsg-authorize-cluster-access.html
Amazon Redshift数据预览
方式一:在AWS指定的query editor中进行数据预览,如下所示:

方式二:使用Workbench/J进行数据预览,如下图所示:
具体Workbench/J的下载和配置详见:https://docs.aws.amazon.com/zh_cn/redshift/latest/mgmt/connecting-using-workbench.html
(下图为JDBC驱动下载和JDBC URL查看页面)


卸载数据到Amazon S3
在卸载数据到S3之前一定要确保IAM权足够,否则如果您在运行 COPY、UNLOAD 或 CREATE LIBRARY 命令时收到错误消息 S3ServiceException: Access Denied,则您的集群对于 Amazon S3 没有适当的访问权限。如下:

创建 IAM 角色以允许 Amazon Redshift 集群访问 S3服务
- step1:进入https://console.aws.amazon.com/iam/home#/roles,创建role。

- step2:选择Redshift服务,并选择Redshift-Customizable

- step3:搜索策略S3,找到AmazonS3FullAccess,点击下一步。

- step4:命名角色为redshiftunload。


- step5:打开刚定义的role并复制角色ARN。(unload命令会用到)

- step6:进入Redshift集群,打开管理IAM角色

- step7:选择刚定义的redshiftunload角色并应用更改。

执行unload命令卸载数据
以管道分隔符导出数据
以默认管道符号(|)的方式将数据卸载到对应的S3存储桶中,并以venue_为前缀进行存储,如下:
unload ('select * from venue')
to 's3://aws2oss/venue_'
iam_role '<新建的redshiftunload角色对应的ARN>';
--parallel off; --连续卸载,UNLOAD 将一次写入一个文件,每个文件的大小最多为 6.2 GB

执行效果图如下:

进入Amazon S3对应的存储桶中可以查看到有两份文件,且以venue_为前缀的,可以打开文件查看下数据。

数据如下,以管道字符(|)分隔:

以指标符导出数据
要将相同的结果集卸载到制表符分隔的文件中,请发出下面的命令:
unload ('select * from venue')
to 's3://aws2oss/venue_'
iam_role '<新建的redshiftunload角色对应的ARN>'
delimiter as '\t';

打开文件可以预览到数据文件如下:

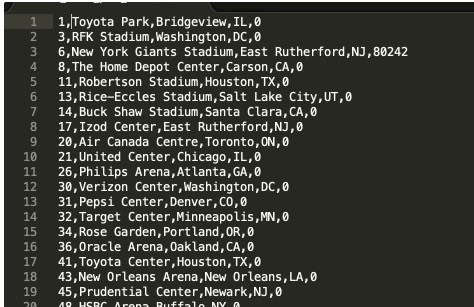
----为了MaxCompute更方便的读取数据,我们采用以逗号(,)分隔--```sql
unload ('select * from venue')
to 's3://aws2oss/venue_'
iam_role '<新建的redshiftunload角色对应的ARN>'
delimiter as ','
NULL AS '0';
更多关于unload的命令说明详见:[https://docs.aws.amazon.com/zh_cn/redshift/latest/dg/r_UNLOAD.html](https://docs.aws.amazon.com/zh_cn/redshift/latest/dg/r_UNLOAD.html)
<a name="dbfe35f7"></a>
# Amazon S3无缝切换到OSS
> 在线迁移工具只支持同一个国家的数据源,针对不同国家数据源迁移建议用户采用OSS迁移工具,自己部署迁移服务并且购买专线来完成,详见:[https://help.aliyun.com/document_detail/56990.html](https://help.aliyun.com/document_detail/56990.html?spm=5176.208357.1107607.35.68b6390frmzT6x)
OSS提供了S3 API的兼容性,可以让您的数据从AWS S3无缝迁移到阿里云OSS上。从AWS S3迁移到OSS后,您仍然可以使用S3 API访问OSS。更多可以详见[S3迁移教程](https://help.aliyun.com/document_detail/95127.html?spm=a2c4g.11186623.2.12.65cd6ac6kayaMa#concept-pyw-sjg-qfb)。
<a name="66a56ac6"></a>
## 背景信息
① 执行在线迁移任务过程中,读取Amazon S3数据会产生公网流出流量费,该费用由Amazon方收取。<br />② 在线迁移默认不支持跨境迁移数据,若有跨境数据迁移需求需要提交工单来申请配置任务的权限。
<a name="88210852"></a>
## 准备工作
<a name="ed3070e2"></a>
### Amazon S3前提工作
> 接下来以RAM子账号来演示Amazon S3数据迁移到Aliyun OSS上。
* 预估迁移数据,进入管控台中确认S3中有的存储量与文件数量。
* 创建迁移密钥,进入AWS IAM页面中创建用户并赋予AmazonS3ReadOnlyAccess权限。
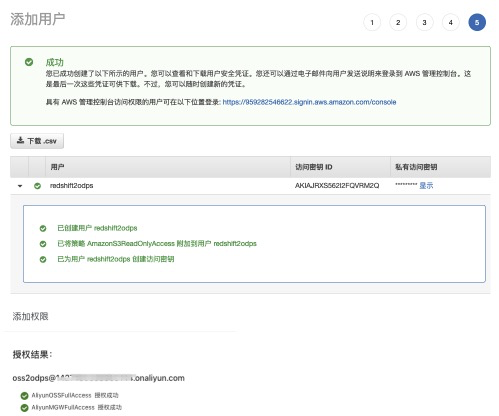
* 添加用户-->访问类型(编程访问,AK信息)-->赋予AmazonS3ReadOnlyAccess权限-->记录AK信息。
step1:进入IAM,选择添加用户。<br />![image.png]
step2:新增用户并勾选创建AK。<br />
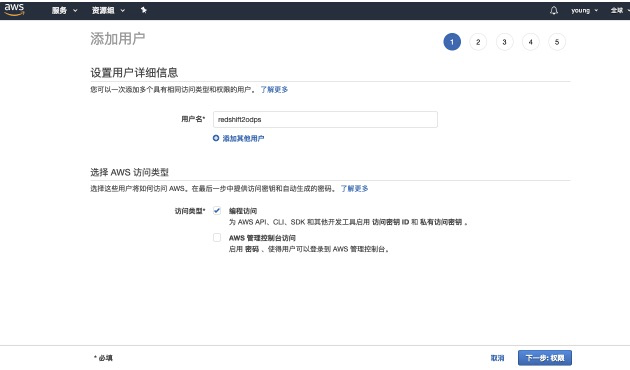
step3:选择直接附加现有策略,并赋予AmazonS3ReadOnlyAccess权限。<br />
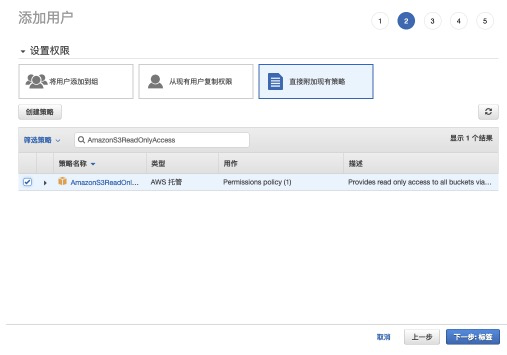
step4:记录AK信息,在数据迁移中会用到。<br />
<a name="75e5510f"></a>
### Aliyun OSS前提工作
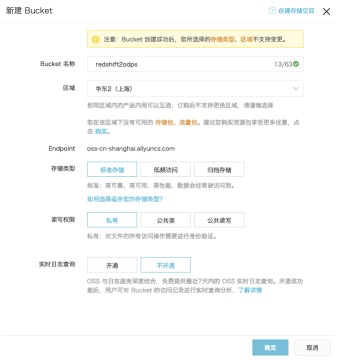
* 阿里云OSS相关操作,新创建bucket:
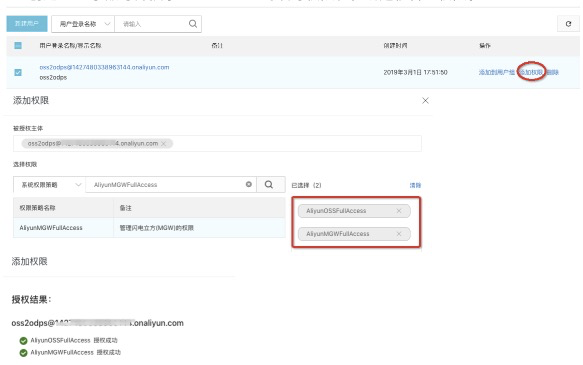
* 创建RAM子账号并授予OSS bucket的读写权限和在线迁移管理权限。
<a name="582bdcd8"></a>
## 迁移实施
> 迁移会占用源端和目的端的网络资源;迁移需要检查源端和目的端文件,如果存在文件名相同且源端的最后更新时间少于目的端,会进行覆盖。
* 进入阿里云数据在线迁移控制台:[https://mgw.console.aliyun.com/?spm=a2c4g.11186623.2.11.10fe1e02iYSAhv#/job?_k=6w2hbo](https://mgw.console.aliyun.com/?spm=a2c4g.11186623.2.11.10fe1e02iYSAhv#/job?_k=6w2hbo),并以《Aliyun OSS前提工作》中新建的子账号登录。
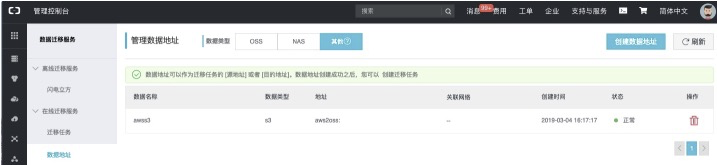
* 进入数据迁移服务-数据地址-数据类型(其他),如下:
**【创建源地址:】**<br />
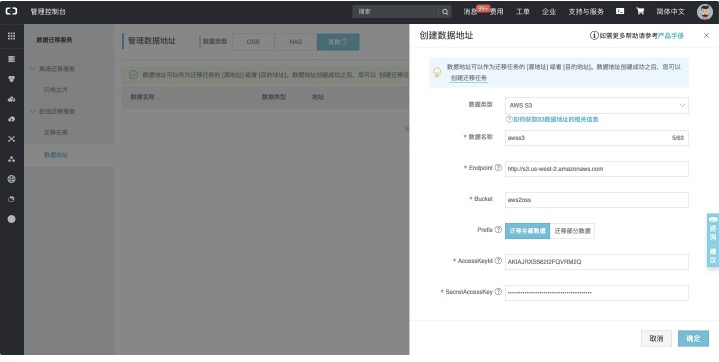
具体配置项说明详见:[https://help.aliyun.com/document_detail/95159.html](https://help.aliyun.com/document_detail/95159.html?spm=a2c4g.11186623.6.561.34e047f6yvZnaw)<br />**【创建目标地址:】**<br />
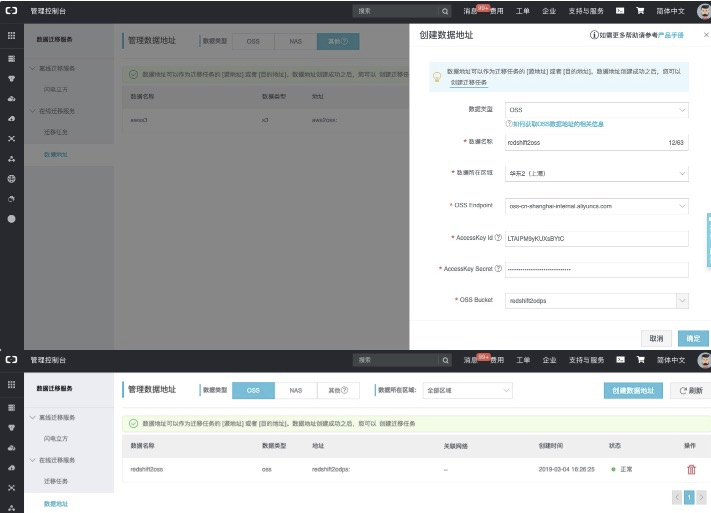
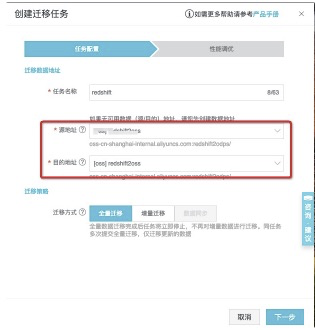
具体配置项说明详见:[https://help.aliyun.com/document_detail/95159.html](https://help.aliyun.com/document_detail/95159.html?spm=a2c4g.11186623.6.561.34e047f6yvZnaw)
<a name="b4361e56"></a>
## 创建迁移任务
从左侧tab页面中找到迁移任务,并进入页面,点击创建迁移任务。<br />![image.png]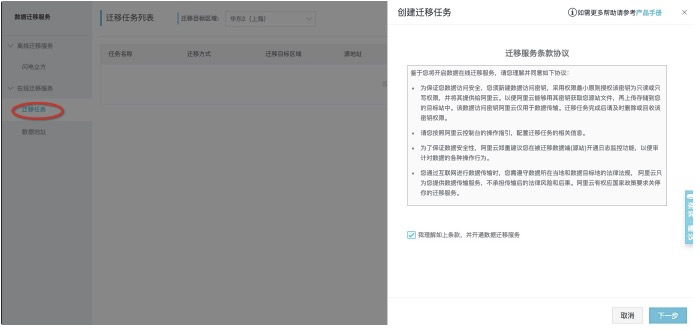
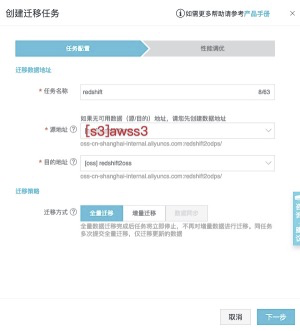
---->OSS中的数据如下:<br />
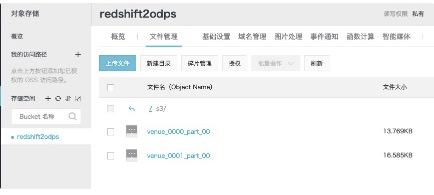
<a name="ebdc286b"></a>
# MaxCompute直接加载OSS数据
<a name="98a315c0"></a>
## 授权
在查询OSS上数据之前,需要对将OSS的数据相关权限赋给MaxCompute的访问账号,授权详见[授权文档](https://help.aliyun.com/document_detail/45389.html?spm=a2c4g.11186623.6.702.62552a95jceToT)。<br />MaxCompute需要直接访问OSS的数据,前提需要将OSS的数据相关权限赋给MaxCompute的访问账号,您可通过以下方式授予权限:
1. 当MaxCompute和OSS的owner是同一个账号时,可以直接登录阿里云账号后,[点击此处完成一键授权](https://ram.console.aliyun.com/?spm=a2c4g.11186623.2.16.4f761cdfaNk5XH#/role/authorize?request=%7B%22Requests%22:%20%7B%22request1%22:%20%7B%22RoleName%22:%20%22AliyunODPSDefaultRole%22,%20%22TemplateId%22:%20%22DefaultRole%22%7D%7D,%20%22ReturnUrl%22:%20%22https:%2F%2Fram.console.aliyun.com%2F%22,%20%22Service%22:%20%22ODPS%22%7D)。
1. 若MaxCompute和OSS不是同一个账号,此处需由OSS账号登录进行授权,详见[文档](https://help.aliyun.com/document_detail/45389.html?spm=a2c4g.11186623.6.702.62552a95jceToT)。
<a name="a6dbe7f5"></a>
## 创建外部表
在DataWorks中创建外部表,如下图所示:<br />
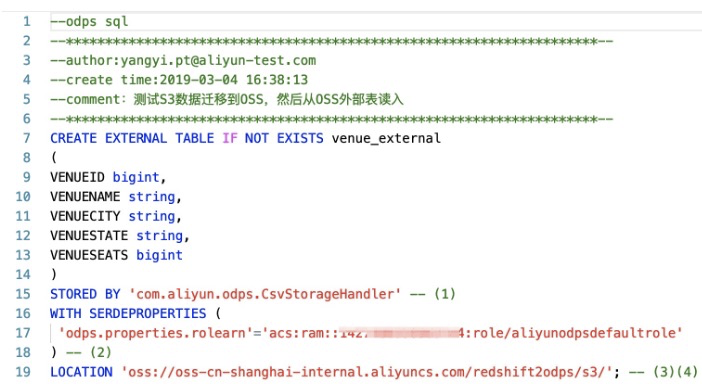
创建MaxCompute外部表DDL语句:
CREATE EXTERNAL TABLE IF NOT EXISTS venue_external
(
VENUEID bigint,
VENUENAME string,
VENUECITY string,
VENUESTATE string,
VENUESEATS bigint
)
STORED BY 'com.aliyun.odps.CsvStorageHandler' -- (1)
WITH SERDEPROPERTIES (
'odps.properties.rolearn'='acs:ram::*****:role/aliyunodpsdefaultrole'
) -- (2)
LOCATION 'oss://oss-cn-shanghai-internal.aliyuncs.com/redshift2odps/s3/'; -- (3)(4)
* com.aliyun.odps.CsvStorageHandler是内置的处理CSV格式文件的StorageHandler,它定义了如何读写CSV文件。您只需指明这个名字,相关逻辑已经由系统实现。如果用户在数据卸载到S3时候自定义了其他分隔符那么,MaxCompute也支持自定义分隔符的Handler,详见:[https://help.aliyun.com/document_detail/45389.html](https://help.aliyun.com/document_detail/45389.html)
可以直接查询返回结果:<br />select * from venue_external limit 10;
DataWorks上执行的结果如下图所示:<br />
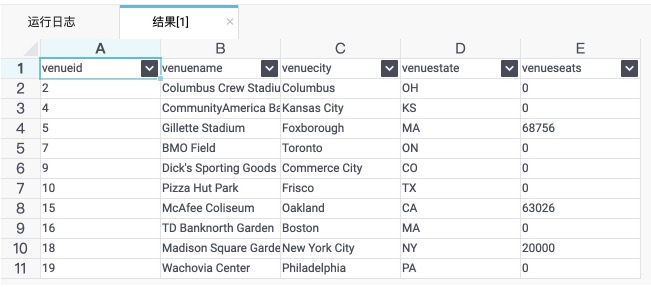
<a name="189c0f78"></a>
## 创建内部表固化数据
如果后续还需要做复杂的查询且数据量特别大的情况下,建议将外部表转换为内部表,具体示意如下:<br />create table if not exists venue as select * from venue_external;<br />
本文作者:祎休
本文为云栖社区原创内容,未经允许不得转载。
Amazon Redshift数据迁移到MaxCompute的更多相关文章
- Kafka数据迁移MaxCompute最佳实践
摘要: 本文向您详细介绍如何使用DataWorks数据同步功能,将Kafka集群上的数据迁移到阿里云MaxCompute大数据计算服务. 前提条件 搭建Kafka集群 进行数据迁移前,您需要保证自己的 ...
- Amazon Redshift数据库
Amazon Redshift介绍 Amazon Redshift是一种可轻松扩展的完全托管型PB级数据仓库,它通过使用列存储技术和并行化多个节点的查询来提供快速的查询性能,使您能够更高效的分析现有数 ...
- 阿里云大数据计算服务 - MaxCompute (原名 ODPS)
MaxCompute 是阿里EB级计算平台,经过十年磨砺,它成为阿里巴巴集团数据中台的计算核心和阿里云大数据的基础服务.去年MaxCompute 做了哪些工作,这些工作背后的原因是什么?大数据市场进入 ...
- 大数据平台Hive数据迁移至阿里云ODPS平台流程与问题记录
一.背景介绍 最近几天,接到公司的一个将当前大数据平台数据全部迁移到阿里云ODPS平台上的任务.而申请的这个ODPS平台是属于政务内网的,因考虑到安全问题当前的大数据平台与阿里云ODPS的网络是不通的 ...
- Power BI连接至Amazon Redshift
一直在使用Power BI连接至MongoDB中,但效果一直不是太理想,今天使用另一种方法,将MongoDB中的数据通过Azure Data Factory转入Amazon Redshift中,而在P ...
- amazon redshift 分析型数据库特点——本质还是列存储
Amazon Redshift 是一种快速且完全托管的 PB 级数据仓库,使您可以使用现有的商业智能工具经济高效地轻松分析您的所有数据.从最低 0.25 USD 每小时 (不承担任何义务) 直到每年每 ...
- Apsara Clouder云计算技能认证:云数据库管理与数据迁移
一.课程介绍 二.云数据库的简介及使用场景 1.云数据库简介 1.1特点: 用户按存储容量和带宽的需求付费 可移植性 按需扩展 高可用性(HA) 1.2阿里云云数据库 RDS 稳定可靠,可弹性伸缩的在 ...
- POWER BI 基于 ODBC 数据源的配置刷新-以Amazon Redshift为例
POWER BI 基于 ODBC 数据源的配置刷新-以Amazon Redshift为例 Powerbi 有多种数据源连接,可以使用它们连接到不同数据源. 如果在 Power BI Desktop 的 ...
- 【SQLServer】记一次数据迁移-标识重复的简单处理
汇总篇:http://www.cnblogs.com/dunitian/p/4822808.html#tsql 今天在数据迁移的时候因为手贱遇到一个坑爹问题,发来大家乐乐,也传授新手点经验 迁移惯用就 ...
随机推荐
- Luogu P3835 【模板】可持久化平衡树(fhq Treap)
P3835 [模板]可持久化平衡树 题意 题目背景 本题为题目普通平衡树的可持久化加强版. 题目描述 您需要写一种数据结构(可参考题目标题),来维护一些数,其中需要提供以下操作(对于各个以往的历史版本 ...
- iftop实时监控网络流量
需要安装,linux自身不自带该命令 中间的<= =>这两个左右箭头,表示的是流量的方向. TX:发送流量 RX:接收流量 TOTAL:总流量 Cumm:运行iftop到目前时间的总流量 ...
- Putty保存设置
使用putty连接服务器每次都要配置编码,有时候忘了配置,提示就出现中文乱码真是坑爹(纯英文提示也行啊),好了闲话少说,步入正题. Putty的设置保存功能隐藏的实在太好了,原来在Connection ...
- git commit规范工具
npm install -g commitizen commitizen init cz-conventional-changelog --save --save-exact 以后,凡是用到git c ...
- 一维、二维数组 与 常用的返回数组 以及 fetch_all与fetch_row的区别
一维数组:单行单列的数组. 二维数组:多行多列的数组. (至少两行两列) 索引数组: fetch_all() 返回所有数组 fetch_row() 返回一行或一列数组 (第二行需要输入两 ...
- 爬虫的终极形态:nightmare
爬虫的终极形态:nightmare nightmare 是一个基于 electron 的自动化库(意思是说它自带浏览器),用于实现爬虫或自动化测试.相较于传统的爬虫框架(scrapy/pyspider ...
- 关于JVM调优
JVM调优主要是针对内存管理方面的调优,包括控制各个代的大小,GC策略.由于GC开始垃圾回收时会挂起应用线程,严重影响了性能,调优的目是为了尽量降低GC所导致的应用线程暂停时间. 减少Full GC次 ...
- anaconda安装使用
Conda是一个开源的包.环境管理器,可以用于在同一个机器上安装不同版本的软件包及其依赖,并能够在不同的环境之间切换 下载:https://mirrors.tuna.tsinghua.edu.cn/a ...
- Flask session到期时间设置 用户登录与登出
flask版本 1.1.1 最近学习Flask开发,看官方文档产生疑问,就是session有效期的问题,默认貌似是没有有效期的,只有关闭浏览器session才会失效,其实控制session的有效期非常 ...
- TZOJ 1503 Incredible Cows(折半搜索+二分)
描述 Farmer John is well known for his great cows. Recently, the cows have decided to participate in t ...