Spark Streaming数据限流简述
Spark Streaming对实时数据流进行分析处理,源源不断的从数据源接收数据切割成一个个时间间隔进行处理;
流处理与批处理有明显区别,批处理中的数据有明显的边界、数据规模已知;而流处理数据流并没有边界,也未知数据规模;
由于流处理的数据流特征,使之数据流具有不可预测性,而且数据处理的速率还与硬件、网络等资源有关,在这种情况下如不对源源不断进来的数据流速率进行限制,那当Spark节点故障、网络故障或数据处理吞吐量下来时还有数据不断流进来,那将有可能将出现OOM进而导致Spark Streaming程序崩溃;
在Spark Streaming中不同的数据源采用不同的限速策略,但无论是Socket数据源的限流策略还是Kafka数据源的限流策略其速率(rate)的计算都是使用PIDController算法进行计算而得来;
下面从源码的角度分别介绍Socket数据源与Kafka数据源的限流处理。
速率限制的计算与更新
Spark Streaming的流处理其实是基于微批处理(MicroBatch)的,也就是说将数据流按某比较小的时间间隔将数据切割成为一段段微批数据进行处理;
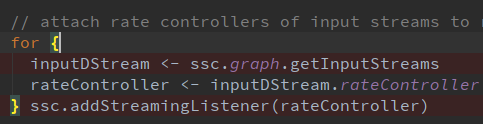
StreamingContext调用Start()启动的时候会将速率控制器(rateController)添加到StreamingListener监听器中;
当每批次处理完成时将触发监听器(RateController),使用该批处理的处理结束时间、处理延迟时间、调度延迟时间、记录行数调用PIDRateEstimator传入PID算法中(PID Controller)计算出该批次的速率(rate)并更新速率限制(rateLimit)与发布该限制速率;
override def onBatchCompleted(batchCompleted: StreamingListenerBatchCompleted) {
val elements = batchCompleted.batchInfo.streamIdToInputInfo
for {
processingEnd <- batchCompleted.batchInfo.processingEndTime
workDelay <- batchCompleted.batchInfo.processingDelay
waitDelay <- batchCompleted.batchInfo.schedulingDelay
elems <- elements.get(streamUID).map(_.numRecords)
} computeAndPublish(processingEnd, elems, workDelay, waitDelay)
}
private def computeAndPublish(time: Long, elems: Long, workDelay: Long, waitDelay: Long): Unit =
Future[Unit] {
val newRate = rateEstimator.compute(time, elems, workDelay, waitDelay)
newRate.foreach { s =>
rateLimit.set(s.toLong)
publish(getLatestRate())
}
}
Socket数据源限流
批次的限制速率上面已经算出,这里说的是接收Socket过来的数据时的数据限流;
SocketInputStream类receive方法接收到数据后将数据存入 BlockGenerator的Buffer中,在写入Buffer前调用限流器 (RateLimiter)对写入数据进行限流;
RateLimiter限流器使用了Google开源的 Guava中内置的RateLimiter限流器,该类只是对Guava限流器的简单封装;
在Spark Streaming中可通过使用两个参数配置初始速率与最大速率spark.streaming.receiver.maxRate、spark.streaming.backpressure.initialRate;亦可配置PIDController算法相关的四个参数值;
RateLimiter限流器是基于令牌桶的算法基本原理比较简单,以一个恒定的速率生成令牌放入令牌桶中,桶满则停止,处理请求时需要从令牌桶中取出令牌,当桶中无令牌可取时阻塞等待,此算法用于确保系统不被洪峰击垮。
private lazy val rateLimiter = GuavaRateLimiter.create(getInitialRateLimit().toDouble)
/**
* Push a single data item into the buffer.
*/
def addData(data: Any): Unit = {
if (state == Active) {
//调用限流器等待
waitToPush()
synchronized {
if (state == Active) {
currentBuffer += data
} else {
throw new SparkException(
"Cannot add data as BlockGenerator has not been started or has been stopped")
}
}
} else {
throw new SparkException(
"Cannot add data as BlockGenerator has not been started or has been stopped")
}
}
def waitToPush() {
//限流器申请令牌
rateLimiter.acquire()
}
Guava库中RateLimiter限流器基本使用:
//创建限流器,每秒产生令牌数1
RateLimiter rateLimiter=RateLimiter.create(1);
for (int i = 0; i < 10; i++) {
//获得一个令牌,未申请到令牌则阻塞等待
double waitTime = rateLimiter.acquire();
System.out.println(String.format("id:%d time:%d waitTime:%f",i,System.currentTimeMillis(),waitTime));
}
Kafka数据源限流的实现
在Spark Streaming Kafka包拉取Kafka数据会进行如下动作:
1、取Kafka中最新偏移量、分区
2、通过rateController限制每个分区可拉取的最大消息数
3、在DirectKafkaInputDStream中创建KafkaRDD,在其中调用相关对象拉取数据
通过如上步骤也可用看出,只要限制了Kafka某个分区的偏移量(offset)范围也就可限制从Kafka拉取的消息数量,从而达到限流的目的,Spark streaming kafka也是通过此实现的;
计算每个分区速率限制,有如下步骤:
1、通过seekToEnd获取最新可用偏移量与当前偏移量对比获得当前所有分区延迟偏移量
单个分区偏移量延迟=最新偏移量记录-当前偏移量记录
2、获取配置项中每个分区最大速率
(spark.streaming.kafka.maxRatePerPartition),背压率计算,计算每个分区背压率计算公式为:
单个分区背压率=单个分区偏移量延迟/所有分区总延迟*速率限制
速率限制(rateLimit):为通过PIDController动态计算得来
如有配置每个分区最大速率则取配置项最大速率与背压率两者中的最小值,未配置则取背压率作为每个分区速率限制;
3、将批次间隔(batchDuration)*每个分区速率限制=每个分区最大消息数
4、取当前分区偏移量+分区最大消息数 与 最新偏移量两者当中最小的,由此来控制拉取消息速率;
如当前偏移量+分区最大消息数 大于 最新偏移量则取 最新偏移量否则取 当前偏移量+分区最大消息数作为拉取Kafka数据的Offset范围;
// 限制每个分区最大消息数
protected def clamp(
offsets: Map[TopicPartition, Long]): Map[TopicPartition, Long] = {
maxMessagesPerPartition(offsets).map { mmp =>
mmp.map { case (tp, messages) =>
val uo = offsets(tp)
tp -> Math.min(currentOffsets(tp) + messages, uo)
}
}.getOrElse(offsets)
}
不管是Kafka数据源还是Socket数据源Spark Streaming中都使用了PIDController算法用于计算其速率限制值,两者的差别也只是因为两种数据源的获取方式数据特征而决定的。Socket数据源使用了Guava RateLimiter、而Kafka数据源自己实现了基于Offsets的限流;
以上说介绍的框架版本为:Spark Streaming 版本为2.3.2与spark-streaming-kafka-0-10_2.11;
参考资料:
http://kafka.apache.org
http://spark.apache.org
文章首发地址:Solinx
https://mp.weixin.qq.com/s/yHStZgTAGBPoOMpj4e27Jg
Spark Streaming数据限流简述的更多相关文章
- Spark Streaming:大规模流式数据处理的新贵(转)
原文链接:Spark Streaming:大规模流式数据处理的新贵 摘要:Spark Streaming是大规模流式数据处理的新贵,将流式计算分解成一系列短小的批处理作业.本文阐释了Spark Str ...
- Spark Streaming:大规模流式数据处理的新贵
转自:http://www.csdn.net/article/2014-01-28/2818282-Spark-Streaming-big-data 提到Spark Streaming,我们不得不说一 ...
- Spark Streaming 数据接收过程
SparkStreaming 源码分析 一节中从源码角度,描述了Streaming执行时代码的调用过程.下边就接收转化阶段过程再简单分析一下,为分析backpressure作准备. SparkStre ...
- Spark Streaming数据清理内幕彻底解密
本讲从二个方面阐述: 数据清理原因和现象 数据清理代码解析 Spark Core从技术研究的角度讲 对Spark Streaming研究的彻底,没有你搞不定的Spark应用程序. Spark Stre ...
- Spark Streaming源码解读之流数据不断接收全生命周期彻底研究和思考
本期内容 : 数据接收架构设计模式 数据接收源码彻底研究 一.Spark Streaming数据接收设计模式 Spark Streaming接收数据也相似MVC架构: 1. Mode相当于Rece ...
- Kafka:ZK+Kafka+Spark Streaming集群环境搭建(二十二)Spark Streaming接收流数据及使用窗口函数
官网文档:<http://spark.apache.org/docs/latest/streaming-programming-guide.html#a-quick-example> Sp ...
- Spark Streaming源码解读之流数据不断接收和全生命周期彻底研究和思考
本节的主要内容: 一.数据接受架构和设计模式 二.接受数据的源码解读 Spark Streaming不断持续的接收数据,具有Receiver的Spark 应用程序的考虑. Receiver和Drive ...
- 大数据技术之_19_Spark学习_04_Spark Streaming 应用解析 + Spark Streaming 概述、运行、解析 + DStream 的输入、转换、输出 + 优化
第1章 Spark Streaming 概述1.1 什么是 Spark Streaming1.2 为什么要学习 Spark Streaming1.3 Spark 与 Storm 的对比第2章 运行 S ...
- Dream_Spark-----Spark 定制版:005~贯通Spark Streaming流计算框架的运行源码
Spark 定制版:005~贯通Spark Streaming流计算框架的运行源码 本讲内容: a. 在线动态计算分类最热门商品案例回顾与演示 b. 基于案例贯通Spark Streaming的运 ...
随机推荐
- 在Windows系统中安装Redis和php_redis扩展
安装Redis (1)下载redis压缩包,git下载地址https://github.com/MSOpenTech/redis/releases 解压文件夹,在文件夹中运行cmd命令: 输入: ...
- weblogic非正常关闭,<BEA-141281>错误
在域下 find -name *.lok , 全删除: 在域下 find -name *.DAT,全删除: 然后就可以正常启动了
- display:table的用法
目前,在大多数开发环境中,已经基本不用table元素来做网页布局了,取而代之的是div+css,那么为什么不用table系表格元素呢? 1.用DIV+CSS编写出来的文件k数比用table写出来的要小 ...
- 联合索引在B+树上的存储结构及数据查找方式
能坚持别人不能坚持的,才能拥有别人未曾拥有的.关注编程大道公众号,让我们一同坚持心中所想,一起成长!! 引言 上一篇文章<MySQL索引那些事>主要讲了MySQL索引的底层原理,且对比了B ...
- java设计模式--迪米特法则
基本介绍 1.一个对象应该对其他对象保持最少的了解 2.类与类关系越密切,耦合度越大 3.迪米特法则又叫最少知道原则,即一个类对自己依赖的类知道的越少越好.也就是说,对于被依赖的类不管多么复杂,都尽量 ...
- 00.ES6简介
ES6 简介 ECMAScript 和 JavaScript 的关系 JavaScript是由ECMAScript组织维护的,ES6的名字就取自ECMAScript中的E和S,6的意思是已经发布到第6 ...
- Lucene之分析器
什么是分析器? 分析(Analysis)在Lucene中指的是将域(Field)文本转换为最基本的索引表示单元—项(Term)的过程. 分析器(Analyzer)对分析操作进行了封装,通过执行一系列操 ...
- P2094运输
-------------------- 链接:Miku ------------------- 这是一道水贪心,很容易想到做法就是把最贵的两个放在一块,让后当成一个重新放回队列 ---------- ...
- CSS中before、after伪类选择器的巧用
大家好,今天给大家带来使用css中 before . after 实现两个效果,话不多说,我们先来看看, before 和 after 它们的作用是什么 选择器 作用 before 向选定的元素前插入 ...
- 2019sdqdCSP-J游记
特别鸣谢:Miku -------------------------- 中午上了车,和ljx坐在一块.太阳是多么好啊,我们在看着刚出的tg题,cmz找不到了准考证,sbl在临时打印准考证 等到好不容 ...