Flume与Logstash比较
Flume与Logstash相比,个人的体会如下:
- Logstash比较偏重于字段的预处理;而Flume偏重数据的传输;
- Logstash有几十个插件,配置灵活;FLume则是强调用户的自定义开发(source和sink的种类也有一二十个吧,channel就比较少了)。
- Logstash的input和filter还有output之间都存在buffer,进行缓冲;Flume直接使用channel做持久化(可以理解为没有filter)
一、Logstash浅谈:
- input负责数据的输入(产生或者说是搜集,以及解码decode);
- Filter负责对采集的日志进行分析,提取字段(一般都是提取关键的字段,存储到elasticsearch中进行检索分析);
- output负责把数据输出到指定的存储位置(如果是采集agent,则一般是发送到消息队列中,如kafka,redis,mq;如果是分析汇总端,则一般是发送到elasticsearch中)
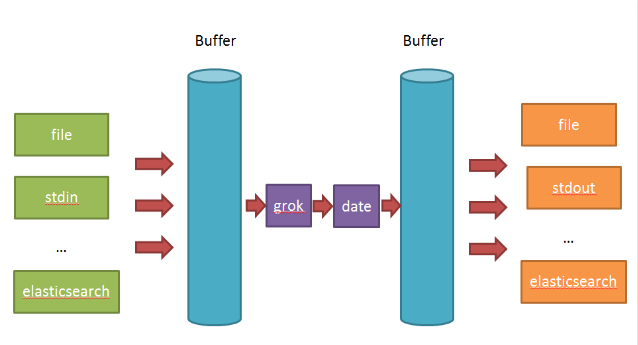
在Logstash比较看重input,filter,output之间的协同工作,因此多个输入会把数据汇总到input和filter之间的buffer中。filter则会从buffer中读取数据,进行过滤解析,然后存储在filter于output之间的Buffer中。当buffer满足一定的条件时,会触发output的刷新。
二、Flume浅谈
在Flume中:
- source 负责与Input同样的角色,负责数据的产生或搜集(一般是对接一些RPC的程序或者是其他的flume节点的sink)
- channel 负责数据的存储持久化(一般都是memory或者file两种)
- sink 负责数据的转发(用于转发给下一个flume的source或者最终的存储点——如HDFS)
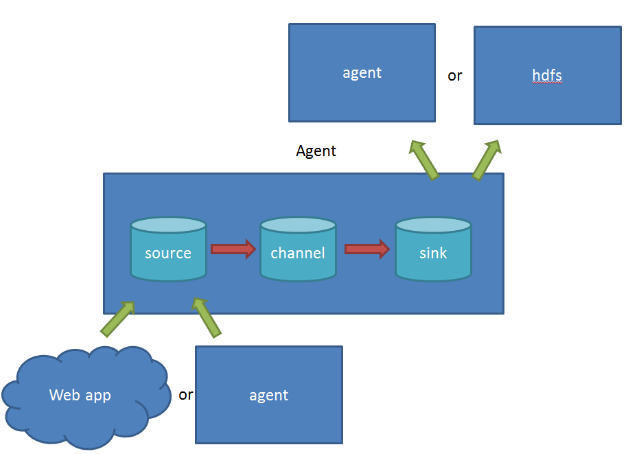
Flume比较看重数据的传输,因此几乎没有数据的解析预处理。仅仅是数据的产生,封装成event然后传输。传输的时候flume比logstash多考虑了一些可靠性。因为数据会持久化在channel中(一般有两种可以选择,memoryChannel就是存在内存中,另一个就是FileChannel存储在文件种),数据只有存储在下一个存储位置(可能是最终的存储位置,如HDFS;也可能是下一个Flume节点的channel),数据才会从当前的channel中删除。这个过程是通过事务来控制的,这样就保证了数据的可靠性。
不过flume的持久化也是有容量限制的,比如内存如果超过一定的量,也一样会爆掉。
参见:http://www.cnblogs.com/xing901022/p/5631445.html
Flume与Logstash比较的更多相关文章
- 聊聊Flume和Logstash的那些事儿
在某个Logstash的场景下,我产生了为什么不能用Flume代替Logstash的疑问,因此查阅了不少材料在这里总结,大部分都是前人的工作经验下,加了一些我自己的思考在里面,希望对大家有帮助. 本文 ...
- Flume日志采集系统——初体验(Logstash对比版)
这两天看了一下Flume的开发文档,并且体验了下Flume的使用. 本文就从如下的几个方面讲述下我的使用心得: 初体验--与Logstash的对比 安装部署 启动教程 参数与实例分析 Flume初体验 ...
- 【大数据实战】Logstash采集->Kafka->ElasticSearch检索
1. Logstash概述 Logstash的官网地址为:https://www.elastic.co/cn/products/logstash,以下是官方对Logstash的描述. Logstash ...
- Logstash介绍及Input插件介绍
一.Logstash简介 Logstash是一个开源数据收集引擎,具有实时管道功能.Logstash可以动态地将来自不同数据源的数据统一起来,并将数据标准化到你所选择的目的地. Logstash管 ...
- Openstack Basic
html,body { } .CodeMirror { height: auto } .CodeMirror-scroll { } .CodeMirror-lines { padding: 4px 0 ...
- linux日志审计项目案例实战(生产环境日志审计项目解决方案)
所谓日志审计,就是记录所有系统及相关用户行为的信息,并且可以自动分析.处理.展示(包括文本或者录像) 推荐方法:sudo配合syslog服务,进行日志审计(信息较少,效果不错) 1.安装sudo命令. ...
- Kafka connect快速构建数据ETL通道
摘要: 作者:Syn良子 出处:http://www.cnblogs.com/cssdongl 转载请注明出处 业余时间调研了一下Kafka connect的配置和使用,记录一些自己的理解和心得,欢迎 ...
- Linux实战教学笔记14:用户管理初级(下)
第十四节 用户管理初级(下) 标签(空格分隔): Linux实战教学笔记-陈思齐 ---更多资料点我查看 1,用户查询相关命令id,finger,users,w,who,last,lastlog,gr ...
- ELK日志套件安装与使用
1.ELK介绍 ELK不是一款软件,而是elasticsearch+Logstash+kibana三款开源软件组合而成的日志收集处理套件,堪称神器.其中Logstash负责日志收集,elast ...
随机推荐
- 内建DNS服务器--BIND
参考 BIND 官网:http://www.isc.org/downloads/bind/ 1.系统环境说明 [root@clsn6 ~]# cat /etc/redhat-release CentO ...
- C#.NET常见问题(FAQ)-如何判断某个字符是否为汉字
字符强制转换成int可以判断字符数值大小,在下面所示范围内的就是中文 此外还可以判断是否是数字或者字母,用char.IsLetter和char.IsDigit方法 从先这个范例可以看出,中文也 ...
- asp.net 除法保留小数
(Convert.ToDouble(num1)/Convert.ToDouble(num2)).ToString("0.00"); .只要求保留N位不四舍5入 float f = ...
- 我的webrequest经验
1 webrequest 是什么:编程方式模拟web请求,利用webrequest可以实现 相当于一个浏览器请求一个网页的效果,但是它始终是模拟请求, 与浏览器输入框输入网址请求不一样. 2 程序设计 ...
- VMware vSphere 5.1 群集深入解析(一)
http://virtualbox.blog.51cto.com/531002/1168293 VMware vSphere 5.1 Clustering Deepdive HA.DRS.Storag ...
- 使用Phantomjs和ChromeDriver添加Cookies的方法
一.查看代码 : namespace ToutiaoSpider { class Program { static void Main(string[] args) { var db = Db.Get ...
- Eclipse项目修改没有同步到编译的问题
有两个原因: 1:项目有错,不能正常编译:查看是否有Jar包冲突.JDK版本问题等: 2:编译输出目录配置错误: Maven项目会修改项目编译时的输出路径到target文件夹,但是我们用Myelips ...
- django之创建第6-2个项目-过滤器列表
转载:http://www.lidongkui.com/django-template-filter-table 一.转化为小写 {{ name | lower }} 二.串联:先转义文本到HTML, ...
- Java循环中标签的作用(转)
转自:http://lihengzkj.iteye.com/blog/1090034 以前不知道在循环中可以使用标签.最近遇到后,举得还是有其独特的用处的.我这么说的意思是说标签在循环中可以改变循环执 ...
- appium界面运行过程(结合日志截图分析)
appium界面运行过程: 1.启动一个http服务器:127.0.0.1:47232.根据测试代码setUp()进行初始化,在http服务器上建立一个session对象3.开始调用adb,找到连接上 ...