Flume与Logstash比较
Flume与Logstash相比,个人的体会如下:
- Logstash比较偏重于字段的预处理;而Flume偏重数据的传输;
- Logstash有几十个插件,配置灵活;FLume则是强调用户的自定义开发(source和sink的种类也有一二十个吧,channel就比较少了)。
- Logstash的input和filter还有output之间都存在buffer,进行缓冲;Flume直接使用channel做持久化(可以理解为没有filter)
一、Logstash浅谈:
- input负责数据的输入(产生或者说是搜集,以及解码decode);
- Filter负责对采集的日志进行分析,提取字段(一般都是提取关键的字段,存储到elasticsearch中进行检索分析);
- output负责把数据输出到指定的存储位置(如果是采集agent,则一般是发送到消息队列中,如kafka,redis,mq;如果是分析汇总端,则一般是发送到elasticsearch中)
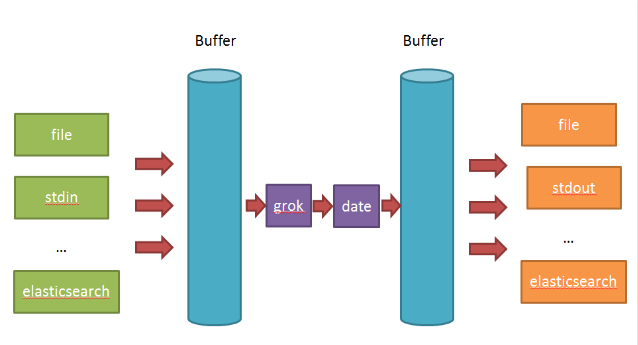
在Logstash比较看重input,filter,output之间的协同工作,因此多个输入会把数据汇总到input和filter之间的buffer中。filter则会从buffer中读取数据,进行过滤解析,然后存储在filter于output之间的Buffer中。当buffer满足一定的条件时,会触发output的刷新。
二、Flume浅谈
在Flume中:
- source 负责与Input同样的角色,负责数据的产生或搜集(一般是对接一些RPC的程序或者是其他的flume节点的sink)
- channel 负责数据的存储持久化(一般都是memory或者file两种)
- sink 负责数据的转发(用于转发给下一个flume的source或者最终的存储点——如HDFS)
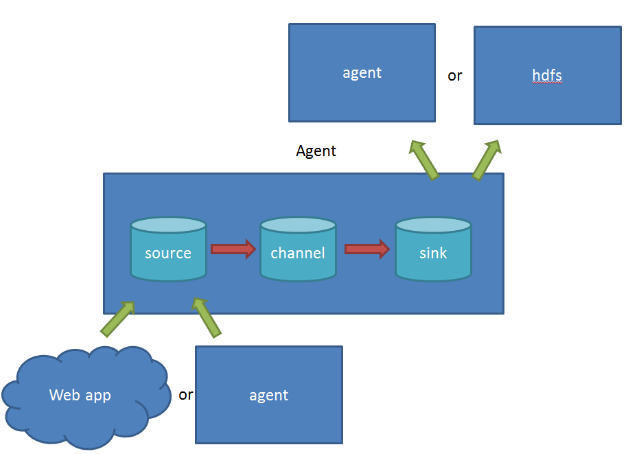
Flume比较看重数据的传输,因此几乎没有数据的解析预处理。仅仅是数据的产生,封装成event然后传输。传输的时候flume比logstash多考虑了一些可靠性。因为数据会持久化在channel中(一般有两种可以选择,memoryChannel就是存在内存中,另一个就是FileChannel存储在文件种),数据只有存储在下一个存储位置(可能是最终的存储位置,如HDFS;也可能是下一个Flume节点的channel),数据才会从当前的channel中删除。这个过程是通过事务来控制的,这样就保证了数据的可靠性。
不过flume的持久化也是有容量限制的,比如内存如果超过一定的量,也一样会爆掉。
参见:http://www.cnblogs.com/xing901022/p/5631445.html
Flume与Logstash比较的更多相关文章
- 聊聊Flume和Logstash的那些事儿
在某个Logstash的场景下,我产生了为什么不能用Flume代替Logstash的疑问,因此查阅了不少材料在这里总结,大部分都是前人的工作经验下,加了一些我自己的思考在里面,希望对大家有帮助. 本文 ...
- Flume日志采集系统——初体验(Logstash对比版)
这两天看了一下Flume的开发文档,并且体验了下Flume的使用. 本文就从如下的几个方面讲述下我的使用心得: 初体验--与Logstash的对比 安装部署 启动教程 参数与实例分析 Flume初体验 ...
- 【大数据实战】Logstash采集->Kafka->ElasticSearch检索
1. Logstash概述 Logstash的官网地址为:https://www.elastic.co/cn/products/logstash,以下是官方对Logstash的描述. Logstash ...
- Logstash介绍及Input插件介绍
一.Logstash简介 Logstash是一个开源数据收集引擎,具有实时管道功能.Logstash可以动态地将来自不同数据源的数据统一起来,并将数据标准化到你所选择的目的地. Logstash管 ...
- Openstack Basic
html,body { } .CodeMirror { height: auto } .CodeMirror-scroll { } .CodeMirror-lines { padding: 4px 0 ...
- linux日志审计项目案例实战(生产环境日志审计项目解决方案)
所谓日志审计,就是记录所有系统及相关用户行为的信息,并且可以自动分析.处理.展示(包括文本或者录像) 推荐方法:sudo配合syslog服务,进行日志审计(信息较少,效果不错) 1.安装sudo命令. ...
- Kafka connect快速构建数据ETL通道
摘要: 作者:Syn良子 出处:http://www.cnblogs.com/cssdongl 转载请注明出处 业余时间调研了一下Kafka connect的配置和使用,记录一些自己的理解和心得,欢迎 ...
- Linux实战教学笔记14:用户管理初级(下)
第十四节 用户管理初级(下) 标签(空格分隔): Linux实战教学笔记-陈思齐 ---更多资料点我查看 1,用户查询相关命令id,finger,users,w,who,last,lastlog,gr ...
- ELK日志套件安装与使用
1.ELK介绍 ELK不是一款软件,而是elasticsearch+Logstash+kibana三款开源软件组合而成的日志收集处理套件,堪称神器.其中Logstash负责日志收集,elast ...
随机推荐
- GIF添加3D加速
由于浏览器内核对Gif格式的图片会产生卡的情况,所以我们需要告诉浏览器,开启一下加速,方法很简单,就是利用css3的特性,强制告诉浏览器,这是个元素,需要3D转换,请务必开启加速效果 方法1 给gif ...
- [Algorithm] Reservoir Sampling
Given a stream of elements too large to store in memory, pick a random element from the stream with ...
- ActiveMQ持久化方式
ActiveMQ持久化方式 发表于8个月前(2014-09-04 15:55) 阅读(686) | 评论(0) 17人收藏此文章, 我要收藏 赞1 慕课网,程序员升职加薪神器,点击免费学习 摘要 ...
- message sent to deallocated instance
在XCode的以前版本中,如果遇到了 [代码]c#/cpp/oc代码: 1 message sent to deallocated instance 0x6d564f0 我们可以使用info mall ...
- 查看一个目录是否已经mount --bind
执行 mountpoint -q /test/mount echo $? 如果是0表示已经mount mountpoint -q /test/mount || mount -o bind /some/ ...
- 转:VS2013快捷键大全
Ctrl+E,D ----格式化全部代码 Ctrl+E,F ----格式化选中的代码 CTRL + SHIFT + B生成解决方案 CTRL + F7 生成编译 CTRL + O 打开文件 CTRL ...
- openerp学习笔记 视图继承(tree、form、search)
支持的视图类型:form.tree.search ... 支持的定位方法: <notebook position="inside"> ...
- 大数据(十一) - Mahout
传统数据挖掘/机器学习库存在的问题 缺少一个活跃的技术社区 扩展性差 文档化差,缺少实例 不开源.商业化库 通常由研究机 ...
- Lotus Domino和关系型数据库(LEI,DESC,JDBC连接)
Domino和关系数据库进行交互是日常项目开发中经常涉及到的一个方面,每个domino开发人员都写过这样的程序,本文就这个方面做一下简单的总结. 一.工具篇 1.使用LEI(Lotus Enterpr ...
- Linux中的共享链接库shared libraries
可执行文件的静态链接和动态链接静态链接会将需要的库函数在编译时一并包含, 所以体积会比较大. 使用ldd命令查看可执行文件链接的库 $ ldd /sbin/ldconfig not a dynamic ...