原始的生成对抗网络GAN
论文地址:https://arxiv.org/pdf/1406.2661.pdf
1、简介:
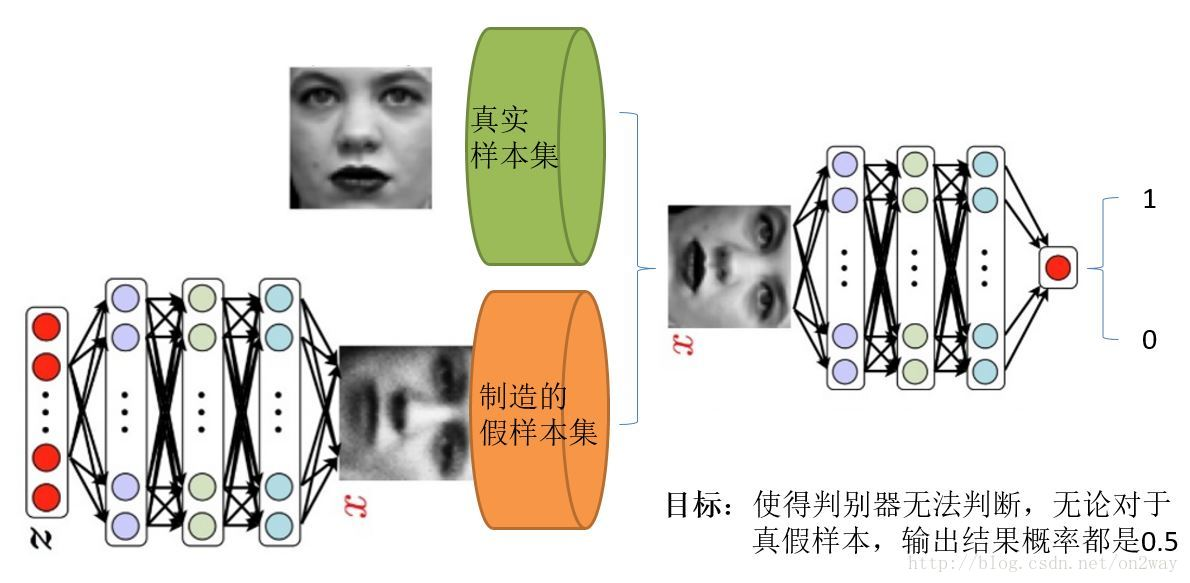
GAN的两个模型
- 判别模型:就是图中右半部分的网络,直观来看就是一个简单的神经网络结构,输入就是一副图像,输出就是一个概率值,用于判断真假使用(概率值大于0.5那就是真,小于0.5那就是假),真假也不过是人们定义的概率而已。
- 生成模型:生成模型要做什么呢,同样也可以看成是一个神经网络模型,输入是一组随机数Z,输出是一个图像,不再是一个数值。从图中可以看到,会存在两个数据集,一个是真实数据集,这好说,另一个是假的数据集,那这个数据集就是有生成网络造出来的数据集。
我们再来理解一下GAN的目标是要干什么:
- 判别网络的目的:就是能判别出来属于的一张图它是来自真实样本集还是假样本集。假如输入的是真样本,网络输出就接近1,输入的是假样本,网络输出接近0,那么很完美,达到了很好判别的目的。
- 生成网络的目的:生成网络是造样本的,它的目的就是使得自己造样本的能力尽可能强,强到什么程度呢,你判别网络没法判断我是真样本还是假样本。
G和D的异同点
相同点是:
- 这两个模型都可以看成是一个黑匣子,接受输入然后有一个输出,类似一个函数,一个输入输出映射。
不同点是:
- 生成模型功能:比作是一个样本生成器,输入一个噪声/样本,然后把它包装成一个逼真的样本,也就是输出。
- 判别模型:比作一个二分类器(如同0-1分类器),来判断输入的样本是真是假。(就是输出值大于0.5还是小于0.5);
几点说明:
- 我们有的只是真实采集而来的人脸样本数据集,仅此而已,而且很关键的一点是我们连人脸数据集的类标签都没有,也就是我们不知道那个人脸对应的是谁。(因此GAN算是无监督算法)
- 生成网络生成的假样本进去了判别网络以后,判别网络给出的结果是一个接近0.5的值,极限情况就是0.5,也就是说判别不出来了,这就是纳什平衡了。
2、训练:

训练方式:
G和D交替优化:
对于D:真样本集以及它们的label(都是1)、假样本集以及它们的label(都是0),这样单就判别网络来说,此时问题就变成了一个再简单不过的有监督的二分类问题了,直接送到神经网络模型中训练就完事了。
对于G:样本集(只有假样本集,没有真样本集)对应的label全为1,只有一类训练在训练这个串接的网络的时候,一个很重要的操作就是不要判别网络的参数发生变化,也就是不让它参数发生更新,只是把误差一直传,传到生成网络那块后更新生成网络的参数。
目标函数公式:

这个公式既然是最大最小的优化,那就不是一步完成的,其实对比我们的分析过程也是这样的,这里现优化D,然后在取优化G,本质上是两个优化问题,把拆解就如同下面两个公式:
优化D:
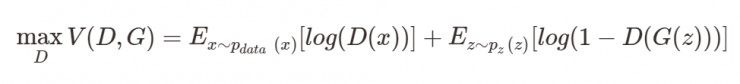
优化G:

可以看到,优化D的时候,也就是判别网络,其实没有生成网络什么事,后面的G(z)这里就相当于已经得到的假样本。优化D的公式的第一项,使的真样本x输入的时候,得到的结果越大越好,可以理解,因为需要真样本的预测结果越接近于1越好嘛。对于假样本,需要优化是的其结果越小越好,也就是D(G(z))越小越好,因为它的标签为0。但是呢第一项是越大,第二项是越小,这不矛盾了,所以呢把第二项改成1-D(G(z)),这样就是越大越好,两者合起来就是越大越好。 那么同样在优化G的时候,这个时候没有真样本什么事,所以把第一项直接却掉了。这个时候只有假样本,但是我们说这个时候是希望假样本的标签是1的,所以是D(G(z))越大越好,但是呢为了统一成1-D(G(z))的形式,那么只能是最小化1-D(G(z)),本质上没有区别,只是为了形式的统一。之后这两个优化模型可以合并起来写,就变成了最开始的那个最大最小目标函数了。
两种说法:
GAN强大之处在于可以自动的学习原始真实样本集的数据分布。
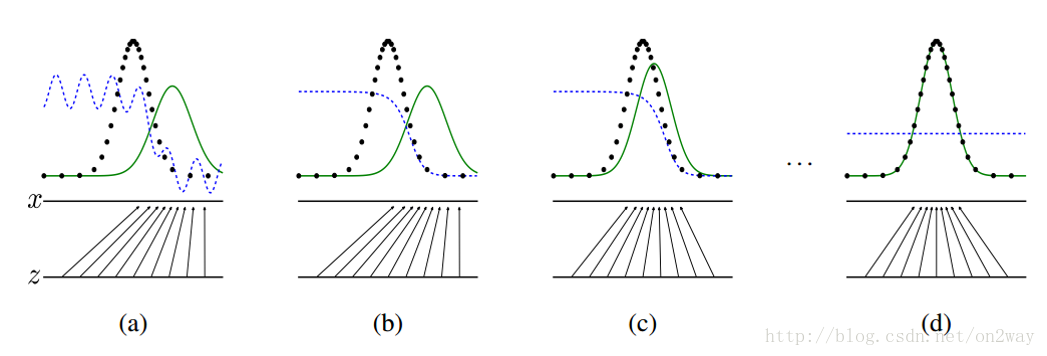
这张图表明的是GAN的生成网络如何一步步从均匀分布学习到正太分布的。原始数据x服从正太分布,这个过程你也没告诉生成网络说你得用正太分布来学习,但是生成网络学习到了。假设你改一下x的分布,不管什么分布,生成网络可能也能学到。这就是GAN可以自动学习真实数据的分布的强大之处。
如果让你说从随机噪声到人脸应该服从什么分布,你不可能知道。这是一层层映射之后组合起来的非常复杂的分布映射规律。然而GAN的机制可以学习到,也就是说GAN学习到了真实样本集的数据分布。
GAN强大之处在于可以自动的定义潜在损失函数。
什么意思呢,这应该说的是判别网络可以自动学习到一个好的判别方法,其实就是等效的理解为可以学习到好的损失函数,来比较好或者不好的判别出来结果。虽然大的loss函数还是我们人为定义的,基本上对于多数GAN也都这么定义就可以了,但是判别网络潜在学习到的损失函数隐藏在网络之中,不同的问题这个函数就不一样,所以说可以自动学习这个潜在的损失函数。
3、GAN 的优点:
(以下部分摘自ian goodfellow 在Quora的问答)
● GAN是一种生成式模型,相比较其他生成模型(玻尔兹曼机和GSNs)只用到了反向传播,而不需要复杂的马尔科夫链
● 相比其他所有模型, GAN可以产生更加清晰,真实的样本
● GAN采用的是一种无监督的学习方式训练,可以被广泛用在无监督学习和半监督学习领域
● 相比于变分自编码器, GANs没有引入任何决定性偏置( deterministic bias),变分方法引入决定性偏置,因为他们优化对数似然的下界,而不是似然度本身,这看起来导致了VAEs生成的实例比GANs更模糊
● 相比VAE, GANs没有变分下界,如果鉴别器训练良好,那么生成器可以完美的学习到训练样本的分布.换句话说,GANs是渐进一致的,但是VAE是有偏差的
● GAN应用到一些场景上,比如图片风格迁移,超分辨率,图像补全,去噪,避免了损失函数设计的困难,不管三七二十一,只要有一个的基准,直接上判别器,剩下的就交给对抗训练了。
4、 GAN的缺点:
● 训练GAN需要达到纳什均衡,有时候可以用梯度下降法做到,有时候做不到.我们还没有找到很好的达到纳什均衡的方法,所以训练GAN相比VAE或者PixelRNN是不稳定的,但我认为在实践中它还是比训练玻尔兹曼机稳定的多
● GAN不适合处理离散形式的数据,比如文本
● GAN存在训练不稳定、梯度消失、模式崩溃的问题(目前已解决)
模式崩溃(model collapse)原因
一般出现在GAN训练不稳定的时候,具体表现为生成出来的结果非常差,但是即使加长训练时间后也无法得到很好的改善。
具体原因可以解释如下:GAN采用的是对抗训练的方式,G的梯度更新来自D,所以G生成的好不好,得看D怎么说。具体就是G生成一个样本,交给D去评判,D会输出生成的假样本是真样本的概率(0-1),相当于告诉G生成的样本有多大的真实性,G就会根据这个反馈不断改善自己,提高D输出的概率值。但是如果某一次G生成的样本可能并不是很真实,但是D给出了正确的评价,或者是G生成的结果中一些特征得到了D的认可,这时候G就会认为我输出的正确的,那么接下来我就这样输出肯定D还会给出比较高的评价,实际上G生成的并不怎么样,但是他们两个就这样自我欺骗下去了,导致最终生成结果缺失一些信息,特征不全。
为什么GAN中的优化器不常用SGD
1. SGD容易震荡,容易使GAN训练不稳定,
2. GAN的目的是在高维非凸的参数空间中找到纳什均衡点,GAN的纳什均衡点是一个鞍点,但是SGD只会找到局部极小值,因为SGD解决的是一个寻找最小值的问题,GAN是一个博弈问题。
为什么GAN不适合处理文本数据
1. 文本数据相比较图片数据来说是离散的,因为对于文本来说,通常需要将一个词映射为一个高维的向量,最终预测的输出是一个one-hot向量,假设softmax的输出是(0.2, 0.3, 0.1,0.2,0.15,0.05)那么变为onehot是(0,1,0,0,0,0),如果softmax输出是(0.2, 0.25, 0.2, 0.1,0.15,0.1 ),one-hot仍然是(0, 1, 0, 0, 0, 0),所以对于生成器来说,G输出了不同的结果但是D给出了同样的判别结果,并不能将梯度更新信息很好的传递到G中去,所以D最终输出的判别没有意义。
2. 另外就是GAN的损失函数是JS散度,JS散度不适合衡量不想交分布之间的距离。
(WGAN虽然使用wassertein距离代替了JS散度,但是在生成文本上能力还是有限,GAN在生成文本上的应用有seq-GAN,和强化学习结合的产物)
5、训练GAN的一些技巧
1. 输入规范化到(-1,1)之间,最后一层的激活函数使用tanh(BEGAN除外)
2. 使用wassertein GAN的损失函数,
3. 如果有标签数据的话,尽量使用标签,也有人提出使用反转标签效果很好,另外使用标签平滑,单边标签平滑或者双边标签平滑
4. 使用mini-batch norm, 如果不用batch norm 可以使用instance norm 或者weight norm
5. 避免使用RELU和pooling层,减少稀疏梯度的可能性,可以使用leakrelu激活函数
6. 优化器尽量选择ADAM,学习率不要设置太大,初始1e-4可以参考,另外可以随着训练进行不断缩小学习率,
7. 给D的网络层增加高斯噪声,相当于是一种正则
参考:
https://blog.csdn.net/on2way/article/details/72773771
https://blog.csdn.net/qq_25737169/article/details/78857724
原始的生成对抗网络GAN的更多相关文章
- 用MXNet实现mnist的生成对抗网络(GAN)
用MXNet实现mnist的生成对抗网络(GAN) 生成式对抗网络(Generative Adversarial Network,简称GAN)由一个生成网络与一个判别网络组成.生成网络从潜在空间(la ...
- 人工智能中小样本问题相关的系列模型演变及学习笔记(二):生成对抗网络 GAN
[说在前面]本人博客新手一枚,象牙塔的老白,职业场的小白.以下内容仅为个人见解,欢迎批评指正,不喜勿喷![握手][握手] [再啰嗦一下]本文衔接上一个随笔:人工智能中小样本问题相关的系列模型演变及学习 ...
- TensorFlow从1到2(十二)生成对抗网络GAN和图片自动生成
生成对抗网络的概念 上一篇中介绍的VAE自动编码器具备了一定程度的创造特征,能够"无中生有"的由一组随机数向量生成手写字符的图片. 这个"创造能力"我们在模型中 ...
- 生成对抗网络GAN介绍
GAN原理 生成对抗网络GAN由生成器和判别器两部分组成: 判别器是常规的神经网络分类器,一半时间判别器接收来自训练数据中的真实图像,另一半时间收到来自生成器中的虚假图像.训练判别器使得对于真实图像, ...
- 生成对抗网络(GAN)
基本思想 GAN全称生成对抗网络,是生成模型的一种,而他的训练则是处于一种对抗博弈状态中的. 譬如:我要升职加薪,你领导力还不行,我现在领导力有了要升职加薪,你执行力还不行,我现在执行力有了要升职加薪 ...
- 深度学习-生成对抗网络GAN笔记
生成对抗网络(GAN)由2个重要的部分构成: 生成器G(Generator):通过机器生成数据(大部分情况下是图像),目的是“骗过”判别器 判别器D(Discriminator):判断这张图像是真实的 ...
- 深度学习框架PyTorch一书的学习-第七章-生成对抗网络(GAN)
参考:https://github.com/chenyuntc/pytorch-book/tree/v1.0/chapter7-GAN生成动漫头像 GAN解决了非监督学习中的著名问题:给定一批样本,训 ...
- 科普 | 生成对抗网络(GAN)的发展史
来源:https://en.wikipedia.org/wiki/Edmond_de_Belamy 五年前,Generative Adversarial Networks(GANs)在深度学习领域掀起 ...
- 利用tensorflow训练简单的生成对抗网络GAN
对抗网络是14年Goodfellow Ian在论文Generative Adversarial Nets中提出来的. 原理方面,对抗网络可以简单归纳为一个生成器(generator)和一个判断器(di ...
随机推荐
- html09
1.Jquery的常用方法1)选择器2)操作节点以下的 obj 都是指 jQuery对象 1.操作样式 obj.css() :不加参数是获取节点的css样式 obj.css({"属性&quo ...
- 9/24matplotlib使用入门
---恢复内容开始--- matplotlib的使用中有好几种输出风格,有matlab风格,和官方文档的as风格,各有所长,本文对比介绍官方文档中的使用风格. 我们画图的目的是要将函数以图像显示出来, ...
- visual studio 2010 winform程序不能添加对system.web的引用
visual studio 2010 winform程序不能添加对system.web的引用[转载] 需要引用到System.Web.发现没有“System.Web”.在通过“浏览”方式,找到该DLL ...
- mysql存储引擎管理使用
mysql采用插件化架构,可以支持不同的存储引擎,比如myisam,innodb.本文简单的介绍mysql存储引擎的管理与使用. 1.查看mysql存储引擎:show engines; 可以看到,my ...
- Java代码质量度量工具大阅兵
FindBugs FindBugs, a program which uses static analysis to look for bugs in Java code. It is free so ...
- Linux基础命令---last
last 显示以前登录过的用户信息,last指令会搜索/var/log/wtmp文件(或者是经过-f选项指定的文件),然后列出文件中所有的用户信息.如果执行last指令时提示“last /var/lo ...
- 基于Spring Cloud的微服务落地
微服务架构模式的核心在于如何识别服务的边界,设计出合理的微服务.但如果要将微服务架构运用到生产项目上,并且能够发挥该架构模式的重要作用,则需要微服务框架的支持. 在Java生态圈,目前使用较多的微服务 ...
- Linux 搭建FTP
Linux 搭建FTP 步骤一:安装 vsftpd 1,运行以下命令安装 vsftpd. yum install -y vsftpd 出现下图表示安装成功. 2,打开etc/vsftpd cd /et ...
- 实验二Java面向对象程序设计
一.单元测试 了解三种代码: 1.伪代码:类似于自然语言说明,描述实现逻辑思维 2.产品代码:程序员编辑的开发代码,要求可修改.可移植 3.测试代码:我理解是相当于开发软件在软件开放之前,程序员找到b ...
- vijos 运输计划 - 二分答案 - 差分 - Tarjan
Description 公元 2044 年,人类进入了宇宙纪元.L 国有 n 个星球,还有 n−1 条双向航道,每条航道建立在两个星球之间,这 n−1 条航道连通了 L 国的所有星球.小 P 掌管一家 ...