Robot Framework分层、开发系统关键字
|
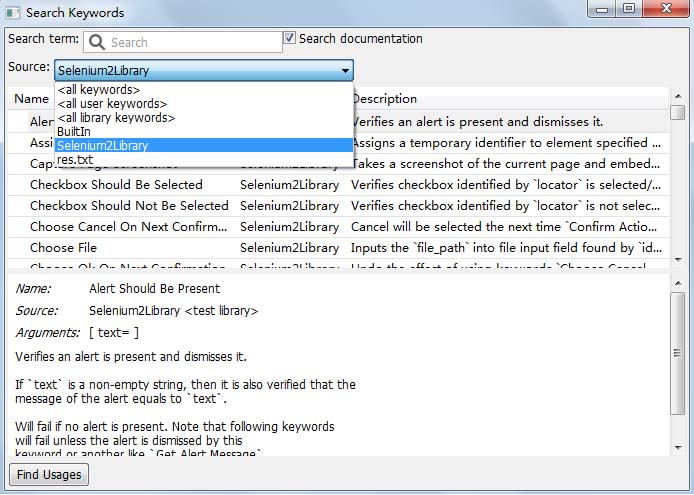
2.Content Assistance:内容助手
|
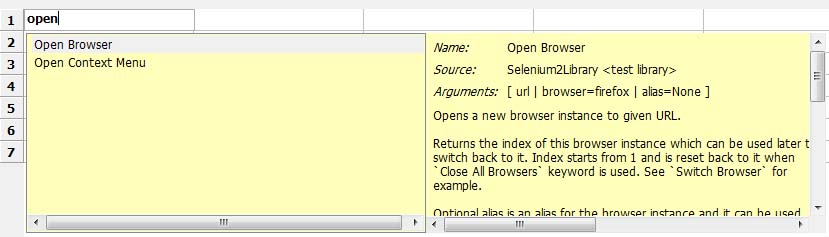


5.New User Keyword
四.工作区EDIT
大体分成3个部分。
(1):加载外部文件
Add Library :加载测试库,主要是[PYTHON目录]\Lib\site-packages里的测试库
Add Resource:加载资源,主要是你工程相关的资源文件
Add Variables:加载变量文件,不怎么用,可暂时忽略
(2):定义内部变量
Add Scalar:定义变量
Add List:定义列表型变量
(3):元数据定义
Add Metadata:定义元数据。我是直接翻译的,这个是新增加的部分,大概看了一下作用是在report和log里显示定义好的内容,格式和document一样。
2.添加Resource(在Suite中)
3.添加Library(在Suite中)
4.添加成功的标志,在Source中出现Selenium2Library和res1
5.setting(包括Project,Suit,Case,Resource,User Keywords图片就不一一上传了)

Documentation:文档,每一项都有。可以给当前的对象加入文档说明。
Suite Setup指的是测试套件启动的时候就执行某个关键字。(例:我在Suite Setup设置了Sleep | 5sec,表示等待5秒,要注意关键字的参数要使用 | 分隔)
Test Teardown指的就是案例结束的时候执行某个关键字。
Test Template:测试模版,这是可以指定某个关键字为这个测试套件下所有TestCase的模版,这样所有的TestCase就只需要设置这个关键字的传入参数即可。
Test Timeout:设置每一个测试案例的超时时间,只要超过这个时间就会失败,并停止案例运行。这是防止某些情况导致案例一直卡住不动,也不停止也不失败。
Force Tags:这里还是要说一下,在文件型Suite这里还可以继续给子元素增加Force Tags,但是他不能删除父元素设置的tags
Default Tags:默认标记,其实和Force Tags没啥区别的
Arguments:传入参数
Return Value:返回值
五.工作区RUN
Execution Profile:选择运行方式,里面有pybot、jybot和custom script。其中我们默认是用pybot来运行案例,jybot需要安装Jython的支持。custom script是选择自定义的脚本来运行。就目前而言,我们不用修改了,默认pybot即可
Start和Stop:这两个应该不用说了,运行和停止案例。
Report和Log: 报告和日志,要运行之后才能点击。他们的区别么,我的感觉是报告更多是结果上的展示,日志更多是过程的记录,更多使用的还是日志。
Autosave: 自动保存,如果不勾选,在修改了案例之后如果没有保存的话,运行案例时会提示是否保存。勾选则在运行时自动保存了。
Arguments: pybot的参数(或者jybot等),比如我后面截图里加上了一个参数。完整版的参数可以在doc命令行输入pybot.bat --help
Only Run Tests with these Tags: 只运行这些标记的测试案例。
Skip Tests with these Tags: 跳过这些标记的测试案例。
六.案例设计之流程与数据分离1
1.创建案例
这算是一个比较完整的案例了,包含完整的流程和检查点,那么这时候如果我要增加一个案例,搜索另外的内容怎么办呢?
在原来的case上修改肯定是不合适的,毕竟那个案例可能还是需要保留的。
最简单的办法,把这个case复制一个,修改搜索内容。那么我们复制出一个case2吧
2.分层方法
选中case中的所有脚本,点击右键,选择Extract Keyword
而我们再看case的内容就只有这个关键字了
新建一个Resource文件,把UserKeyword移动过去(或者移动到已有的Resource文件里)
这样做的目的是为了更清晰,在测试套件中一般不放置UserKeyword,前面第2讲的时候我们就说过了,首要建议UserKeyword放在Resource里。
我这里新建一个Resource,叫TestFlow.txt,然后把这个搜索测试移动过去,就成了这样。
接下来我们针对这个测试流程进行分离,因为这个案例流程比较简单,实际上就只有搜索内容这一个值是变化的,因此我们把他改成一个变量,同时把这个UserKeyword的参数加上这个变量。
再回头看看case的内容和添加内容
可以运行试试看
到现在我们完成了一个简单的分层,把搜索测试这个流程剥离成一个关键字,然后在不同的case调用这个关键字,然后传递不同的参数,用以进行不同数据在同一个流程下的测试。
这样就不用担心再新增10个或100个案例了,因为这个案例比较简单,通过复制也可以做出10个或100个案例,但是最大的区别在于,如果我的流程中间需要做一点小的调整和优化,对于流程和数据分离的案例来说,我这样维护一下搜索测试这个UserKeyword就行了;对于复制的案例,那你就要辛苦了,你有多少个案例就改多少吧。
其实这个道理引申出来,我们做自动化测试也是一样,选择不同的方法或者工具都可以实现最终的目标,但是我们需要考虑的不是把案例做起来,因为这个比较容易实现。对于自动化案例来说,最大的难度不是在于怎么做案例,而是怎么维护案例。因为随着需求的更新,系统的流程或者页面会发生很多的变化,这时候的维护成本的高低才是我们首要考虑的,如果自动化案例建立起来之后,没有后续维护的投入,最终经过若干个版本,这些自动化案例基本就是废弃的了。
七.案例设计之流程与数据分离1
将搜索测试中的内容继续分层,还是要把一些底层的代码级关键字继续拆分出来
下面对res1.txt进行操作
1.打开浏览器
2.输入搜索内容
3.点击搜索
4.校验标题
5.关闭浏览器
接着我们把对应的搜索测试中的代码都换成相应的关键字,记得添加参数${url}
最后该运行了
至此,我们这个案例就已经完成分层了,因为案例比较简单,所以只分了3层,分别是案例层,流程层,元素层。他们的调用关系也是逐层深入的

=============总结一下=============
这样做的好处不单是为了以后维护方便,也使得案例的架构层级清晰。越是靠近上层的部分,脚本越贴近自然语言,或者说很像我们的测试案例;越靠近下层的部分,越是接近页面元素的代码级部分。这样以后如果发生维护的时候,根据需要维护的内容,只需要在很少的地方进行调整即可。比如一个元素的id变了,那我只要在elements里面更新就行了。比如测试的流程调整了,以前是ABC的页面顺序,现在是ACB的页面顺序,那么只要在testflow层进行调整即可。
那么回到我们的标题,流程与数据分离,实际上目前我们的流程都集中在testflow以及下面的部分,而数据一般都是在案例层去给流程层传递,这就是我们的流程与数据分离了。当然,我们还可以再进一步的分离,把数据放到外面,脱离我们的案例,在运行的时候才传递进行,也是可以实现的。后面我会做个简单的例子给大家看。
Robot Framework分层、开发系统关键字的更多相关文章
- Robot Framework自动化测试(五)--- 开发系统关键字
最近一直在用robot framework 做自动化测试项目,老实说对于习惯直接使用python的情况下,被框在这个工具里各种不爽,当然,使用工具的好处也很多,降低了使用成本与难度:当然,在享受工具带 ...
- Robot Framework开发系统关键字详细
本文的目的,是记录如何在rf下,开发属于自己的库函数(又称之系统关键字) 1.首先在..\Python27\Lib\site-packages目录下创建自定义库目录如Verification_Libr ...
- robot framework 接口自动化测试和关键字开发
https://www.cnblogs.com/laoqing/p/10787593.html 1.实战-接口自动化测试实例 1.1 接口测试 接口测试通常是系统之间交互的接口,或者某个系统对外提供的 ...
- Robot Framework(AutoItLibrary库关键字介绍)
AutoItLibrary库关键字 AutoItLibrary 的对象操作大体上有几大主要部分,Window 操作.Control 操作.Mouse 操作.Process操作.Run 操作.Reg 操 ...
- robot framework 的AutoItLibrary常用关键字
1.run 的用法,以及激活当前窗口
- Robot Framework自动化测试(三)--- 封装系统关键字
之前对robotframework-ride了解的不多,后来知道了引入Selenium2Lirary库后可以做web UI自动化测试,但发现和python没啥关系,今天学习了封装系统关键字算是和pyt ...
- Robot Framework自动化测试(四)--- 分层思想
谈到Robot Framework 分层的思想,就不得不提“关键字驱动”. 关键字驱动: 通过调用的关键字不同,从而引起测试结果的不同. 在上一节的selenium API 中所介绍的方法其实就是关 ...
- Robot Framework学习笔记(十一)------ 分层设计
以百度搜索为例,如果我们需要写5个不同关键字搜索的用例.如果没有分层的思想,那么我们需要写5个用例,并且每个用例都需要重复写打开浏览器.输入关键字.点击按钮.关闭浏览器的步骤.如果使用Robot Fr ...
- Robot Framework自动化测试四(分层思想)
谈到Robot Framework 分层的思想,就不得不提“关键字驱动”. 关键字驱动: 通过调用的关键字不同,从而引起测试结果的不同. 在上一节的selenium API 中所介绍的方法其实就是关 ...
随机推荐
- ASP.NET学习笔记(3)——用户增删改查(三层)
说明(2017-10-6 11:21:58): 1. 十一放假在家也没写几行代码,本来还想着利用假期把asp.net看完,结果天天喝酒睡觉,回去的票也没买到,惨.. 2. 断断续续的把用户信息的页面写 ...
- 【.Net】Thread.Start()与ThreadPool.QueueUserWorkItem()的区别
百度搜到的靠前的几篇文章,都是写了两种API的使用实例,但并没有说清两者的具体差别. 直接上stackoverflow搜才是正确的姿势.(想上谷歌,然而十/九_大|期间VPN各种被墙,就很气) 参考: ...
- 【MarkdownPad】不能输入表格Table
使用MarkdownPad时,需要制作一个表格.搜到参照这篇文章,发现还是无法显示表格,测试效果是如下这样的: Markdown文本: 显示效果: 谷歌一下,原来是MarkdownPad默认的处理器不 ...
- PostgreSQL ALTER TABLE中改变数据类型时USING的用法<转>
在修改表字段类型的时候使用Using来进行显示的转换类型. 原文说明: SET DATA TYPE This form changes the type of a column of a table ...
- android——字符串string(转)
原文地址:http://www.open-open.com/lib/view/open1387942832078.html String : 字符串类型 一.构造函数 String(byte[ ...
- [开发笔记]-Linq to xml学习笔记
最近需要用到操作xml文档的方法,学习了一下linq to xml,特此记录. 测试代码: class Program { //参考: LINQ to XML 编程基础 - luckdv - 博客园 ...
- 115道Java经典面试题(面中率最高、最全)
115道Java经典面试题(面中率最高.最全) Java是一个支持并发.基于类和面向对象的计算机编程语言.下面列出了面向对象软件开发的优点: 代码开发模块化,更易维护和修改. 代码复用. 增强代码的可 ...
- elasticsearch之kibana安装
我用的elasticsearch版本是5.2.2的,kibana也要对应的版本 下载kibana 下载网址:https://artifacts.elastic.co/downloads/kibana/ ...
- Map与实体之间转换
package com.thunisoft.maybee.engine.utils; import java.lang.reflect.Field; import java.lang.reflect. ...
- ajax 多个参数问题,如何既能表单序列化获取,又能加参数,加全部代码
$.param({'address':address,'delivity':delivity,'payment':payment}) + '&' + $('#card_form').ser ...