有关python numpy pandas scipy 等 能在YARN集群上 运行PySpark
有关这个问题,似乎这个在某些时候,用python写好,且spark没有响应的算法支持, 能否能在YARN集群上 运行PySpark方式,
将python分析程序提交上去?
Spark Application可以直接运行在YARN集群上,这种运行模式,会将资源的管理与协调统一交给YARN集群去处理,这样能够实现构建于YARN集群之上Application的多样性,比如可以运行MapReduc程序,可以运行HBase集群,也可以运行Storm集群,还可以运行使用Python开发机器学习应用程序,等等。
我们知道,Spark on YARN又分为client模式和cluster模式:在client模式下,Spark Application运行的Driver会在提交程序的节点上,而该节点可能是YARN集群内部节点,也可能不是,一般来说提交Spark Application的客户端节点不是YARN集群内部的节点,那么在客户端节点上可以根据自己的需要安装各种需要的软件和环境,以支撑Spark Application正常运行。在cluster模式下,Spark Application运行时的所有进程都在YARN集群的NodeManager节点上,而且具体在哪些NodeManager上运行是由YARN的调度策略所决定的。
对比这两种模式,最关键的是Spark Application运行时Driver所在的节点不同,而且,如果想要对Driver所在节点的运行环境进行配置,区别很大,但这对于PySpark Application运行来说是非常关键的。
PySpark是Spark为使用Python程序编写Spark Application而实现的客户端库,通过PySpark也可以编写Spark Application并在Spark集群上运行。Python具有非常丰富的科学计算、机器学习处理库,如numpy、pandas、scipy等等。为了能够充分利用这些高效的Python模块,很多机器学习程序都会使用Python实现,同时也希望能够在Spark集群上运行。
PySpark Application运行原理
理解PySpark Application的运行原理,有助于我们使用Python编写Spark Application,并能够对PySpark Application进行各种调优。PySpark构建于Spark的Java API之上,数据在Python脚本里面进行处理,而在JVM中缓存和Shuffle数据,数据处理流程如下图所示(来自Apache Spark Wiki):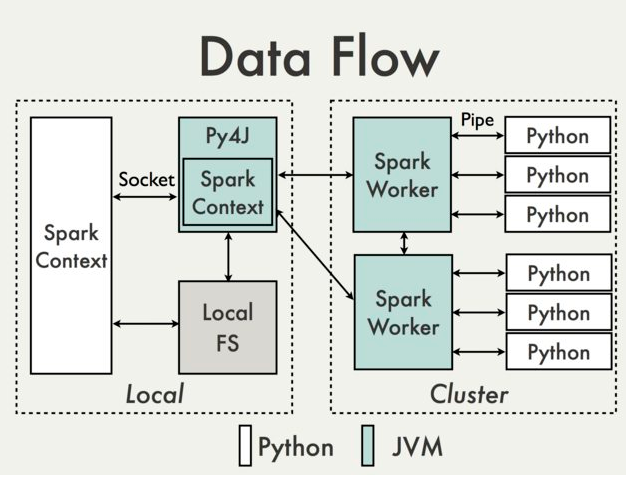
Spark Application会在Driver中创建pyspark.SparkContext对象,后续通过pyspark.SparkContext对象来构建Job DAG并提交DAG运行。使用Python编写PySpark Application,在Python编写的Driver中也有一个pyspark.SparkContext对象,该pyspark.SparkContext对象会通过Py4J模块启动一个JVM实例,创建一个JavaSparkContext对象。PY4J只用在Driver上,后续在Python程序与JavaSparkContext对象之间的通信,都会通过PY4J模块来实现,而且都是本地通信。
PySpark Application中也有RDD,对Python RDD的Transformation操作,都会被映射到Java中的PythonRDD对象上。对于远程节点上的Python RDD操作,Java PythonRDD对象会创建一个Python子进程,并基于Pipe的方式与该Python子进程通信,将用户编写Python处理代码和数据发送到Python子进程中进行处理。
下面,我们基于Spark on YARN模式,并根据当前企业所具有的实际集群运行环境情况,来说明如何在Spark集群上运行PySpark Application,大致分为如下3种情况:
- YARN集群配置Python环境
这种情况,如果是初始安装YARN、Spark集群,并考虑到了当前应用场景需要支持Python程序运行在Spark集群之上,这时可以准备好对应Python软件包、依赖模块,在YARN集群中的每个节点上进行安装。这样,YARN集群的每个NodeManager上都具有Python环境,可以编写PySpark Application并在集群上运行。目前比较流行的是直接安装Python虚拟环境,使用Anaconda等软件,可以极大地简化Python环境的管理工作。
这种方式的缺点是,如果后续使用Python编写Spark Application,需要增加新的依赖模块,那么就需要在YARN集群的每个节点上都进行该新增模块的安装。而且,如果依赖Python的版本,可能还需要管理不同版本Python环境。因为提交PySpark Application运行,具体在哪些NodeManager上运行该Application,是由YARN的调度器决定的,必须保证每个NodeManager上都具有Python环境(基础环境+依赖模块)。
- YARN集群不配置Python环境
这种情况,更适合企业已经安装了规模较大的YARN集群,并在开始使用时并未考虑到后续会使用基于Python来编写Spark Application,并且不想在YARN集群的NodeManager上安装Python基础环境及其依赖模块。我们参考了Benjamin Zaitlen的博文(详见后面参考链接),并基于Anaconda软件环境进行了实践和验证,具体实现思路如下所示:
- 在任意一个Linux OS的节点上,安装Anaconda软件
- 通过Anaconda创建虚拟Python环境
- 在创建好的Python环境中下载安装依赖的Python模块
- 将整个Python环境打成zip包
- 提交PySpark Application时,并通过
--archives选项指定zip包路径
下面进行详细说明:
首先,我们在CentOS 7.2上,基于Python 2.7,下载了Anaconda2-5.0.0.1-Linux-x86_64.sh安装软件,并进行了安装。Anaconda的安装路径为/root/anaconda2。
然后,创建一个Python虚拟环境,执行如下命令:
|
1
|
conda create -n mlpy_env --copy -y -q python=2 numpy pandas scipy |
上述命令创建了一个名称为mlpy_env的Python环境,--copy选项将对应的软件包都安装到该环境中,包括一些C的动态链接库文件。同时,下载numpy、pandas、scipy这三个依赖模块到该环境中。
接着,将该Python环境打包,执行如下命令:
|
1
2
|
cd /root/anaconda2/envszip -r mlpy_env.zip mlpy_env |
该zip文件大概有400MB左右,将该zip压缩包拷贝到指定目录中,方便后续提交PySpark Application:
|
1
|
cp mlpy_env.zip /tmp/ |
最后,我们可以提交我们的PySpark Application,执行如下命令:
|
1
2
3
4
5
|
PYSPARK_PYTHON=./ANACONDA/mlpy_env/bin/python spark-submit \ --conf spark.yarn.appMasterEnv.PYSPARK_PYTHON=./ANACONDA/mlpy_env/bin/python \ --master yarn-cluster \ --archives /tmp/mlpy_env.zip#ANACONDA \ /var/lib/hadoop-hdfs/pyspark/test_pyspark_dependencies.py |
上面的test_pyspark_dependencies.py文件中,使用了numpy、pandas、scipy这三个依赖包的函数,通过上面提到的YARN集群的cluster模式可以运行在Spark集群上。
可以看到,上面的依赖zip压缩包将整个Python的运行环境都包含在里面,在提交PySpark Application时会将该环境zip包上传到运行Application的所在的每个节点上,并解压缩后为Python代码提供运行时环境。如果不想每次都从客户端将该环境文件上传到集群中运行PySpark Application的节点上,也可以将zip包上传到HDFS上,并修改--archives参数的值为hdfs:///tmp/mlpy_env.zip#ANACONDA,也是可以的。
另外,需要说明的是,如果我们开发的/var/lib/hadoop-hdfs/pyspark/test_pyspark_dependencies.py文件中,也依赖的一些我们自己实现的处理函数,具有多个Python依赖的文件,想要通过上面的方式运行,必须将这些依赖的Python文件拷贝到我们创建的环境中,对应的目录为mlpy_env/lib/python2.7/site-packages/下面。
- 基于混合编程语言环境
假如我们还是希望使用Spark on YARN模式来运行PySpark Application,但并不将Python程序提交到YARN集群上运行。这时,我们可以考虑使用混合编程语言的方式,来处理数据任务。比如,机器学习Application具有迭代计算的特性,更适合在一个高配的节点上运行;而普通的ETL数据处理具有多机并行处理的特点,适合放到集群上进行分布式处理。
一个完整的机器学习Application的设计与构建,可以将算法部分和数据准备部分分离出来,使用Scala/Java进行数据预处理,输出一个机器学习算法所需要(更便于迭代、寻优计算)的输入数据格式,这会极大地压缩算法输入数据的规模,从而使算法迭代计算充分利用单机本地的资源(内存、CPU、网络),这可能会比直接放到集群中计算要快得多。
因此,我们在对机器学习Application准备数据时,使用原生的Scala编程语言实现Spark Application来处理数据,包括转换、统计、压缩等等,将满足算法输入格式的数据输出到HDFS指定目录中。在性能方面,对数据规模较大的情况下,在Spark集群上处理数据,Scala/Java实现的Spark Application运行性能要好一些。然后,算法迭代部分,基于丰富、高性能的Python科学计算模块,使用Python语言实现,其实直接使用PySpark API实现一个机器学习PySpark Application,运行模式为YARN client模式。这时,就需要在算法运行的节点上安装好Python环境及其依赖模块(而不需要在YARN集群的节点上安装),Driver程序从HDFS中读取输入数据(缓存到本地),然后在本地进行算法的迭代计算,最后输出模型。
总结
对于重度使用PySpark的情况,比如偏向机器学习,可以考虑在整个集群中都安装好Python环境,并根据不同的需要进行依赖模块的统一管理,能够=极大地方便PySpark Application的运行。
不在YARN集群上安装Python环境的方案,会使提交的Python环境zip包在YARN集群中传输带来一定开销,而且每次提交一个PySpark Application都需要打包一个环境zip文件,如果有大量的Python实现的PySpark Application需要在Spark集群上运行,开销会越来越大。另外,如果PySpark应用程序修改,可能需要重新打包环境。但是这样做确实不在需要考虑YARN集群集群节点上的Python环境了,任何版本Python编写的PySpark Application都可以使用集群资源运行。
关于该问题,SPARK-13587(详见下面参考链接)也在讨论如果优化该问题,后续应该会有一个比较合适的解决方案。
参考链接
- https://cwiki.apache.org/confluence/display/SPARK/PySpark+Internals
- https://issues.apache.org/jira/browse/SPARK-13587
- http://quasiben.github.io/blog/2016/4/15/conda-spark/
- https://blog.cloudera.com/blog/2017/04/use-your-favorite-python-library-on-pyspark-cluster-with-cloudera-data-science-workbench/
- https://repo.continuum.io/pkgs/misc/parcels/archive/
- https://repo.continuum.io/pkgs/misc/parcels/
- https://www.cloudera.com/documentation/enterprise/5-5-x/topics/spark_python.html
- https://docs.anaconda.com/anaconda/user-guide/tasks/integration/cloudera
- http://shiyanjun.cn/archives/1738.html
有关python numpy pandas scipy 等 能在YARN集群上 运行PySpark的更多相关文章
- 用python + hadoop streaming 编写分布式程序(二) -- 在集群上运行与监控
写在前面 相关随笔: Hadoop-1.0.4集群搭建笔记 用python + hadoop streaming 编写分布式程序(一) -- 原理介绍,样例程序与本地调试 用python + hado ...
- linux下安装numpy,pandas,scipy,matplotlib,scikit-learn
python在数据科学方面需要用到的库: a.Numpy:科学计算库.提供矩阵运算的库. b.Pandas:数据分析处理库 c.scipy:数值计算库.提供数值积分和常微分方程组求解算法.提供了一个非 ...
- 用C、python手写redis客户端,兼容redis集群 (-MOVED和-ASK),快速搭建redis集群
想没想过,自己写一个redis客户端,是不是很难呢? 其实,并不是特别难. 首先,要知道redis服务端用的通信协议,建议直接去官网看,博客啥的其实也是从官网摘抄的,或者从其他博客抄的(忽略). 协议 ...
- Python: NumPy, Pandas学习资料
NumPy 学习资料 书籍 NumPy Cookbook_[Idris2012] NumPy Beginner's Guide,3rd_[Idris2015] Python数据分析基础教程:NumPy ...
- 在python中使用zookeeper管理你的应用集群
http://www.zlovezl.cn/articles/40/ 简介: Zookeeper 分布式服务框架是 Apache Hadoop 的一个子项目,它主要是用来解决分布式应用中经常遇到的一些 ...
- 统计学(检验、分布)的 python(numpy/pandas/scipy) 实现
scipy 中统计相关的 api:https://docs.scipy.org/doc/scipy/reference/stats.html https://zhuanlan.zhihu.com/p/ ...
- Python Numpy,Pandas基础笔记
Numpy Numpy是python的一个库.支持维度数组与矩阵计算并提供大量的数学函数库. arr = np.array([[1.2,1.3,1.4],[1.5,1.6,1.7]])#创建ndarr ...
- python numpy+mkl+scipy win64 安装
用pip在windows下安装numpy,scipy等库时一般来说都不会很顺利比较好的方式是自己下载对应的whl文件pip install 话不多说上链接 http://www.lfd.uci.edu ...
- python/numpy/pandas数据操作知识与技巧
pandas针对dataframe各种操作技巧集合: filtering: 一般地,使用df.column > xx将会产生一个只有boolean值的series,以该series作为dataf ...
随机推荐
- 检测ASP.NET是否是调试模式
在web.config里,可以设置debug为true或者false <system.web> <compilation debug="false" target ...
- jQuery的deferred对象详解 jquery回调函数
http://www.ruanyifeng.com/blog/2011/08/a_detailed_explanation_of_jquery_deferred_object.html jQuery的 ...
- Windows8、Windows8.1使用便签工具
Windows8.8.1没有了小工具,但是很多小工具实际上还是存在的,便签就是常用的小工具之一,既然系统自带就不用在安装第三方的了,使用方法: 启动或显示 Sticky Notes : Win+R-- ...
- 回顾 Exchange 2007 SCC 安装-供需要的人参考!
最近可能会涉及到一个项目的升级,客户目前是基于SCC+SCR的一种工作模式,因为之前对SCR 了解很少,所以需要搭建一个SCC+SCR 平台来做一个整体的POC,来还原整个安装和升级过程. 首先我们先 ...
- Sharepoint2013 Report Service初探
首先需要建立相应的report报表 如图: 这里的sql如下: SELECT PC.Name AS Category, PS.Name AS Subcategory, DATEPART(yy, SOH ...
- VS2010整合NUnit进行单元测试
1.下载安装NUnit(最新win版本为NUnit-2.6.0.12051.msi) http://www.nunit.org/index.php?p=download 2.下载并安装VS的Visua ...
- 在springboot项目中使用mybatis 集成 Sharding-JDBC
前段时间写了篇如何使用Sharding-JDBC进行分库分表的例子,相信能够感受到Sharding-JDBC的强大了,而且使用配置都非常干净.官方支持的功能还包括读写分离.分布式主键.强制路由等.这里 ...
- uva 10712 - Count the Numbers(数位dp)
题目链接:uva 10712 - Count the Numbers 题目大意:给出n,a.b.问说在a到b之间有多少个n. 解题思路:数位dp.dp[i][j][x][y]表示第i位为j的时候.x是 ...
- 【Java】Java-正则匹配-性能优化
Java-正则匹配-性能优化 Java 正则 点_百度搜索 在Java类中如何用正则表达式表示小数点啊?_百度知道 使用Jakarta-ORO库的几个例子 - 小橡树 - ITeye博客 正则表达式以 ...
- webkit-user-select:none 问题
webkit-user-select:none 问题 学习了:https://bugs.webkit.org/show_bug.cgi?id=82692 最近两天做移动端游戏举报页面.遇到一个问题,移 ...