retrival and clustering : week 3 k-means 笔记
华盛顿大学 machine learning 笔记。
K-means algorithm
算法步骤:
0. 初始化几个聚类中心 (cluster centers)μ1,μ2, … , μk

1. 将所有数据点分配给最近的聚类中心;
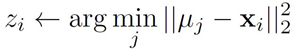
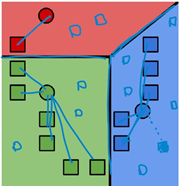
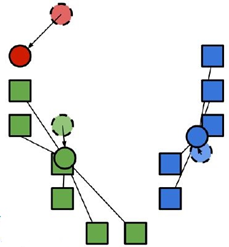
2. 将每个聚类中心的值改成分配到该点所有数据点的均值;
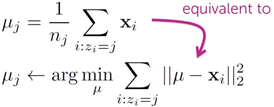
3. 重复1-2步骤,直到收敛到局部最优(local optimium).
#输入:
#数据集 data
#集群数 k
#初始集群中心组 initial_centroids
#最多循环次数 maxiter
#输出:
#集群中心组 centroids
#数据点分配情况 cluster_assignment
def kmeans(data, k, initial_centroids, maxiter):
centroids = initial_centroids[:]
prev_cluster_assignment = None for itr in xrange(maxiter): # 计算各数据点到各个centroid的距离
distances_from_centroids = pairwise_distances(data, centroids, metric='euclidean')
# 将数据点分配到各个centroid
cluster_assignment = np.argmin(distances_from_centroids, axis = 1) # 将每个centroid的值改成分配到该点的所有数据点的均值
new_centroids = []
for i in xrange(k):
member_data_points = data[cluster_assignment == i]
centroid = member_data_points.mean(axis = 0)
# 格式转换
centroid = centroid.A1
new_centroids.append(centroid)
new_centroids = np.array(new_centroids)
centroids = new_centroids # 判断是否收敛到局部最优
if prev_cluster_assignment is not None and \
(prev_cluster_assignment==cluster_assignment).all():
break prev_cluster_assignment = cluster_assignment[:] return centroids, cluster_assignment
问题1: 算法结果为局部最优,受初始化选择的聚类中心影响很大,如何初始化?
k-means ++:
1.第一个聚类中心从随机点中随机选择。
2.对于每个数据点,计算到最近集群中心的距离。
3.从数据点中选择新的集群中心,数据点选择概率与它离最近的集群中心的距离成比例(使centroids之间离得越远越好)。
4.重复步骤2和3,直到k个中心全被选中。
特点:
随机初始化计算成本相对较高,但随后通常会更迅速地收敛,局部最优质量更高,运行时间短。
def smart_initialize(data, k):
# k-means++ 方法 得到初始的centroids组
centroids = np.zeros((k, data.shape[1])) # 随机选择第一个centroid
idx = np.random.randint(data.shape[0])
centroids[0] = data[idx,:].toarray() # 计算其他数据点到第一个centroid的距离
squared_distances = pairwise_distances(data, centroids[0:1], metric='euclidean').flatten()**2 # 选择接下来的 k-1 个centroids
# 每个数据点被选中的概率与它离最近的centroid的距离成比例(即使得centroids之间离得越远越好)
for i in xrange(1, k):
idx = np.random.choice(data.shape[0], 1, p=squared_distances/sum(squared_distances))
centroids[i] = data[idx,:].toarray()
# 更新每个数据点离已选择的centroids的距离
squared_distances = np.min(pairwise_distances(data, centroids[0:i+1], metric='euclidean')**2,axis=1) return centroids
问题2:如何评价聚类算法结果的质量?
两种聚类方法,第二种更符合我们对聚类算法的预期,如何评估聚类的结果?
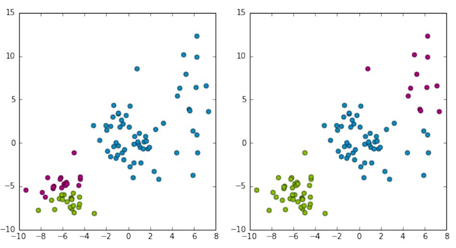
最小化距离的平方和:
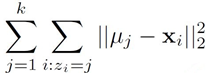
问题3: 如何选择合适的k?
随着k的增加,聚类算法的异质性(heterogeneity)会降低。
heterogeneity 表达式:

方法一:拐点法
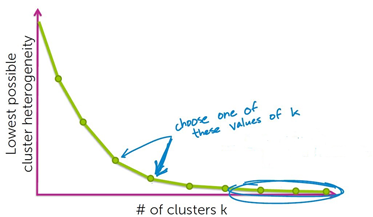
选取拐点处的k值。
方法二:均方根: 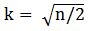 (n个数据点)
(n个数据点)
retrival and clustering : week 3 k-means 笔记的更多相关文章
- retrival and clustering : week 4 GMM & EM 笔记
华盛顿大学 机器学习 笔记. k-means的局限性 k-means 是一种硬分类(hard assignment)方法,例如对于文档分类问题,k-means会精确地指定某一文档归类到某一个主题,但很 ...
- retrival and clustering: week 2 knn & LSH 笔记
华盛顿大学 <机器学习> 笔记. knn k-nearest-neighbors : k近邻法 给定一个 数据集,对于查询的实例,在数据集中找到与这个实例最邻近的k个实例,然后再根据k个最 ...
- KNN 与 K - Means 算法比较
KNN K-Means 1.分类算法 聚类算法 2.监督学习 非监督学习 3.数据类型:喂给它的数据集是带label的数据,已经是完全正确的数据 喂给它的数据集是无label的数据,是杂乱无章的,经过 ...
- C程序设计语言(K&R)笔记
1.表达式中float类型的操作数不会自动转换为double类型.一般来说,数学函数(如math.h)使用双精度类型的变量.使用float类型主要是为了在使用较大数组时节省存储空间,有时也为了节省机器 ...
- 软件——机器学习与Python,聚类,K——means
K-means是一种聚类算法: 这里运用k-means进行31个城市的分类 城市的数据保存在city.txt文件中,内容如下: BJ,2959.19,730.79,749.41,513.34,467. ...
- [DL学习笔记]从人工神经网络到卷积神经网络_1_神经网络和BP算法
前言:这只是我的一个学习笔记,里边肯定有不少错误,还希望有大神能帮帮找找,由于是从小白的视角来看问题的,所以对于初学者或多或少会有点帮助吧. 1:人工全连接神经网络和BP算法 <1>:人工 ...
- 【机器学习笔记之一】深入浅出学习K-Means算法
摘要:在数据挖掘中,K-Means算法是一种 cluster analysis 的算法,其主要是来计算数据聚集的算法,主要通过不断地取离种子点最近均值的算法. 在数据挖掘中,K-Means算法是一种c ...
- kmeans笔记
1.算法过程 a.随机选取k个初始点作为中心点 b.依次计算剩余所有点分别与哪个初始点距离较近,则该点属于哪个簇 c.移动中心点到现在的簇的中心 d.重复b,c两步,直到中心点不再变化算法结束 2.优 ...
- 机器学习10—K-均值聚类学习笔记
机器学习实战之K-Means算法 test10.py #-*- coding:utf-8 import sys sys.path.append("kMeans.py") impor ...
随机推荐
- es6 对象简化写法-函数
表达式还可以用于定义方法名. let obj = { ['h' + 'ello']() { return 'hi'; } }; obj.hello() // hi
- 伪分布模式安装hadoop
准备工具: 虚拟机:VMware Linux系统:CentOS hadoop-1.1.2.tar.gz jdk-7u75-linux-x64.gz CentOS的网络配置 1.设置主机中VMware ...
- 【FinancialKnowledge】拨备
一句话: 银行拨备就是银行贷款损失减值准备的俗称,其相当于为承担风险和损失的金融资产计提的准备金 通俗易懂的解释见:https://wallstreetcn.com/articles/3307725
- 【Linux】通过传入变量进行数学运算
一个简单的sum求和 #! /bin/bash ## For get the sum of tow numbers ## Writen by Qinys ## Date:2018-06-26 a=1 ...
- 【DB2】NULLS LAST与NULLS FIRST
DB2函数配合 select row_number() over(order by col desc nulls first/nulls last ) as rn,col from table1ord ...
- struts.xml 文件添加DTD文件
在编辑struts.xml 文件时,“alt + /”无提示信息,需要在myeclipse 中添加消息头中的文件,步骤如下: 1. 选中该段复制 2. Preferences——>XML Cat ...
- Codeigniter 使用 Mysql 存储过程
本篇文章由:http://xinpure.com/codeigniter-using-mysql-stored-procedures/ 执行存储过程 $query = $this -> db - ...
- c++ builder xe2 debug正常 release崩溃 解决一例
今天修改了以前一个项目的代码,是一个exe程序 C++ builder xe2 编译.以前都是好的.今天改了一下版本号 编译了一下,居然不能用了.直接崩溃 提示内存非法访问.而且显然还没有进入Win ...
- thinkphp 3.2多语言设置
1.将CheckLangBehavior.class.php(没有的话去下载完整版)文件放到此目录下:\ThinkPHP\Extend\Behavior 2.修改目录下文件Application\Ho ...
- Solr3.6.2和Solr4.9.0经常使用配置
tomcat 以tomcat 7为例,位置/work/apache-tomcat-7.0.55 Solr 3.6.2 基本配置 Solr 3.6.2.须要JDK 6/JDK7支持. 下载Solr 3. ...