kafka topic制定规则
kafka topic的制定,我们要考虑的问题有很多,比如生产环境中用几备份、partition数目多少合适、用几台机器支撑数据量,这些方面如何去考量?笔者根据实际的维护经验,写一些思考,希望大家指正。
1.replicas数目
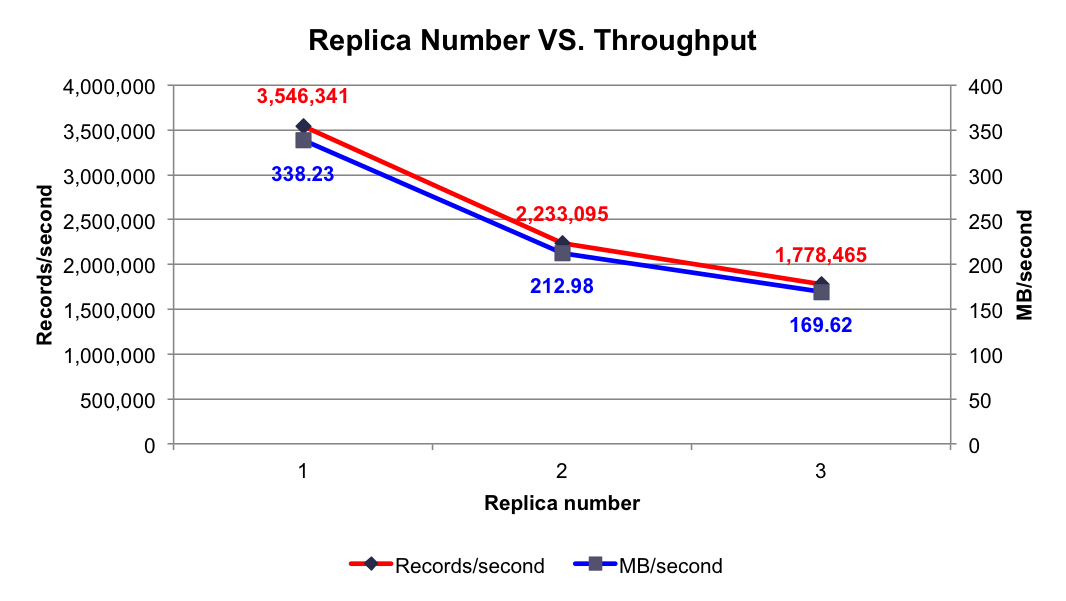
可以从上图看到,备份越多,性能越低,因为kafka的写入只写入主分区,备份相当于消费者从主分区pull数据,这样势必会造成性能的损耗,故建议在生产环境中使用一主一备即可。
2. partition数量
(1)设置partition数量的时候我们需要注意:kafka的partition可以在创建时候指定,也可以alter(kafka-topic.sh里面的参数),但是,这个修改只能增加partition数目,并不能减少。这带来的直接影响就是我们在设置按照日志数量回滚数据的时候(即:设置log.retention.bytes控制日志清除),需要考虑大小,因为log.retention.bytes设置的是partition的日志大小。
(2)partition的数目并不是越多越好,以下是笔者所做的性能测试。
//todo
可以看到,当partition数目是broker数目的整数倍的时候,它的TPS较高,非整数倍的时候,由于数据不均衡,所以TPS会有不同程度的影响。
3.消费速度
消费速度需要进行性能测试做相应评估,消费者/生产者加机器,都可以带来性能的线性增加。
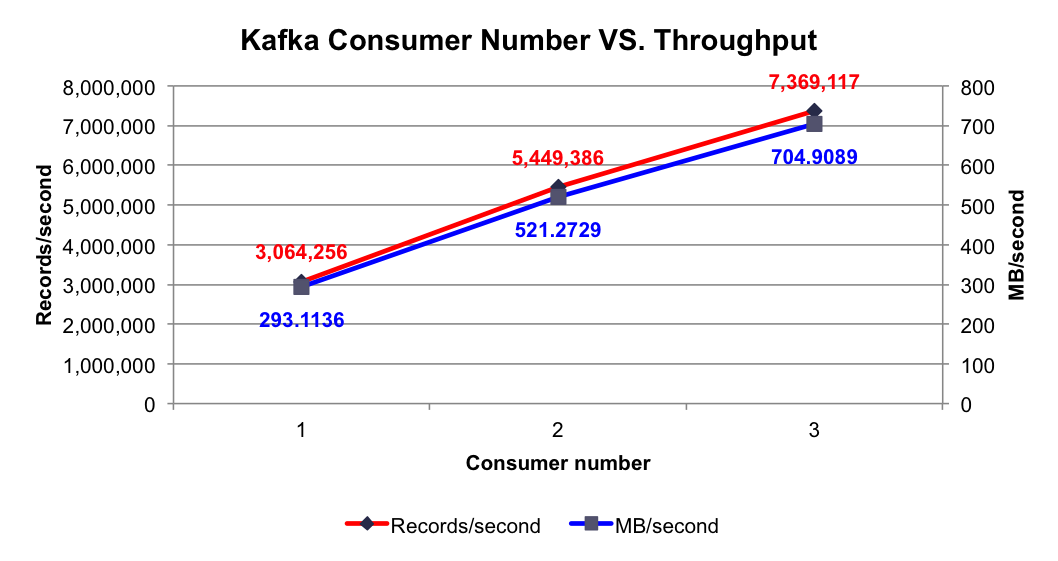
4.制定规则
综上考虑,笔者在生产环境中的实践规则如下:
- Partition数量=broker数量*2[这个作为预先设置,设置小一点,如果线上机器不够,增加机器的话,同时topic也会增加2,增量不要设置太大]
- partition数量需要大于consumer数量
- partition数量过多会给consumer带来额外的开销,建议consumer线程数(消费者个数)设置为partition数目,或略小于即可。
- broker数量 =目标吞吐量/max(producer吞吐量,consumer吞吐量)
5.reference
How to choose the number of topics/partitions in a Kafka cluster?
关注我的技术公众号,第一时间获取新鲜技术文章:

kafka topic制定规则的更多相关文章
- Kafka Topic Partition Replica Assignment实现原理及资源隔离方案
本文共分为三个部分: Kafka Topic创建方式 Kafka Topic Partitions Assignment实现原理 Kafka资源隔离方案 1. Kafka Topic创建方式 ...
- Exception in thread "main" org.I0Itec.zkclient.exception.ZkAuthFailedException: Authentication failure is thrown while creating kafka topic
Exception in thread "main" org.I0Itec.zkclient.exception.ZkAuthFailedException: Authentica ...
- 用canal同步binlog到kafka,spark streaming消费kafka topic乱码问题
canal 1.1.1版本之后, 默认支持将canal server接收到的binlog数据直接投递到MQ, 目前默认支持的MQ系统有kafka和RocketMQ. 在投递的时候我们使用的是非压平的消 ...
- Kafka Topic Api
Pom: <dependency> <groupId>org.apache.kafka</groupId> <artifactId>kafka_2.10 ...
- [Flume][Kafka]Flume 与 Kakfa结合例子(Kakfa 作为flume 的sink 输出到 Kafka topic)
Flume 与 Kakfa结合例子(Kakfa 作为flume 的sink 输出到 Kafka topic) 进行准备工作: $sudo mkdir -p /flume/web_spooldir$su ...
- 手动删除Kafka Topic
一.删除Kafka topic 运行./bin/kafka-topics --delete --zookeeper [zookeeper server] --topic [topic name]: ...
- kafka topic 完全删除
kafka topic 完全删除 1.自动删除脚本(得配置server.properties 中 delete.topic.enable=true) ./kafka-topics.sh --zoo ...
- Using KafkaBolt to write to a kafka topic
https://community.hortonworks.com/questions/27187/using-kafkabolt-to-write-to-a-kafka-topic.html --- ...
- kafka topic查看删除
1,查看kafka topic列表,使用--list参数 >bin/kafka-topics.sh --zookeeper 127.0.0.1:2181 --list __consumer_of ...
随机推荐
- Grunt实例
module.exports = function(grunt) { // 项目配置 grunt.initConfig({ pkg: grunt.file.readJSON('package.json ...
- vue 数组重复,循环报错
Vue.js默认不支持往数组中加入重复的数据.可以使用track-by="$index"来实现.
- 29_Future模式2_JDK内置实现
[Future使用场景] Future表示一个可能未完成的一部任务的结果,针对这个结果可以添加CallBack,以便在任务执行成功或失败后作出相应的操作. Future模式非常适合在处理耗时很长的业务 ...
- Python爬虫教程-13-爬虫使用cookie爬取登录后的页面(人人网)(下)
Python爬虫教程-13-爬虫使用cookie爬取登录后的页面(下) 自动使用cookie的方法,告别手动拷贝cookie http模块包含一些关于cookie的模块,通过他们我们可以自动的使用co ...
- Visual Studio Code调试electron主进程
Visual Studio Code调试electron主进程 作者: jekkay 分类: electron 发布时间: 2017-06-11 14:56 一·概述 此文原出自[水滴石]: htt ...
- python SQLAchemy常用语法
SQLAlchemy是Python编程语言下的一款ORM框架,该框架建立在数据库API之上,使用关系对象映射进行数据库操作,简言之便是:将对象转换成SQL,然后使用数据API执行SQL并获取执行结果. ...
- C#获取apk版本信息
获取很多人都会问我为什么要写这个博客,原因很简单,这次研发apk版本信息的时候网上查了很多的资料都没有这方面的信息,因此这次功能完了想写下方法,如果以后博友们遇到了可以直接copy,不用花很多的时间, ...
- Thinkphp中在本地测试很好,在服务器上出错,有可能是因为debug缓存的问题
define('APP_DEBUG',false); 这个设置从true改为false后,一定要清空缓存,否则会出错.
- SVNKit学习——基于Repository的操作之print repository tree、file content、repository history(四)
此篇文章同样是参考SVNKit在wiki的官方文档做的demo,每个类都可以单独运行.具体的细节都写到注释里了~ 开发背景: SVNKit版本:1.7.14 附上官网下载链接:https://www. ...
- css如何制作八边形
随着技术的发展,css也越发强大,css可以制作很多有趣的图形,让我们一起来看一下如何使用css制作一个八边形吧. 方法/步骤 1新建一个html文件.如图: 在html文件上创建一个 ...