SpringBoot2.0+ElasticSearch网盘搜索实现
1、ES是如何实现分布式高并发全文检索
2、简单介绍ES分片Shards分片技术
3、为什么ES主分片对应的备分片不在同一台节点存放
4、索引的主分片定义好后为什么不能做修改
5、ES如何实现高可用容错方案
6、搭建Linux上环境三台ES高可用集群环境
7、基于ES网盘搜索引擎实现
网盘搜索引擎,写个Job 去网上爬虫 存储起来 以JSON的格式 存放在 ES服务器
网盘搜索引擎的原理:
采用ES存储抓取的数据 抓取服务器
测试数据:
##先创建索引 PUT /clouddisk ##测试数据maping POST /clouddisk/_mapping/disk
{
"disk":{
"properties":{
"name":{
"type":"text",
"analyzer":"ik_smart",
"search_analyzer":"ik_smart"
},
"source":{
"type":"keyword"
},
"describe":{
"type":"text",
"analyzer":"ik_smart",
"search_analyzer":"ik_smart"
},
"shartime":{
"type":"date"
},
"browsetimes":{
"type":"long"
},
"filesize":{
"type":"float"
},
"sharpeople":{
"type":"keyword"
},
"collectiontime":{
"type":"date"
},
"baiduaddres":{
"type":"keyword"
}
}
} } POST /clouddisk/disk
{
"name": "2018史上最全美剧",
"source": "百度云盘",
"describe": "该课程由小明提供",
"shartime": "2018-10-10",
"browsetimes": 100000,
"filesize": 4.35,
"sharpeople": "美国东部",
"collectiontime": "2018-11-24",
"baiduaddres": "https://pan.baidu.com/s/1VQxFq6JnKh0KP-5aMq-WpA#list/path=%2F" } POST /clouddisk/disk
{
"name": "2018史上最全韩剧",
"source": "百度云盘",
"describe": "该课程小丽提供",
"shartime": "2018-10-12",
"browsetimes": 100000,
"filesize": 6.35,
"sharpeople": "韩国釜山",
"collectiontime": "2018-11-24",
"baiduaddres": "https://pan.baidu.com/s/1VQxFq6JnKh0KP-5aMq-WpA#list/path=%2F" } POST /clouddisk/disk
{
"name": "老友记",
"source": "百度云盘",
"describe": "该课程由张三提供",
"shartime": "2018-10-10",
"browsetimes": 100000,
"filesize": 1.35,
"sharpeople": "美国",
"collectiontime": "2018-11-24",
"baiduaddres": "https://pan.baidu.com/s/1VQxFq6JnKh0KP-5aMq-WpA#list/path=%2F" } POST /clouddisk/disk
{
"name": "英语雅思",
"source": "百度云盘",
"describe": "该课程由大海提供",
"shartime": "2018-10-10",
"browsetimes": 100000,
"filesize": 1.35,
"sharpeople": "大海",
"collectiontime": "2018-11-24",
"baiduaddres": "https://pan.baidu.com/s/1VQxFq6JnKh0KP-5aMq-WpA#list/path=%2F" } POST /clouddisk/disk
{
"name": "小猪佩奇",
"source": "百度云盘",
"describe": "该课程由朱佩琦出品",
"shartime": "2018-10-10",
"browsetimes": 100000,
"filesize": 1.35,
"sharpeople": "佩奇",
"collectiontime": "2018-11-24",
"baiduaddres": "https://pan.baidu.com/s/1VQxFq6JnKh0KP-5aMq-WpA#list/path=%2F" }
maven:
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>com.toov5</groupId>
<artifactId>springboot-esPan</artifactId>
<version>0.0.1-SNAPSHOT</version> <parent>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-parent</artifactId>
<version>2.0.0.RELEASE</version>
<relativePath /> <!-- lookup parent from repository -->
</parent>
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-elasticsearch</artifactId>
</dependency>
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
</dependency> <dependency>
<groupId>com.google.collections</groupId>
<artifactId>google-collections</artifactId>
<version>1.0-rc2</version>
</dependency>
<!-- springboot整合freemarker -->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-freemarker</artifactId>
</dependency> </dependencies> </project>
Dao:
package com.toov5.dao;
import org.springframework.data.elasticsearch.repository.ElasticsearchRepository;
import com.toov5.entity.CloudDiskEntity;
public interface CloudDiskDao extends ElasticsearchRepository<CloudDiskEntity, String> {
}
Entity:
package com.toov5.entity; import org.springframework.data.annotation.Id;
import org.springframework.data.elasticsearch.annotations.Document; import lombok.Data; @Data
@Document(indexName = "clouddisk", type = "disk")
public class CloudDiskEntity { @Id
private String id;
// 名称
private String name;
// 来源
private String source;
// 描述
private String describe;
// 分享时间
private String shartime;
// 浏览次数
private Long browsetimes;
// 文件大小
private Double filesize;
// 分享人
private String sharpeople;
// 收录时间
private String collectiontime;
// 地址
private String baiduaddres; }
Controller:
package com.toov5.controller; import java.util.List;
import java.util.Optional; import org.apache.commons.lang.StringUtils;
import org.elasticsearch.index.query.BoolQueryBuilder;
import org.elasticsearch.index.query.MatchQueryBuilder;
import org.elasticsearch.index.query.QueryBuilders;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.web.bind.annotation.PathVariable;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RestController; import com.google.common.collect.Lists;
import com.toov5.dao.CloudDiskDao;
import com.toov5.entity.CloudDiskEntity; //SpringBoot 整合 ES @RestController
public class CloudDiskController {
@Autowired
private CloudDiskDao cloudDiskDao; @RequestMapping("/findById/{id}")
public Optional<CloudDiskEntity> findById(@PathVariable String id) {
Optional<CloudDiskEntity> findById = cloudDiskDao.findById(id);
return findById;
}
@RequestMapping("/search")
public List<CloudDiskEntity> search(String keyWord,String describe) {
//创建查询 查询所有的
BoolQueryBuilder boolQuery = QueryBuilders.boolQuery(); //创建查询
if (!StringUtils.isEmpty(keyWord)) {
//模糊查询 一定要用ik的中文分词插件!
MatchQueryBuilder matchQuery = QueryBuilders.matchQuery("name", keyWord);
boolQuery.must(matchQuery);
}
if (!StringUtils.isEmpty(describe)) {
//模糊查询 一定要用ik的中文分词插件!
MatchQueryBuilder matchQuery = QueryBuilders.matchQuery("describe", describe);
boolQuery.must(matchQuery);
} Iterable<CloudDiskEntity> search = cloudDiskDao.search(boolQuery); //查询所有的数据
return Lists.newArrayList(search); //通过这个api可以进行转换 //这样查询除了所有的 然后添加match
}
}
yml:
spring:
data:
elasticsearch:
####集群名称
cluster-name: myes
####地址
cluster-nodes: 192.168.91.7:9300
freemarker:
# 设置模板后缀名
suffix: .ftl
# 设置文档类型
content-type: text/html
# 设置页面编码格式
charset: UTF-8
# 设置页面缓存
cache: false
# 设置ftl文件路径
template-loader-path:
- classpath:/templates
# 设置静态文件路径,js,css等
mvc:
static-path-pattern: /static/**
启动类:
package com.toov5; import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;
import org.springframework.data.elasticsearch.repository.config.EnableElasticsearchRepositories; @SpringBootApplication
@EnableElasticsearchRepositories(basePackages="com.toov5.dao") //dao 代码没有@Component的情况下可以这么玩儿 而且这样比较节省代码哈哈
public class AppEs {
public static void main(String[] args) {
SpringApplication.run(AppEs.class, args);
}
}
关键字查询时候,可以进行关键字查询,比like强悍!
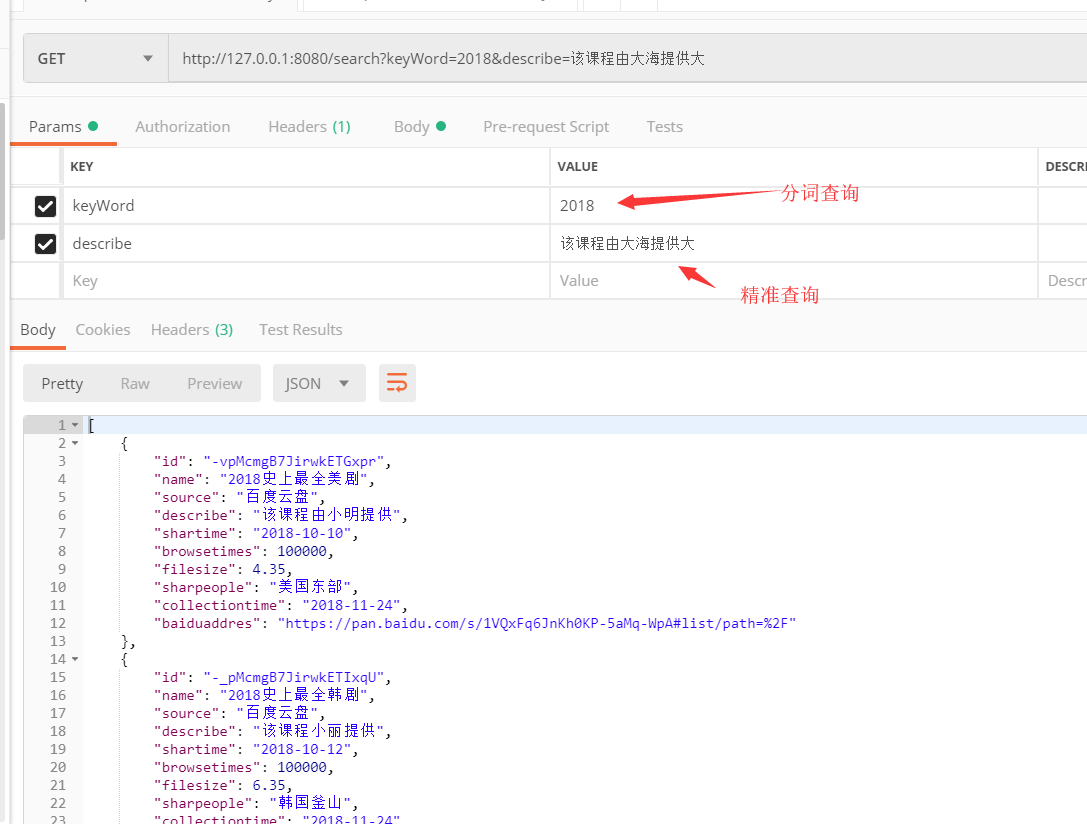
分页查询: 很简单 传入参数 Pageable 就OK了 封装好了
GET /clouddisk/disk/_search
{
"from": 0,
"size":2,
"query": {
"match": {
"name": "2018"
}
} }
page= 0 ,请求页数从0开始 2代表size 每一页代表多少条数据
前端传来参数是第几页
package com.toov5.controller; import java.util.List;
import java.util.Optional; import org.apache.commons.lang.StringUtils;
import org.elasticsearch.index.query.BoolQueryBuilder;
import org.elasticsearch.index.query.MatchQueryBuilder;
import org.elasticsearch.index.query.QueryBuilders;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.data.domain.Page;
import org.springframework.data.domain.Pageable;
import org.springframework.data.web.PageableDefault;
import org.springframework.web.bind.annotation.PathVariable;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RestController; import com.toov5.dao.CloudDiskDao;
import com.toov5.entity.CloudDiskEntity; //SpringBoot 整合 ES @RestController
public class CloudDiskController {
@Autowired
private CloudDiskDao cloudDiskDao; @RequestMapping("/findById/{id}")
public Optional<CloudDiskEntity> findById(@PathVariable String id) {
Optional<CloudDiskEntity> findById = cloudDiskDao.findById(id);
return findById;
}
@RequestMapping("/search") //写死了 默认值
public Page<CloudDiskEntity> search(String keyWord,@PageableDefault(page=0,value=1) Pageable pageable) {
//创建查询 查询所有的
BoolQueryBuilder boolQuery = QueryBuilders.boolQuery(); //创建查询
if (!StringUtils.isEmpty(keyWord)) {
//模糊查询 一定要用ik的中文分词插件!
MatchQueryBuilder matchQuery = QueryBuilders.matchQuery("name", keyWord);
boolQuery.must(matchQuery);
} Page<CloudDiskEntity> search = cloudDiskDao.search(boolQuery,pageable);
return search;
}
}
访问:
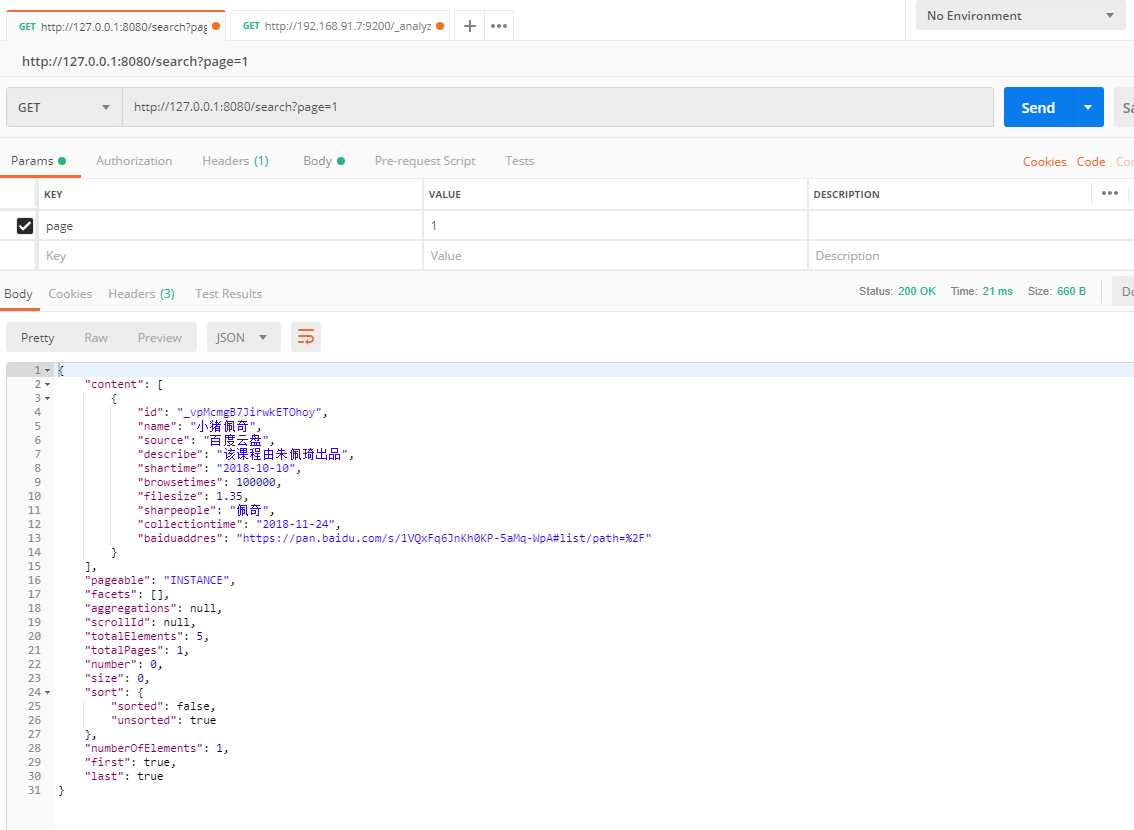
也可以传入 页数 size数
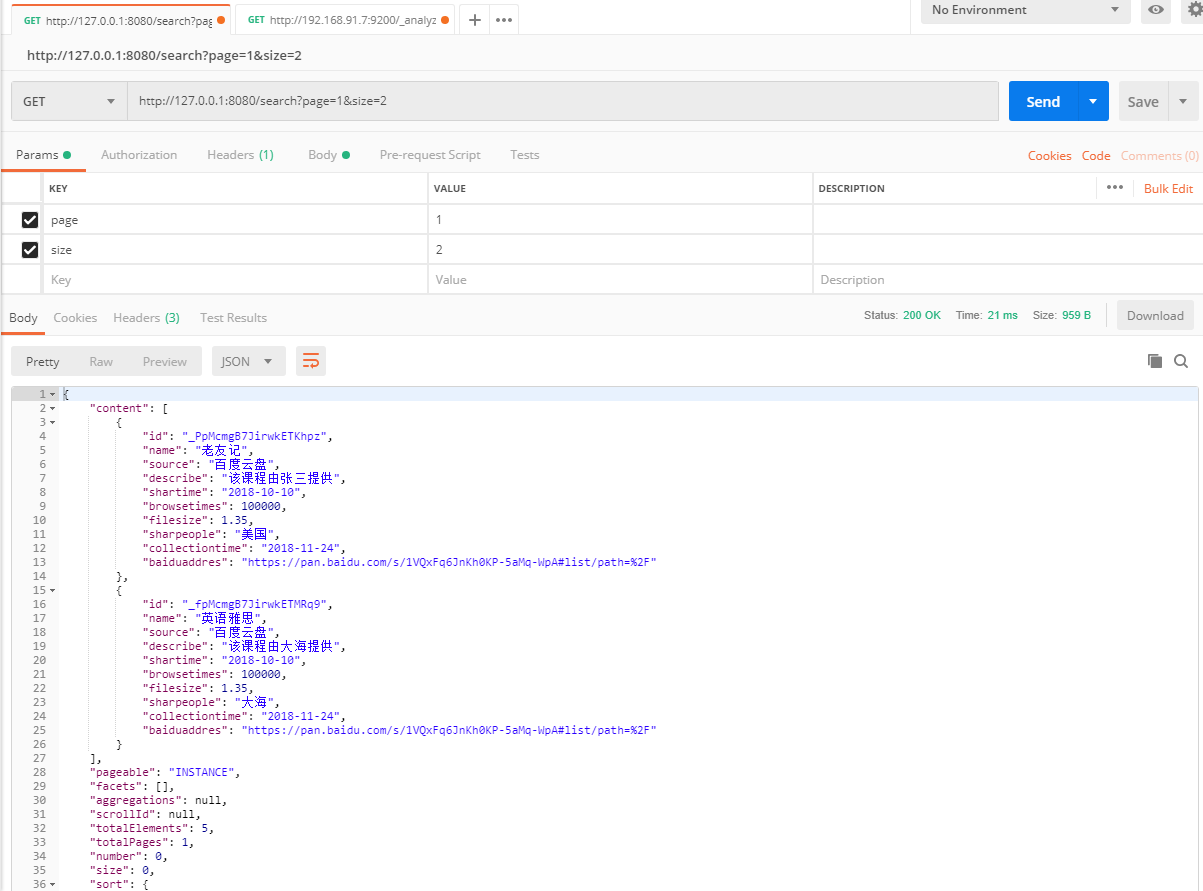
整合到前端展示:
Controller:
package com.toov5.controller; import javax.servlet.http.HttpServletRequest; import org.apache.commons.lang.StringUtils;
import org.elasticsearch.index.query.BoolQueryBuilder;
import org.elasticsearch.index.query.MatchQueryBuilder;
import org.elasticsearch.index.query.QueryBuilders;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.data.domain.Page;
import org.springframework.data.domain.Pageable;
import org.springframework.data.web.PageableDefault;
import org.springframework.stereotype.Controller;
import org.springframework.web.bind.annotation.RequestMapping; import com.toov5.dao.CloudDiskDao;
import com.toov5.entity.CloudDiskEntity; @Controller
public class PageController {
@Autowired
private CloudDiskDao cloudDiskDao; @RequestMapping("/search") //写死了 默认值
public String search(String keyWord,@PageableDefault(page=0,value=2) Pageable pageable, HttpServletRequest req) {
Long starTime = System.currentTimeMillis();
//创建查询 查询所有的
BoolQueryBuilder boolQuery = QueryBuilders.boolQuery(); //创建查询
if (!StringUtils.isEmpty(keyWord)) {
//模糊查询 一定要用ik的中文分词插件!
MatchQueryBuilder matchQuery = QueryBuilders.matchQuery("name", keyWord);
boolQuery.must(matchQuery);
} Page<CloudDiskEntity> page = cloudDiskDao.search(boolQuery,pageable);
req.setAttribute("page", page);
req.setAttribute("total", page.getTotalElements());
req.setAttribute("keyword", keyWord);
Long endTime = System.currentTimeMillis();
req.setAttribute("time", endTime-starTime );
return "search";
}
}
页面展示:
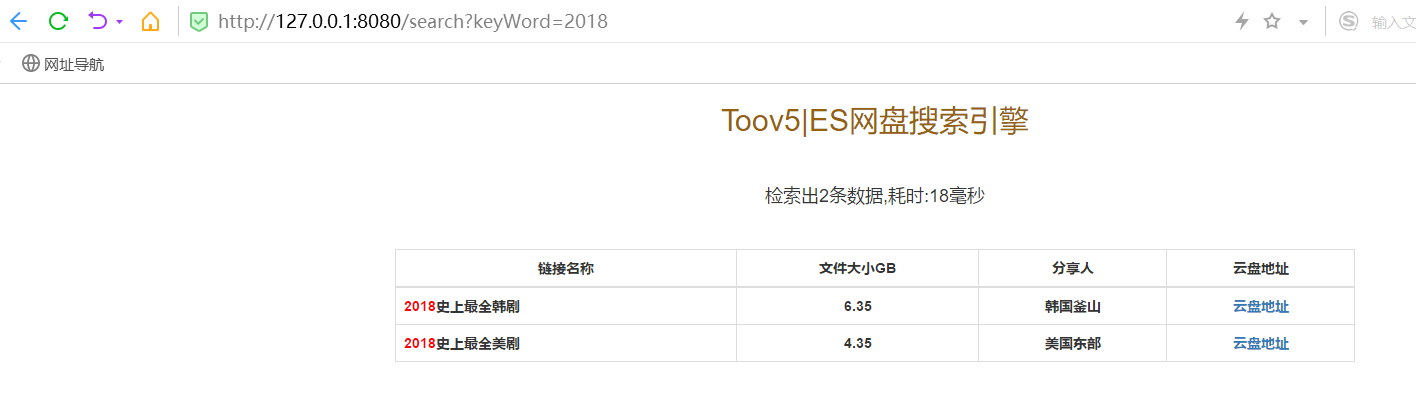

页面:
<!DOCTYPE html>
<html xmlns="http://www.w3.org/1999/xhtml" xmlns:th="http://www.thymeleaf.org">
<head>
<meta charset="UTF-8">
<title>Toov5|ES网盘搜索引擎</title>
<!-- 新 Bootstrap 核心 CSS 文件 --> <link href="https://cdn.bootcss.com/bootstrap/3.3.7/css/bootstrap.min.css" rel="stylesheet"> <!-- 可选的Bootstrap主题文件(一般不使用) --> <script src="https://cdn.bootcss.com/bootstrap/3.3.7/css/bootstrap-theme.min.css"></script> <!-- jQuery文件。务必在bootstrap.min.js 之前引入 --> <script src="https://cdn.bootcss.com/jquery/2.1.1/jquery.min.js"></script> <!-- 最新的 Bootstrap 核心 JavaScript 文件 --> <script src="https://cdn.bootcss.com/bootstrap/3.3.7/js/bootstrap.min.js"></script> </head>
<body style="display: block; margin: 0 auto; width: 50%; " >
<div style="width:100%;height:60px;" align="center">
<h2 style="color:#985f0d;">Toov5|ES网盘搜索引擎</h2>
</div>
<br/>
<div align="center">
<span style="font-size: 18px;" >检索出${total}条数据,耗时:${time}毫秒</span>
</div>
<br/>
<br/>
<div class="bs-example" data-example-id="striped-table">
<table class="table table-bordered table-hover">
<thead>
<tr>
<th style="text-align:center;" scope="row">链接名称</th>
<th style="text-align:center;">文件大小GB</th>
<th style="text-align:center;">分享人</th>
<th style="text-align:center;">云盘地址</th>
</tr>
</thead>
<tbody>
<#list page.content as p>
<tr >
<th style="text-align: left;" >
<#if keyword??>
${p.name?replace(keyword, '<span style="color: red">${keyword}</span>')}
<#else>
${p.name}
</#if> </th>
<th style="text-align: center;">${p.filesize}</th>
<th style="text-align: center;">${p.sharpeople}</th>
<th style="text-align: center;"><a href="${p.baiduaddres}">云盘地址</a> </th>
</tr>
</#list>
</tbody>
</table>
<!-- <div style="font-size: 21px;">
<#list 1..totalPage as i>
<#if keyword??>
<a href="/search?keyword=${keyword}&page=${i-1}" >${i}</a>
<#else>
<a href="/search?page=${i-1}" >${i}</a>
</#if> </#list> 页
</div> --> </div>
</body>
</html>
分页展示数据:
package com.toov5.controller; import javax.servlet.http.HttpServletRequest; import org.apache.commons.lang.StringUtils;
import org.elasticsearch.index.query.BoolQueryBuilder;
import org.elasticsearch.index.query.MatchQueryBuilder;
import org.elasticsearch.index.query.QueryBuilders;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.data.domain.Page;
import org.springframework.data.domain.Pageable;
import org.springframework.data.web.PageableDefault;
import org.springframework.stereotype.Controller;
import org.springframework.web.bind.annotation.RequestMapping; import com.toov5.dao.CloudDiskDao;
import com.toov5.entity.CloudDiskEntity; @Controller
public class PageController {
@Autowired
private CloudDiskDao cloudDiskDao; @RequestMapping("/search") //写死了 默认值
public String search(String keyWord,@PageableDefault(page=0,value=2) Pageable pageable, HttpServletRequest req) {
Long starTime = System.currentTimeMillis();
//创建查询 查询所有的
BoolQueryBuilder boolQuery = QueryBuilders.boolQuery(); //创建查询
if (!StringUtils.isEmpty(keyWord)) {
//模糊查询 一定要用ik的中文分词插件!
MatchQueryBuilder matchQuery = QueryBuilders.matchQuery("name", keyWord);
boolQuery.must(matchQuery);
} Page<CloudDiskEntity> page = cloudDiskDao.search(boolQuery,pageable);
// 计算查询总数
long total = page.getTotalElements();
req.setAttribute("total", page.getTotalElements());
// 计算分页数
int totalPage = (int) ((total - 1) / pageable.getPageSize() + 1);
req.setAttribute("totalPage", totalPage);
req.setAttribute("page", page);
req.setAttribute("total", page.getTotalElements());
req.setAttribute("keyword", keyWord);
Long endTime = System.currentTimeMillis();
req.setAttribute("time", endTime-starTime );
return "search";
}
}
效果:
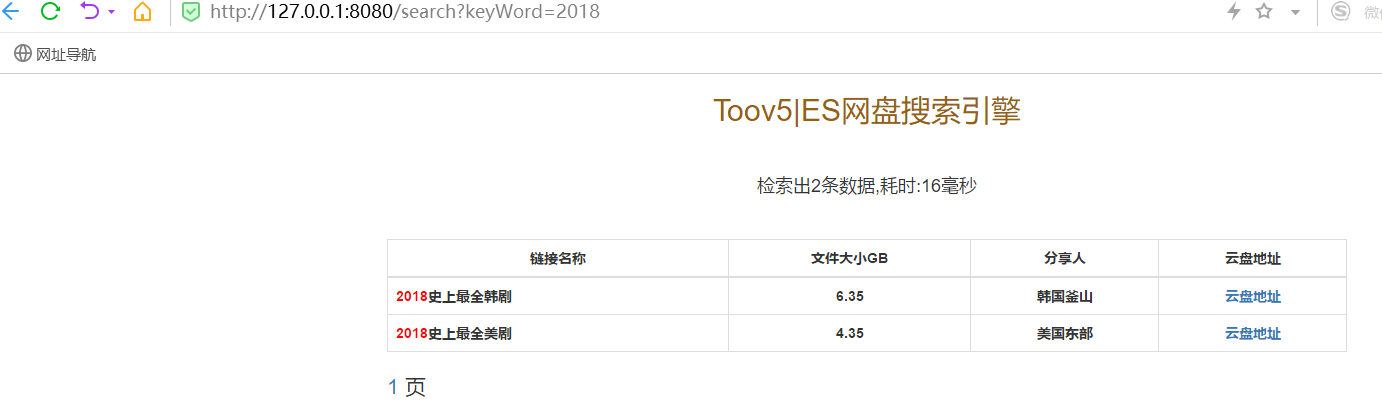
SpringBoot2.0+ElasticSearch网盘搜索实现的更多相关文章
- [PHP] 网盘搜索引擎-采集爬取百度网盘分享文件实现网盘搜索
标题起的太大了,都是骗人的.最近使用PHP实现了简单的网盘搜索程序,并且关联了微信公众平台.用户可以通过公众号输入关键字,公众号会返回相应的网盘下载地址.就是这么一个简单的功能,类似很多的网盘搜索类网 ...
- [C#]使用Windows Form开发的百度网盘搜索工具
BaiduDiskSearcher 用C#编写的百度网盘搜索工具(.NET4.0 & Visual Studio 2017) 功能 1.搜索任意名称的百度网盘共享文件 2.可以左键双击打开网盘 ...
- C#制作网盘搜索工具(简单的爬虫)
最近学习C#编程,在网上发现一篇winform下制作百度网盘搜索器的文章,故而下载源码学习一二.无奈原博所用的网址失效,故而自己改写了网址和相关源代码,也进行了实现.因为初学,接触的知识较多,为免忘记 ...
- 推荐一个百度网盘搜索工具www.sososo.me
推荐一个百度网盘搜索工具 http://www.sososo.me
- 利用jsoup爬取百度网盘资源分享连接(多线程)
突然有一天就想说能不能用某种方法把百度网盘上分享的资源连接抓取下来,于是就动手了.知乎上有人说过最好的方法就是http://pan.baidu.com/wap抓取,一看果然链接后面的uk值是一串数字, ...
- C# 学习之路--百度网盘爬虫设计与实现(一)
百度网盘爬虫 现在市面上出现了很多网盘搜索引擎,写这系列博文及爬虫程序的初衷: 更方面的查找资源 学习C# 学习爬虫的设计与实现 记录学习历程 自我监督 能力有限,如有不妥之处,还请各位看官点评.同在 ...
- PJzhang:百度网盘是如何泄露公司机密的?
猫宁!!! 参考链接:https://mp.weixin.qq.com/s/PLELMu8cVleOLlwRAAYPVg 百度网盘在中国一家独大,百度超级会员具有很多特权,尤其是在下载速度上,是普通会 ...
- 可在广域网部署运行的QQ高仿版 -- GG叽叽V2.0,增加网盘和远程磁盘功能(源码)
尽力2~3周发布一个版本,我这次也没有失言.这段时间内,我仿照QQ的微云功能,在GG中增加了网盘的功能,而且,我还自创了一个QQ没有的新的功能:远程磁盘.正如远程桌面一样,远程磁盘允许我们像访问本地磁 ...
- 私人网盘系统2.0—全部升级为layUI+PHP(持续更新中)shang
网盘系统2.0 上周,我做了第一版的“私人网盘系统”,http://www.cnblogs.com/sunlizheng/p/7822036.html 没看过的朋友可以去看一下,这周在家升级做了第 ...
随机推荐
- Centos 虚拟机网络问题,网卡起不来,重启network服务失败
拷贝了个虚拟机,有两个网卡,1个可以起来,另一个起不来.运行命令:$>systemctl restart network 输出如下:Job for network.service failed ...
- iOS捕获异常,常用的异常处理方法
本文转载至 http://www.cocoachina.com/ios/20141229/10787.html 前言:在开发APP时,我们通常都会需要捕获异常,防止应用程序突然的崩溃,防止给予用户不友 ...
- DotNet软件开发框架
这是我4月份发在donews博客上的文章,现在都转到博客园来,风满袖希望进一步阐述你的架构,我就将这篇文章转移到博客园.原文:http://blog.donews.com/shanyou/archiv ...
- Win10下Hyper-V设置网络连接
具体方法如下. 1.点击虚拟交换机管理 2.创建虚拟交换机 选择内部 3.选择链接类型
- tsinsen A1333. 矩阵乘法
题目链接:传送门 题目思路:整体二分(二分的是答案,附带的是操作) 把矩阵中的元素对应成插入操作,然后就有插入和询问操作. 然后根据插入操作对于答案的影响,询问操作所匹配的符合答案个数,将操作分为两段 ...
- java was started but returned exit code=1
将eclipse.ini文件删掉, 重启eclipse 会自动生成一个eclipse.ini就可以了~
- git base 简单命令行
记录几个简单的命令 1:克隆-把线上的文件复制到本地 git clone 线上地址 2:检查状态 git status 3:放入待仓储 git add.文件名 git add * (全部文件,简单粗暴 ...
- Spoken English Practice(If you fail to do as I say, I will take you suffer.)
绿色:连读: 红色:略读: 蓝色:浊化: 橙色:弱读 下划线_为浊化 口语蜕变(2017/6/29) ...
- google-java-format
https://github.com/google/google-java-format
- MQ中间件对比