Oracle递归查询与常用分析函数
最近学习oracle的一些知识,发现自己sql还是很薄弱,需要继续学习,现在总结一下哈。
(1)oracle递归查询 start with ... connect by prior ,至于是否向上查询(根节点)还是向下查询(叶节点),主要看prior后面跟的字段是否是父ID。
向上查询:select * from test_tree_demo start with id=1 connect by prior pid=id
查询结果:

向下查询:select * from test_tree_demo start with id=3 connect by prior id=pid

如果要进行过滤,where条件不能放在connect by 后面,如下:select * from test_tree_demo where id !=4 start with id=1 connect by prior pid=id

(2)分析函数- over( partition by )
数据库中的数据如下:select * from testemp1

select deptno,ename,sal,sum(sal)over() deptsum from testemp1 如果over中不加任何条件,就相当于sum(sal),显示结果如下:

一般over都是配合partition by order by 一起使用,partition by 就是分组的意思。下面看个例子:按部门分组,同个部门根据姓名进行工资累计求和。
select deptno,ename,sal,sum(sal)over(partition by deptno order by ename) deptsum from testemp1,显示如下:

其实统计各个部门的薪水总和,可以使用group by实现,select deptno,sum(sal) deptsum from testemp1 group by deptno,结果如下:

但是,使用group by 的时候查询出来的字段必须是分组的字段或者聚合函数。例如查询结果多加个ename字段。使用partition by 就简单了。
select deptno,ename,sum(sal) over (partition by deptno) from testemp1,显示如下:

(3)分析函数-rank(),dense_rank(),row_number()
select deptno,ename,sal,rank() over(partition by deptno order by sal) from testemp1,结果如下:

select deptno,ename,sal,dense_rank() over(partition by deptno order by sal) from testemp1,结果如下:

可以看出使用rank()和dense_rank()的区别了吧。接下来在看看row_number()
select deptno,ename,sal,row_number() over(partition by deptno order by sal desc) from testemp1,显示结果如下:
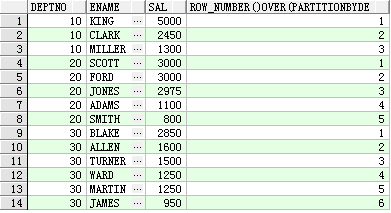
(4)分析函数-group by rollup
根据部门分组,统计各个部门各个职位的薪水总和。
select group_id,job,sum(salary) as salary from group_test group by rollup (group_id,job),显示结果如下:

group by rollup (a,b,c)相当于group by (a,b,c) union group by(a,b) union group by (a) union 全表。
上述结果可以用group by 与 union实现,如下:order by 1 ,2 就是根据第一二列进行排序
select group_id, job, sum(salary) from group_test group by group_id, job
union all
select group_id, null, sum(salary) from group_test group by group_id
union all
select null, null, sum(salary) from group_test
order by 1, 2;
可以结合grouping()函数一起使用,如下:
select group_id,case when grouping(group_id) = 0 and grouping(job) = 1 then '小计'
when grouping(group_id) = 1 and grouping(job) = 1 then '总计'
else job end as job,
sum(salary) as salary
from group_test
group by rollup(group_id, job);
显示如下:当grouping()为空的时候返回1,非空返回0.

(5)分析函数-group by cube
group by cube(a,b)=group by(a,b) union group by (a) union group by (b) union (全表)
select group_id,job,sum(salary) as salary from group_test group by cube (group_id,job),显示如下:

上述结果可以用group by 与 union实现,如下:
select group_id, job, sum(salary) from group_test group by group_id, job
union all
select group_id, null, sum(salary) from group_test group by group_id
union all
select null, job, sum(salary) from group_test group by job
union all
select null, null, sum(salary) from group_test
order by 1, 2;
(5)merge into
最近接触到oracle这个函数,感觉挺好的。假如我们现在有两个表A,B,其中有部分数据是A ,B表一样的,有一部分数据是B有的,而A表没有的,现在有一个需求,将两个表整合在一个表中。那么按照之前,我们一般都是根据A表某个唯一的字段查询B表,如果存在,则跳过,不存在则插入到A表。要实现这个需求,我们需要两步才能实现,如果使用merge into 则方便很多了。
merge into的结构如下:
MERGE INTO table_name alias1
USING (table|view|sub_query) alias2
ON (join condition)
WHEN MATCHED THEN
UPDATE table_name
SET col1 = col_val1,
col2 = col_val2
WHEN NOT MATCHED THEN
INSERT (column_list) VALUES (column_values);
下面我们看一个简单的例子: A表:group_test B表:testemp1
A表的数据如下: B表的数据如下:
B表的数据如下:
现在将B中deptno为50的数据插入到A表,如下:
merge into group_test t1
using (select * from testemp1 where deptno = 50) t2
on (t1.group_id = t2.deptno)
when matched then
update set t1.salary = 1000
when not matched then
insert (group_id, job,name,salary) values (t2.deptno,t2.ename,'gdpuzxs',5000)
显示如下: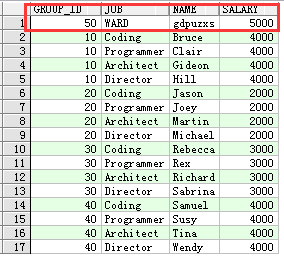 因为A表中没有group_id=50,所以执行插入。
因为A表中没有group_id=50,所以执行插入。
接着,我们在执行一下上面那个语句,
显示如下: 因为A表中存在group_id=50,所以执行更新操作。
因为A表中存在group_id=50,所以执行更新操作。
Oracle递归查询与常用分析函数的更多相关文章
- 【转载】Oracle递归查询:使用prior实现树操作【本文出自叶德华博客】
本文标题:Oracle递归查询:使用prior实现树操作 本文链接:http://yedward.net/?id=41 本文版权归作者所有,欢迎转载,转载请以文字链接的形式注明文章出处. Oracle ...
- Oracle SQL高级编程——分析函数(窗口函数)全面讲解
Oracle SQL高级编程--分析函数(窗口函数)全面讲解 注:本文来源于:<Oracle SQL高级编程--分析函数(窗口函数)全面讲解> 概述 分析函数是以一定的方法在一个与当前行相 ...
- 【2016-11-7】【坚持学习】【Day22】【Oracle 递归查询】
直接在oracle 递归查询语句 select * from groups start with id=:DeptId connect by prior superiorid =id 往下找 sele ...
- Oracle DBA 的常用Unix参考手册(一)
作为一名Oracle DBA,在所难免要接触Unix,但是Unix本身又是极其复杂的,想要深刻掌握同样很不容易.那么到底我们该怎么入手呢?Donald K Burleson 的<Unix for ...
- oracle rac 数据库常用命令
oracle rac 数据库常用命令:1.所有实例和服务的状态srvclt status database -d orcl单个实例的状态:srvctl status instance -d orcl ...
- Oracle表的常用查询实验(一)
Oracle表的常用查询实验(一) 练习1.请查询表DEPT中所有部门的情况. select * from dept; 练习2.查询表DEPT中的部门号.部门名称两个字段的所有信息. select d ...
- Oracle EBS DBA常用SQL - 安装/补丁【Z】
Oracle EBS DBA常用SQL - 安装/补丁 检查应用补丁有没有安装:select bug_number,last_update_date from ad_bugs where bug_nu ...
- Oracle递归查询start with connect by prior
一.基本语法 connect by递归查询基本语法是: select 1 from 表格 start with ... connect by prior id = pId start with:表示以 ...
- Oracle递归查询,Oracle START WITH……CONNECT BY查询
Oracle递归查询,Oracle START WITH……CONNECT BY查询,Oracle树查询 ================================ ©Copyright 蕃薯耀 ...
随机推荐
- Jenkins publish over ssh 路劲配置问题 记录
每次通过jenkins 实现 maven项目编辑后 自动通过 ssh发布到 服务器的功能时,对配置的路劲有疑问,特整理出来 前提:服务器路径 /home/ubuntu/aps 目标: 构建后的j ...
- 同时调整lv分区的大小(减少一个,增加另一个)
author:headsen chen date: 2018-04-20 16:48:06 1.查看分区:/home 为67G,太大了,/ 是50g,太小了. [root@localhost ~]# ...
- 【BZOJ2324】[ZJOI2011]营救皮卡丘 有上下界费用流
[BZOJ2324][ZJOI2011]营救皮卡丘 Description 皮卡丘被火箭队用邪恶的计谋抢走了!这三个坏家伙还给小智留下了赤果果的挑衅!为了皮卡丘,也为了正义,小智和他的朋友们义不容辞的 ...
- String 转 List<Map<String, Object>>
public static List<Map<String, Object>> toListMap(String json){ List<Object> list ...
- ASP.Net请求处理机制初步探索之旅 - Part 2 核心(转)
开篇:上一篇我们了解了一个请求从客户端发出到服务端接收并转到ASP.Net处理入口的过程,这篇我们开始探索ASP.Net的核心处理部分,借助强大的反编译工具,我们会看到几个熟悉又陌生的名词(类):Ht ...
- wget -d --header
wget -d --header="Host:www.sina.com" http://202.108.33.84 domain differ ip 防止Wget递归下载 假设Ng ...
- Spring 框架的JDBC模板技术
1. 概述 Spring 框架提供了很多持久层的模板类来简化编程; Spring 框架提供的JDBC模板类: JdbcTemplate 类; Spring 框架提供的整合 Hibernate 框架的模 ...
- JS练习--自动生成100个li
点击按钮,自动生成100个li,红.黄.蓝.绿四种颜色的顺序显示出现在页面中 CSS: ;;} ul,li{list-style: none;} #ul1{position: relative;} # ...
- 全球第一张中文网络协议分析图——By 成都科来软件
网上内容比较全面的网络协议图并不是很多,这些网络协议图大多只遵循OSI,对于TCP/IP基本不支持,有些协议图表示也不够准确.另一方面,现在网上能找到的协议图全都是英文版本,使用起来不是很方便.国内的 ...
- Android开发之事件和事件监听器
写了一个打飞机的小程序,用于作为事件监听的学习,此程序须要有实体按键的手机才干运行. PlaneView.java: public class PlaneView extends View{ publ ...