SQL 备忘录
都兼容 MySQL
查看表结构:DESC ${table_name}
查看建表语句:SHOW CREATE TABLE ${table_name}
表增加列:ALTER TABLE ${table_name} ADD COLUMN ${copumn_name} ${COLUMN_TYPE} NOT NULL;
表修改列:ALTER TABLE ${table_name} CHANGE COLUMN ${column_old_name} ${column_new_name} ${COLUMN_TYPE} NOT NULL;
删除列:ALTER TABLE ${table_name} DROP COLUMN ${column_name}
主键要能唯一标识一条记录
创建列值唯一约束:ALTER TABLE ${table_name} ADD CONSTRAINT ${unique_constraint_name} UNIQUE (${column_name});
外键会一定程度降低性能
创建外键:ALTER TABLE ${table_nane} ADD CONSTRAINT ${foreign_key_name} FOREIGN KEY (${column_name}) REFERENCES ${other_table} (${other_table_column});
删除外键:ALTER TABLE ${table_name} DROP FOREIGN KEY ${foreign_key_name};
索引对列值预排序所以加快查减慢增删改
创建普通索引:ALTER TABLE ${table_name} ADD INDEX ${index_name} (${column_name1}, ${column_name2});
创建唯一索引(索引列值有唯一性):ALTER TABLE ${table_name} ADD UNIQUE INDEX ${unique_index_name} (${column_name});
SELECT 语句:SELECT ${TRANSACTION_FUNCTION} ${transaction_result_alias}, ${column_name1} ${column_alias}, ${column_name2} FROM ${table_name} WHERE ${</=/>/<>/<=/>=/ LIKE/()/NOT/AND/OR_column} ORDER BY ${column_name3} DESC ${column_name4} ASC LIMIT ${result_count} OFFSET ${start_number} GROUP BY ${column_name}; LIKE 语句中 % 匹配任意数量的字符
SELECT 聚合函数:COUNT(*),返回的总行数,COUNT(${column_name}),返回了指定列的行数(与前面的等价),SUM(${column_name},计算该数值列的和,AVG(${column_name}),计算该数值列的平均值,MAX (${column_name}),计算某一列的最大值,字符类返回排序最后的,MIN(${column_name}),计算某一列的最小值,字符类返回排序最前的,当未返回数据时,COUNT 返回 0,其他的返回 NULL
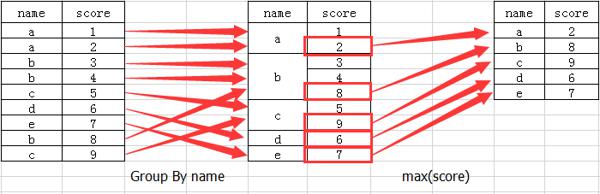
分组查询:执行过程是先把 GROUP BY 指定的列值相同的合并为一组,生成一个中间表,再进行其他操作,分组有多少组返回结果就是多少行,按 GROUP BY 合并的行中不能进行其值合并的列其值将为 NULL(部分数据库会报错,如 MySQL),GROUP BY 后可以使用逗号分隔指定多个列进行分组查询,执行过程是先按 GROUP BY 指定的第一列合并,生成一个中间表,再对中间表的 GRUOP BY 指定的第二列进行合并,再生成一个中间表,依次类推,理解困难看下图
多表查询(笛卡尔乘积):SELECT ${table_name1}.${column_name1} ${alias1}, ${table_name2}.${column_name2} ${alias2} FROM ${table_name1}, ${table_name2}; 多表查询时返回的列名只会有个表的列名而不含表名,如果两个表中有命名冲突则需要取别名
- 给表设置别名:SELECT ${alias1}.${column_name1} ${alias3}, ${alias2}.${column_name2} ${alias4}, ${column_name3} FROM ${table_name1} ${alias1}, ${table_name2} ${alias2};
连接查询:SELECT ${column_name} FROM ${table_name1} ${INNER/RIGHT OUTER/LEFT OUTER/FULL OUTER} JOIN ${table_name2} ON ${table_name1}.${column_name1} ${</=/>/<>/<=/>=} ${table_name2}.${column_name2}; JOIN 左边的表为左表,右边的为右表,连接查询是先对左右表做笛卡尔乘积,再按照 ON 语句进行过滤,INNER JOIN 直接返回过滤后的结果集,RIGHT OUTER JOIN 在结果集中再添加右表中 ON 条件完全未匹配到的行至结果集中,LEFT OUTER JOIN 则是添加左表中的完全未匹配到的行,FULL OUTER JOIN 是两个表中完全未匹配到的行都添加进结果集中,其中,另一个表中不存在的数据值为 NULL
INSERT 语句:INSERT INTO ${table_name} (${column_name1}, ${column_name2}) VALUES (${value1}, ${value2}), (${value3}, ${value4});
UPDATE 语句:UPDATE ${table_name} SET ${column_name1} = ${value1}, ${column_name2} = ${value2} WHERE ${</=/>/<>/<=/>=/ LIKE/()/NOT/AND/OR_column}; UPDATE 语句中,更新的值可以使用表达式,如 ...SET score = score + 10...
DELETE 语句:DELETE FROM ${table_name} WHERE ${</=/>/<>/<=/>=/ LIKE/()/NOT/AND/OR_column};
插入或替换:将 INSERT 替换为 REPLACE 其他语法不变,主键值不存在时插入数据,主键值存在的时候删除旧数据再插入新数据
插入或更新:在 INSERT 语句后加入 DUPLICATE KEY UPDATE ${column_name1} = ${value1}, ${column_name2} j= ${value2}; 如果主键值不存在,将插入数据,否则将更新数据
表的快照:CREATE TABLE ${new_table_name} SELECT * FROM ${old_table_name}; 也可以指定 WHERE 子句只备份特定数据INSERT 使用 SELECT 返回值:INSERT INTO ${table_name1} (${column_name1}, ${column_name2}) SELECT ${column_name3}, ${column_name4} FROM ${table_name2} WHERE {</=/>/<>/<=/>=/ LIKE/()/NOT/AND/OR_column}; 这要求 SELECT 返回的列及其类型与 INSERT 的对应
事物:SQL 脚本中开启一个事物用 BEGIN; 结束一个事务用 COMMIT; 回滚用 ROLLBACK; 设置隔离级别用 SET TRANSACTION ISOLATION LEVEL ${ISOLATION_LEVEL};
Read Uncommitted:隔离级别最低,一个事务可能会读到另一个事务更新但未提交的数据,如果此时回滚将发生脏读
Read Committed:一个事务读取另一个事务正在更新的数据,导致同一次事物中两次取出的数据不一致,即不可重复读
Repeatable Read,:一个事务读取另一个事务正在插入的数据,插入前无法读取到,插入事务提交后仍无法读取到,但是更新时数据又会出现,即幻读,InnoDB 引擎的默认隔离级别
Serializable:最严格的隔离级别,以上三种问题都不会出现,以性能作为代价,默认的隔离级别
SQL 备忘录的更多相关文章
- HANA SQL备忘录
1.改变元素列类型 ALTER TABLE <TABLE_NAME> ALTER (<COLUMN_NAME> <COLUMN_TYPE>);
- 常用SQL备忘录
联表删除: delete t1,t2 from table_name t1 left join t2 on t1.id=t2.id where t1.id=23 (ps:该语句在mysql 5.0之前 ...
- .Net程序员学用Oracle系列(1):导航目录
本人从事基于 Oracle 的 .Net 企业级开发近三年,在此之前学习和使用的都是 (MS)SQL Server.未曾系统的了解过 Oracle,所以长时间感到各种不习惯.不方便.怪异和不解,常会遇 ...
- 基于Qt5.5.0的sql,C++备忘录软件的编写
我的第一个软件. 基于Qt5.5.0的 sql ,C++备忘录软件version1.0的编写 我用的Qt版本是5.5.0免配置编译器的版本,这里附上我使用的软件下载地址:http://download ...
- SQL注入备忘录
备忘录(一) 拿起小本本记下常考知识点. 常用连接词 and && %23%23 且 or || %7c%7c 或 xor 非 Access 数据库: 只能爆破表名.列名获取数据.无法 ...
- SQLCMD备忘录:执行文件夹所有Sql文件
在做性能测试的时候最希望的一件事情是数据自动导入. 一般做法就是写很多SQL文件,通过Bat自动执行所有Sql文件. Bat代码: @ECHO OFF SET SQLCMD="C:\Prog ...
- 常用SQL语句备忘录
1.---表中有重复记录用SQL语句查询出来 select * from Recharge where RechargeSerial in (select RechargeSerial from Re ...
- oracle 负载均衡连接方式常用SQL语句备忘录
1.---表中有重复记录用SQL语句查询出来 select * from Recharge where RechargeSerial in (select RechargeSerial from Re ...
- SQL 知识及用法备忘录
---查询当前数据库一共有多少张表 ) from sysobjects where xtype='U' ---查询当前数据库有多少张视图 ) from sysobjects where xtype=' ...
随机推荐
- 大数据平台搭建:Hadoop
To construct big data distributed platform based on Hadoop is a common method. Hadoop comes fron Goo ...
- selenium+python 数据驱动-txt篇
#循环读取txt文件中的数据,可以作为用户名,密码等使用from selenium import webdriver #创建两个列表user=[]pwd=[]f=open(r'C:\bbs\data\ ...
- Python切片(入门7)
转载请标明出处: http://www.cnblogs.com/why168888/p/6407977.html 本文出自:[Edwin博客园] Python切片 1. 对list进行切片 L = r ...
- js call、apply和bind
function add(a,b) { alert(a+b); } function sub(a,b) { alert(a-b); } add.call(sub,3,1); 例1 例子1中的意思就是用 ...
- IntelliJ IDEA 2017 完美注册方法及破解方法
本文使用破解方式注册. 下载破解文件JetbrainsCrack-2.6.2.jar 下载地址: http://idea.lanyus.com/ 开始破解 一.将下载的 JetbrainsCrack- ...
- INFORMATICA 操作流程
- 利用SPF记录缺失发送伪造邮件
SPF,也就是 Sender Policy Framework 的缩写,是一种以IP地址认证电子邮件发件人身份的技术,是非常高效的垃圾邮件解决方案. 如何查询所属域名邮箱的SPF记录? 查询的结果,从 ...
- 谈谈Ajax(二)
昨天还没有谈完,今天做一个了解. 首先还是以错误,来讲述. 一.AJax常见错误 Ajax常见的错误,除了昨天列举的之外.还有就是如下状态码: 405,请求类型错误,比如请求是POST,你却用GET, ...
- Java获取虚拟机内存和操作系统内存及其线程
为什么要获取虚拟机内存和操作系统内存呢? 虚拟机内存,这里主要指JVM.为了防止有的时候因为JVM内存问题导致服务器宕机,所以有必要监控JVM的内存.当达到一定值时,通过邮件及时通知,防止线上宕机造成 ...
- C/C++判断文件/文件夹是否存在 转
一.判断文件夹是否存在: 1.用CreateDirectory(".//FileManege",NULL);如果文件夹FileManege不存在,则创建. 2.或者 ...