机器翻译质量评测算法-BLEU
机器翻译领域常使用BLEU对翻译质量进行测试评测。我们可以先看wiki上对BLEU的定义。
为什么要用BLEU?
现实中很多时候我们需要用人工来评价翻译结果的,但这种方式非常慢,并且成本非常高,因为你需要请足够专业的翻译人员才能给出相对靠谱的翻译评估结果,一般这种人工评价都偏主观,并且非常依赖专业水平和经验。为了解决这一问题,机器翻译领域的研究人员就发明了一些自动评价指标比如BLEU,METEOR和NIST等,在这些自动评价指标当中,BLEU是目前最接近人类评分的。
BLEU的原理是什么?
BLEU作为评价翻译的质量的指标,包含下面几个概念:
- N-gram
- 惩罚因子
- Bleu
N-gram
N-gram是一种统计语言模型,该模型可以将一句话表示n个连续的单词序列,利用上下文中相邻词间的搭配信息,计算出句子的概率,从而判断一句话是否通顺。BLEU也是采用了N-gram的匹配规则,通过它能够算出比较译文和参考译文之间n组词的相似的一个占比。
这里举一个例子:
原文: 猫坐在垫子上
机器翻译:The cat sat on the mat.
人工翻译:The cat is on the mat.
1-gram
 可以看到机器翻译6个词,有5个词命中参考以为,那么它的匹配度为 5/6。
可以看到机器翻译6个词,有5个词命中参考以为,那么它的匹配度为 5/6。
2-gram
3-gram
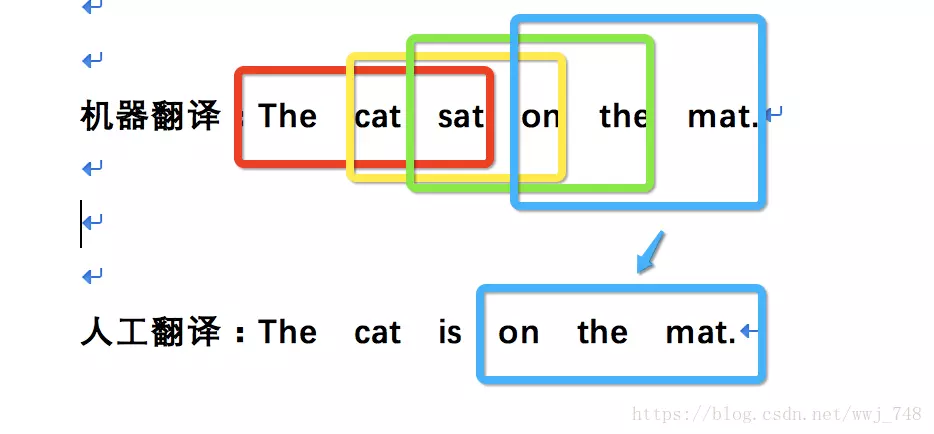 3元词组的匹配度是1/4。
3元词组的匹配度是1/4。
4-gram
4元词组的匹配情况就没有了。
经过上面的举例你应该很清楚n-gram是怎么计算了吧。一般情况1-gram可以代表原文有多少词被单独翻译出来,可以反映译文的充分性,2-gram以上可以反映译文的流畅性,它的值越高说明可读性越好。这两个指标是能够跟人工评价对标的。
但是它存在一些特殊情况,通过n-gram是没办法反映译文的正确性的,例如:
原文:猫坐在垫子上
机器译文: the the the the the the the.
参考译文:The cat is on the mat.

如果计算1-gram的话,你会发现所有the都匹配上了,匹配度是7/7,这个肯定不能反映充分性的,怎么办?
BLEU修正了这个算法,提出取机器翻译译文N-gram的出现次数和参考译文中N-gram最大出现次数中的最小值的算法,具体如下:

所以上面修正后的结果应该是count = 7,Max_ref_Count = 2,取它们之间的最小值为2,那么修正后的1-gram的匹配度应该为2/7。
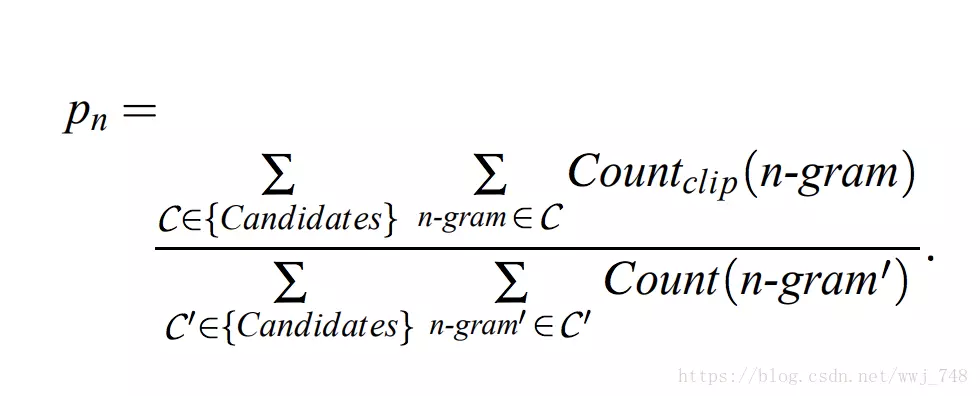
其中,上面部分表示取n-gram在翻译译文和参考译文中出现的最小次数,比如上面的1-gram出现的最小次数是2.
下面部分表示取n-gram在翻译译文中出现次数,比如上面的1-gram出现的次数是7.
机器译文:The cat
参考译文:The cat is on the mat.
如果出现这种短句子,你会发现计算n-gram的精度会得很高分,很显然这次的得分为1,但实际上它的得分应该是比较低的。针对翻译译文长度比参考译文要短的情况,就需要一个惩罚的机制去控制。
惩罚因子:
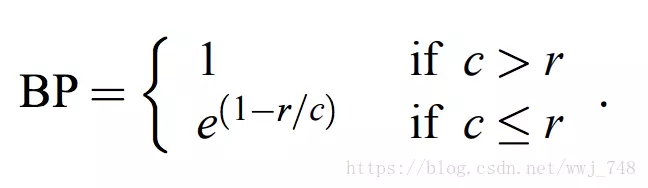
这里的c是机器译文的词数,r是参考译文的词数,
这样的话我们重新算精度就应该是:
BP = e^(1- 6 / 2) = 7.38905609893065
Bleu算法
经过上面的各种改进,BLEU最终的计算公式如下:
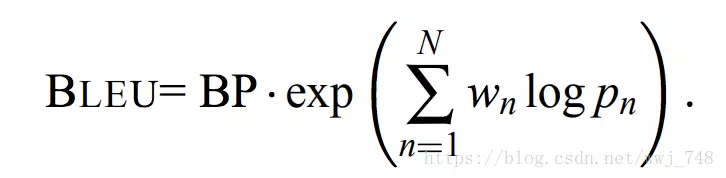
其实,括号里面的部分,就是一些数学运算,它的作用就是让各阶n-gram取权重服从均匀分布,就是说不管是1-gram、2-gram、3-gram还是4-gram它们的作用都是同等重要的。由于随着n-gram的增大,总体的精度得分是呈指数下降的,所以一般N-gram最多取到4-gram。
这里给一个例子,如何具体计算
机器翻译:The cat sat on the mat.
人工翻译:The cat is on the mat.
第一步:计算各阶n-gram的精度
P1 = 5 / 6 = 0.833333333333333
P2 = 3 / 5 = 0.6
P3 = 1 / 4 = 0.25
P4 = 0 / 3 = 0
第二步:加权求和
取权重:Wn = 1 / 4 = 0.25
加权求和:
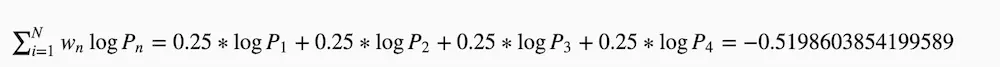
第三步:求BP
机器翻译长度 = 参考译文长度,所以:
BP = 1
最后求BLEU
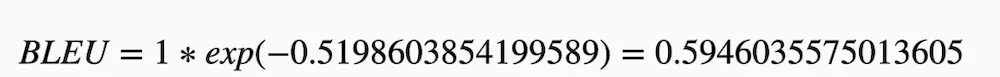
写程序的时候,不用费那么大的劲去实现上面的算法,现成的工具就可以用:
from nltk.translate.bleu_score import sentence_bleu
reference = [['The', 'cat', 'is', 'on', 'the', 'mat']]
candidate = ['The', 'cat', 'sat', 'on', 'the', 'mat']
score = sentence_bleu(reference, candidate)
print(score)
# 输出结果:0.5946035575013605
BLEU的优缺点?
优点:方便、快速,结果比较接近人类评分。
缺点:
- 不考虑语言表达(语法)上的准确性;
- 测评精度会受常用词的干扰;
- 短译句的测评精度有时会较高;
- 没有考虑同义词或相似表达的情况,可能会导致合理翻译被否定;
BLEU本身就不追求百分之百的准确性,也不可能做到百分之百,它的目标只是给出一个快且不差的自动评估解决方案。
最后
BLEU原理其实并不是很复杂,更多是基于n-gram基础上的优化,写这篇文章的目的也是想梳理清楚BLEU能够解决的问题,还有不能解决的问题,这对自己后续思考如何通过其他手段去更好地提高翻译评估的能力有一定的启发作用。翻译质量评估本身就是MT领域的热门课题,如果我们能够找到一个比BLEU更好的,这将会产生很大的价值。
机器翻译质量评测算法-BLEU的更多相关文章
- 一种H.264高清视频的无参考视频质量评价算法(基于QP和跳过宏块数)
本文记录一种无参考视频质量评价算法.这是我们自己实验室前两年一个师姐做的,算法还是比较准确的,在此记录一下. 注意本算法前提是高清视频.而且是H.264编码方式. 该方法主要使用两个码流里面的参数进行 ...
- 揭秘 VMAF 视频质量评测标准
作者:杨洋,阿里云技术专家,从事直播相关媒体处理引擎开发 背景 图像质量的衡量是个老问题,对此人们提出过很多简单可行的解决方案.例如均方误差(Mean-squared-error,MSE).峰值信噪比 ...
- 视频质量评测标准——VMAF
阿里云视频云直播转码每天都会处理大量的不同场景.不同编码格式的直播流.为了保证高画质,团队借助VMAF标准来对每路转码的效果做质量评估,然后进行反馈.调优.迭代.这么做的原因在于,像动作片.纪录片.动 ...
- 机器翻译评测——BLEU算法详解
◆版权声明:本文出自胖喵~的博客,转载必须注明出处. 转载请注明出处:http://www.cnblogs.com/by-dream/p/7679284.html 前言 近年来,在自然语言研究领域中, ...
- Deep Learning基础--机器翻译BLEU与Perplexity详解
前言 近年来,在自然语言研究领域中,评测问题越来越受到广泛的重视,可以说,评测是整个自然语言领域最核心和关键的部分.而机器翻译评价对于机器翻译的研究和发展具有重要意义:机器翻译系统的开发者可以通过评测 ...
- 学习笔记TF067:TensorFlow Serving、Flod、计算加速,机器学习评测体系,公开数据集
TensorFlow Serving https://tensorflow.github.io/serving/ . 生产环境灵活.高性能机器学习模型服务系统.适合基于实际数据大规模运行,产生多个模型 ...
- BLEU (Bilingual Evaluation Understudy)
什么是BLEU? BLEU (Bilingual Evaluation Understudy) is an algorithm for evaluating the quality of text w ...
- CCSUOJ评测系统
队名: BUGG 团队信息与分工: 开发: 周斌 B20150304221 舒 溢 B20150304209 测试: 许嘉荣 B20150304213 唐 浩 B20150304316 Product ...
- 微博推荐算法学习(Weibo Recommend Algolrithm)
原文:http://hijiangtao.github.io/2014/10/06/WeiboRecommendAlgorithm/ 基础及关联算法 作用:为微博推荐挖掘必要的基础资源.解决推荐时的通 ...
随机推荐
- leetcode207
拓扑排序问题. class Solution { public: bool canFinish(int numCourses, vector<pair<int, int>>&a ...
- leetcode337
/** * Definition for a binary tree node. * public class TreeNode { * public int val; * public TreeNo ...
- kill all java php rm.sh
#!/bin/sh#根据进程名杀死进程#FileName: killjavaphprm.sh #查看php进程IDecho "php进程ID:"pgrep php #杀死所有php ...
- IVideoWindow 在directshow采集链路中的使用
dshow中一个完整采集链路一般如下: Capture Device----->SampleGraber ------>Render 如果只要采集原始数据可以不用渲染链路那就如下: Cap ...
- Fiddler 抓包工具怎么使用?怎么在Android手机端的APP抓包
https://blog.csdn.net/loner_fang/article/details/83309266 参考这个人的微博上有fiddler主要功能使用的步骤. 序章 Fiddler是一个蛮 ...
- 我尼玛,二半夜的说中photo.src病毒了。
大半夜手机预警,中病毒了,我感觉也没啥东西呀.一个破小网站,别人黑我干啥. 登上服务器去一看,我滴个乖乖,photo.src病毒.服务器里面显示是一个背景桌面应用程序, 打算直接从文件夹删除,但是正在 ...
- 人工智能为什么选择Python语言?
作为新手,在面对广泛应用于企业级应用开发的 Java.游戏客户端开发的 C++.嵌入式开发的 C.人工智能领域的 Python 等数百种编程语言时,你会如何选择自己的第一门编程语言? 作者 | JAC ...
- [Ting's笔记Day2]在Github用Jekyll创建自己的blog
昨天工程师在我们共同的群组分享他的blog,他提到是使用Jekyll(一个简单静态blog网站生成器)架在github上的. 于是好奇的我决定照着关键字来搜寻一下,如法炮制做一个出来. 也可以放一份到 ...
- 示例:pm_multiple_models 匹配——形状匹配
* This example program shows how to use HALCON's shape-based matching* to find multiple different mo ...
- spring okhttp3
准备工作 在pom.xml文件中增加以下依赖 <dependency> <groupId>com.squareup.okhttp3</groupId> <ar ...