算法-最通俗易懂的KMP算法详解
有些算法,适合从它产生的动机,如何设计与解决问题这样正向地去介绍。但KMP算法真的不适合这样去学。最好的办法是先搞清楚它所用的数据结构是什么,再搞清楚怎么用,最后为什么的问题就会有恍然大悟的感觉。我试着从这个思路再介绍一下。大家只需要记住一点,PMT是什么东西。然后自己临时推这个算法也是能推出来的,完全不需要死记硬背。KMP算法的核心,是一个被称为部分匹配表(Partial Match Table)的数组。我觉得理解KMP的最大障碍就是很多人在看了很多关于KMP的文章之后,仍然搞不懂PMT中的值代表了什么意思。这里我们抛开所有的枝枝蔓蔓,先来解释一下这个数据到底是什么。对于字符串“abababca”,它的PMT如下表所示:
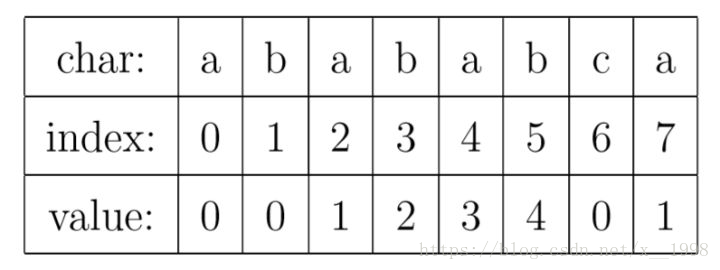
就像例子中所示的,如果待匹配的模式字符串有8个字符,那么PMT就会有8个值。
我先解释一下字符串的前缀和后缀。如果字符串A和B,存在A=BS,其中S是任意的非空字符串,那就称B为A的前缀。例如,”Harry”的前缀包括{”H”, ”Ha”, ”Har”, ”Harr”},我们把所有前缀组成的集合,称为字符串的前缀集合。同样可以定义后缀A=SB, 其中S是任意的非空字符串,那就称B为A的后缀,例如,”Potter”的后缀包括{”otter”, ”tter”, ”ter”, ”er”, ”r”},然后把所有后缀组成的集合,称为字符串的后缀集合。要注意的是,字符串本身并不是自己的后缀。
有了这个定义,就可以说明PMT中的值的意义了。PMT中的值是字符串的前缀集合与后缀集合的交集中最长元素的长度。例如,对于”aba”,它的前缀集合为{”a”, ”ab”},后缀 集合为{”ba”, ”a”}。两个集合的交集为{”a”},那么长度最长的元素就是字符串”a”了,长 度为1,所以对于”aba”而言,它在PMT表中对应的值就是1。再比如,对于字符串”ababa”,它的前缀集合为{”a”, ”ab”, ”aba”, ”abab”},它的后缀集合为{”baba”, ”aba”, ”ba”, ”a”}, 两个集合的交集为{”a”, ”aba”},其中最长的元素为”aba”,长度为3。
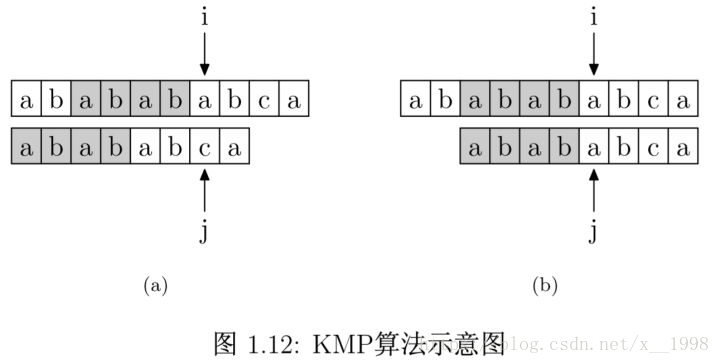
好了,解释清楚这个表是什么之后,我们再来看如何使用这个表来加速字符串的查找,以及这样用的道理是什么。如图 1.12 所示,要在主字符串"ababababca"中查找模式字符串"abababca"。如果在 j 处字符不匹配,那么由于前边所说的模式字符串 PMT 的性质,主字符串中 i 指针之前的 PMT[j −1] 位就一定与模式字符串的第 0 位至第 PMT[j−1] 位是相同的。这是因为主字符串在 i 位失配,也就意味着主字符串从 i−j 到 i 这一段是与模式字符串的 0 到 j 这一段是完全相同的。而我们上面也解释了,模式字符串从 0 到 j−1 ,在这个例子中就是”ababab”,其前缀集合与后缀集合的交集的最长元素为”abab”, 长度为4。所以就可以断言,主字符串中i指针之前的 4 位一定与模式字符串的第0位至第 4 位是相同的,即长度为 4 的后缀与前缀相同。这样一来,我们就可以将这些字符段的比较省略掉。具体的做法是,保持i指针不动,然后将j指针指向模式字符串的PMT[j −1]位即可。
简言之,以图中的例子来说,在 i 处失配,那么主字符串和模式字符串的前边6位就是相同的。又因为模式字符串的前6位,它的前4位前缀和后4位后缀是相同的,所以我们推知主字符串i之前的4位和模式字符串开头的4位是相同的。就是图中的灰色部分。那这部分就不用再比较了。
- int KMP(char * t, char * p)
- {
- int i = 0;
- int j = 0;
- while (i < strlen(t) && j < strlen(p))
- {
- if (j == -1 || t[i] == p[j])
- {
- i++;
- j++;
- }
- else
- j = next[j];
- }
- if (j == strlen(p))
- return i - j;
- else
- return -1;
- }
好了,讲到这里,其实KMP算法的主体就已经讲解完了。你会发现,其实KMP算法的动机是很简单的,解决的方案也很简单。远没有很多教材和算法书里所讲的那么乱七八糟,只要搞明白了PMT的意义,其实整个算法都迎刃而解。
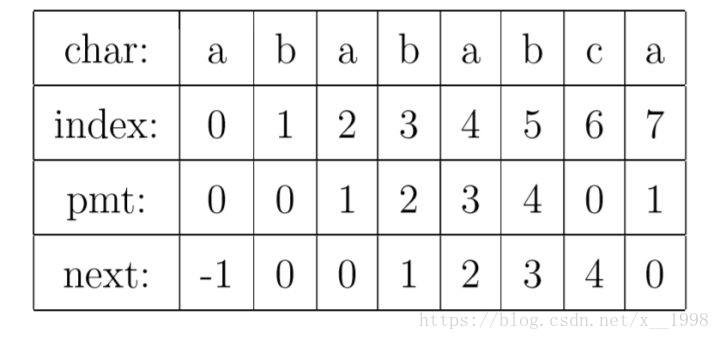
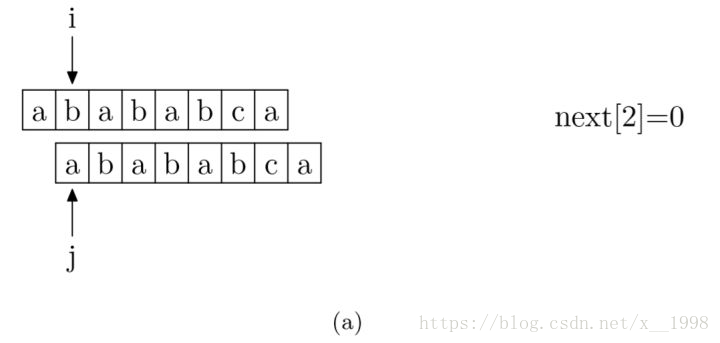
现在,我们再看一下如何编程快速求得next数组。其实,求next数组的过程完全可以看成字符串匹配的过程,即以模式字符串为主字符串,以模式字符串的前缀为目标字符串,一旦字符串匹配成功,那么当前的next值就是匹配成功的字符串的长度。
具体来说,就是从模式字符串的第一位(注意,不包括第0位)开始对自身进行匹配运算。 在任一位置,能匹配的最长长度就是当前位置的next值。如下图所示。
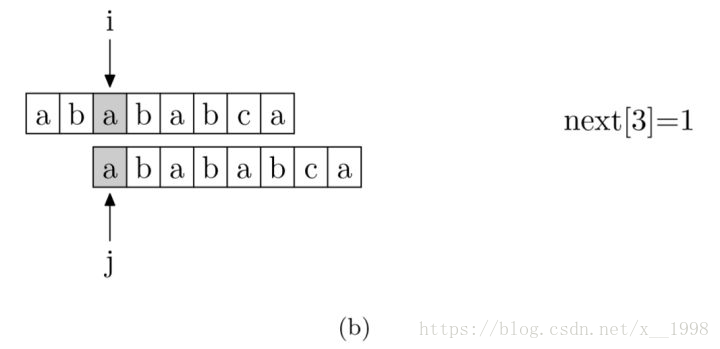
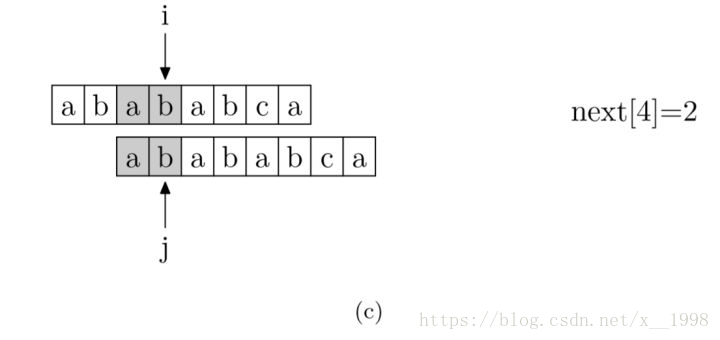
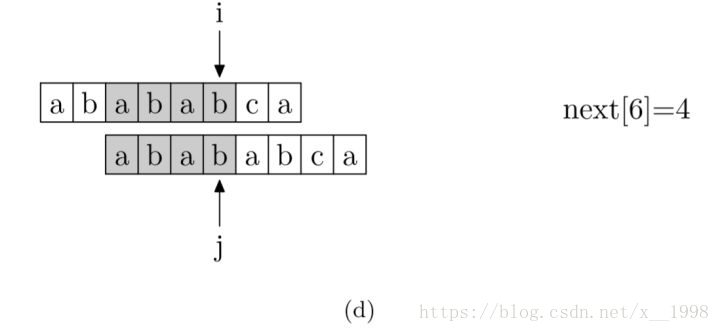
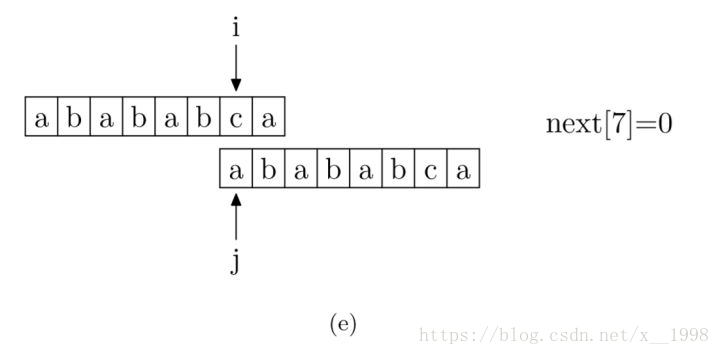
求next数组值的程序如下所示:
- void getNext(char * p, int * next)
- {
- next[0] = -1;
- int i = 0, j = -1;
- while (i < strlen(p))
- {
- if (j == -1 || p[i] == p[j])
- {
- ++i;
- ++j;
- next[i] = j;
- }
- else
- j = next[j];
- }
- }
作者:海纳
链接:https://www.zhihu.com/question/21923021/answer/281346746
来源:知乎
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
算法-最通俗易懂的KMP算法详解的更多相关文章
- [转]EM算法(Expectation Maximization Algorithm)详解
https://blog.csdn.net/zhihua_oba/article/details/73776553 EM算法(Expectation Maximization Algorithm)详解 ...
- Python聚类算法之基本K均值实例详解
Python聚类算法之基本K均值实例详解 本文实例讲述了Python聚类算法之基本K均值运算技巧.分享给大家供大家参考,具体如下: 基本K均值 :选择 K 个初始质心,其中 K 是用户指定的参数,即所 ...
- 搜索引擎算法研究专题五:TF-IDF详解
搜索引擎算法研究专题五:TF-IDF详解 2017年12月19日 ⁄ 搜索技术 ⁄ 共 1396字 ⁄ 字号 小 中 大 ⁄ 评论关闭 TF-IDF(term frequency–inverse ...
- 目标检测算法(一):R-CNN详解
参考博文:https://blog.csdn.net/hjimce/article/details/50187029 R-CNN(Regions with CNN features)--2014年提出 ...
- 二分算法题目训练(四)——Robin Hood详解
codeforces672D——Robin Hood详解 Robin Hood 问题描述(google翻译) 我们都知道罗宾汉令人印象深刻的故事.罗宾汉利用他的射箭技巧和他的智慧从富人那里偷钱,然后把 ...
- 二分算法题目训练(一)——Shell Pyramid详解
HDU2446——Shell Pyramid 详解 Shell Pyramid 题目描述(Google 翻译的) 在17世纪,由于雷鸣般的喧嚣,浓烟和炽热的火焰,海上的战斗与现代战争一样.但那时,大炮 ...
- DPLL 算法(求解k-SAT问题)详解(C++实现)
\(\text{By}\ \mathsf{Chesium}\) DPLL 算法,全称为 Davis-Putnam-Logemann-Loveland(戴维斯-普特南-洛吉曼-洛夫兰德)算法,是一种完备 ...
- 串匹配算法讲解 -----BF、KMP算法
参考文章: http://www.matrix67.com/blog/archives/115 KMP算法详解 http://blog.csdn.net/yaochunnian/artic ...
- 大话数据结构(十二)java程序——KMP算法及改进的KMP算法实现
1.朴素的模式匹配算法 朴素的模式匹配算法:就是对主串的每个字符作为子串开头,与要连接的字符串进行匹配.对主串做大循环,每个字符开头做T的长度的小循环,直到成功匹配或全部遍历完成为止. 又称BF算法 ...
随机推荐
- CSS中border和outline的区别
border: border-width:1px; border-style:solid; border-color:#ccc; 可以简写为:border:1ox solid #ccc; outlin ...
- gateway + jwt 网关认证
思路: 全局过滤器对所有的请求拦截(生成token有效期30分钟,放入redis设置有效期3天.3天之类可以通过刷新接口自动刷新,超过3天需要重新登录.) 前端在调用接口之前先判断token是否过期( ...
- Vue系列之 => 路由的嵌套
<!DOCTYPE html> <html> <head> <meta charset="utf-8"> <meta name ...
- 什么是软件开发工具包(SDK)
开发一个软件,需要经过编辑.编译.调试.运行几个过程. 编辑:使用编程语言编写程序代码的过程. 编译:如上一节所讲,就是将编写的程序进行翻译. 调试:程序不可能一次性编写成功,编写过程中难免会出现语法 ...
- springboot 没有跳转到指定页面
Whitelabel Error Page 解决办法,添加依赖: <dependency> <groupId>org.springframework.boot</gr ...
- 【报错原因】Uncaught SyntaxError: Unexpected token <
实际上是当前页面引入的js文件路径找不到!!! 页面查找不到js文件自动跳转到404.html页面 域名+/404.html
- 使用sp_addlinkedserver、sp_dropserver 、sp_addlinkedsrvlogin和sp_droplinkedsrvlogin 远程查询数据
一.sp_addlinkedserver 创建链接服务器. 链接服务器让用户可以对 OLE DB 数据源进行分布式异类查询. 在使用 sp_addlinkedserver 创建链接服务器后,可对该服 ...
- “Nested exception: 前言中不允许有内容"错误处理
最近在做一个小项目,使用org.dom4j.DocumentHelper.parseText方法时一直报错”Nested exception: 前言中不允许有内容",这个parseText解 ...
- java static语句的总结
static 是静态方法,他的引用不需要对象,可以使用类名直接进行引用,当然也不需要this. 由于不需要对象,所以static方法内无法调用非static的方法或对象 至于为什么mai ...
- Python 协程并发爬虫网页
简单爬虫实例: 功能:通过urllib.request实现网站爬虫,捕获网站内容. from urllib import request def f(url): print("GET:%s& ...