SQL Server 2016 查询存储性能优化小结
SQL Server 2016已经发布了有半年多,相信还有很多小伙伴还没有开始使用,今天我们来谈谈SQL Server 2016 查询存储性能优化,希望大家能够喜欢
作为一个DBA,排除SQL Server问题是我们的职责之一,每个月都有很多人给我们带来各种不能解释却要解决的性能问题。
我就多次听到,以前的SQL Server的性能问题都还好且在正常范围内,但现在一切已经改变,SQL Server开始糟糕, 疯狂的事情不能解释。在这个情况下我介入,分析下整个SQL Server的安装,最后用一些神奇的调查方法找出性能问题的根源。
但很多时候问题的根源是一样的:所谓的计划回归(Plan Regression),即特定查询的执行计划已经改变。昨天SQL Server已经缓存了在计划缓存里缓存了一个好的执行计划,今天就生成、缓存最后重用了一个糟糕的执行计划——不断重复。
进入SQL Server 2016后,我就变得有点多余了,以为微软引进了查询存储(Query Store)。这是这个版本最热门的功能!查询存储帮助你很容易找出你的性能问题是不是计划回归造成的。如果你找到了计划回归,这很容易强制一个特定计划不使用计划向导。听起来很有意思?让我们通过一个特定的场景,向你展示下在SQL Server 2016里,如何使用查询存储来找出并最终修正计划回归。
查询存储(Query Store)——我的对手
在SQL Server 2016里,在你使用查询存储功能前,你要对这个数据库启用它。这是通过ALTER DATABASE语句实现,如你所见的下列代码
CREATE DATABASE QueryStoreDemo
GO USE QueryStoreDemo
GO -- Enable the Query Store for our database
ALTER DATABASE QueryStoreDemo
SET QUERY_STORE = ON
GO -- Configure the Query Store
ALTER DATABASE QueryStoreDemo SET QUERY_STORE
(
OPERATION_MODE = READ_WRITE,
CLEANUP_POLICY = (STALE_QUERY_THRESHOLD_DAYS = 367),
DATA_FLUSH_INTERVAL_SECONDS = 900,
INTERVAL_LENGTH_MINUTES = 1,
MAX_STORAGE_SIZE_MB = 100,
QUERY_CAPTURE_MODE = ALL,
SIZE_BASED_CLEANUP_MODE = OFF
)
GO
在线帮助为你提供了各个选项的详细信息。接下来我创建一个简单的表,创建一个非聚集索引,最后插入80000条记录。
-- Create a new table
CREATE TABLE Customers
(
CustomerID INT NOT NULL PRIMARY KEY CLUSTERED,
CustomerName CHAR(10) NOT NULL,
CustomerAddress CHAR(10) NOT NULL,
Comments CHAR(5) NOT NULL,
Value INT NOT NULL
)
GO -- Create a supporting new Non-Clustered Index.
CREATE UNIQUE NONCLUSTERED INDEX idx_Test ON Customers(Value)
GO -- Insert 80000 records
DECLARE @i INT = 1
WHILE (@i <= 80000)
BEGIN
INSERT INTO Customers VALUES
(
@i,
CAST(@i AS CHAR(10)),
CAST(@i AS CHAR(10)),
CAST(@i AS CHAR(5)),
@i
) SET @i += 1
END
GO
为了访问我们的表,我额创建了一个简单的存储过程,传入value值作为过滤谓语。
-- Create a simple stored procedure to retrieve the data
CREATE PROCEDURE RetrieveCustomers
(
@Value INT
)
AS
BEGIN
SELECT * FROM Customers
WHERE Value < @Value
END
GO
现在我用80000的参数值来执行存储过程。
-- Execute the stored procedure.
-- This generates an execution plan with a Key Lookup (Clustered).
EXEC RetrieveCustomers 80000
GO
现在当你查看实际的执行计划时,你会看到查询优化器已经选择了有419个逻辑读的聚集索引扫描运算符。SQL Server并没有使用非聚集索引,因为这样没有意义,由于临界点。这个查询结果并没有选择性。
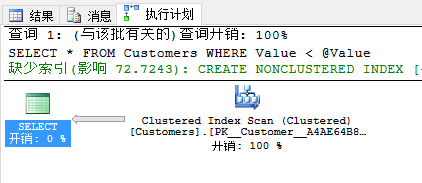
现在假设SQL Server发生了些事情(例如重启,故障转移),SQL Server忽略已经缓存的计划,这里我通过执行DBCC FREEPROCCACHE从计划缓存里抹掉每个缓存的计划来模拟SQL Server重启(不要在生产环境里使用!)。
-- Get rid of the cached execution plan...
DBCC FREEPROCCACHE
GO
现在有人再次调用你的存储过程,这次输入参数值是1。这次执行计划不一样,因为现在在执行计划里你会有书签查找。SQL Server估计行数是1,在非聚集索引里没有找到任何行。因此与非聚集索引查找结合的书签查找才有意义,因为这个查询是有选择性的。
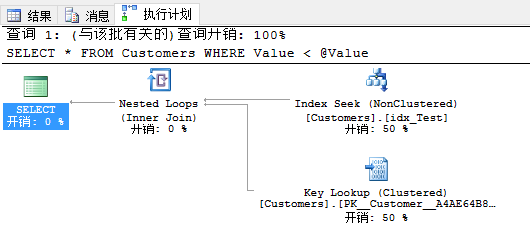
现在我再执行用80000参数值的查询。
-- Execute the stored procedure
EXEC RetrieveCustomers 1
GO -- Execute the stored procedure again
-- This introduces now a plan regression, because now we get a Clustered Index Scan
-- instead of the Key Lookup (Clustered).
EXEC RetrieveCustomers 80000
GO
当你再次看STATISTICS IO的输出,你会看到这个查询现在产生了160139个逻辑读——刚才的查询只有419个逻辑读。这个时候DBA的手机就会响起,性能问题。但今天我们要不同的方式解决——使用刚才启用的查询存储。
当你再次看实际的执行计划,在你面前你会看到有一个计划回归,因为SQL Server刚重用了书签查找的的计划缓存。刚才你有聚集索引扫描运算符的执行计划。这是SQL Server里参数嗅探的副作用。
让我们通过查询存储来详细了解这个问题。在SSMS里的对象资源管理器里,SQL Server 2016提供了一个新的结点叫查询存储,这里你会看到一些报表。
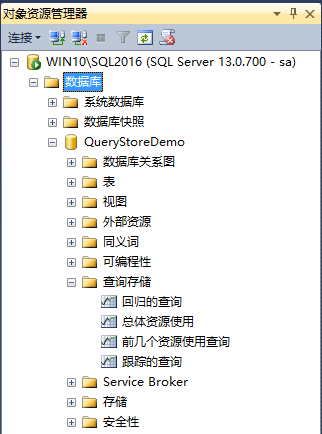
【前几个资源使用查询】向你展示了最昂贵的查询,基于你选择的维度。这里切换到【逻辑读取次数】。
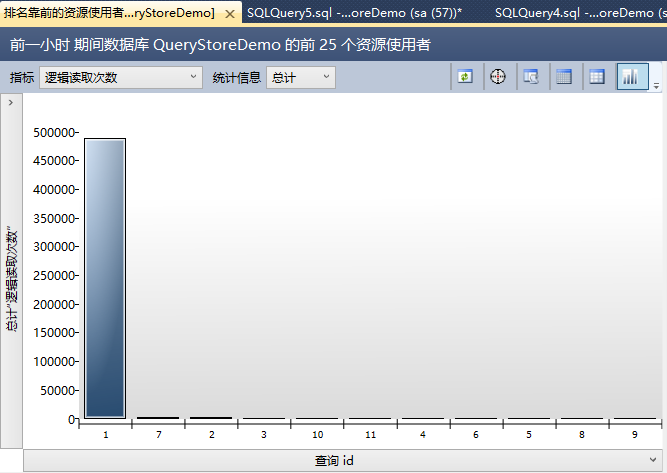
这里在你面前有一些查询。最昂贵的查询生成了近500000个逻辑读。这是我们的初始语句。这已经是第一个WOW效果的的查询存储:SQL Server重启后,查询存储的数据还是存在的!第2个是你存储过程里的SELECT语句。在查询存储里每个捕获的查询都有一个标示号——这里是7。最后当你看报告的右边,你会看这个查询的不同执行计划。

如你所见,查询存储捕获了2个不同的执行计划,一个ID是7,一个ID是8。当你点击计划ID时,SQL Server会在报表的最下面为你显示估计的执行计划。
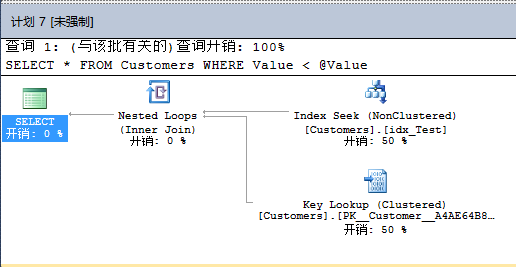
计划8是聚集索引扫描,计划7是书签查找。如你所见,使用查询存储分析计划回归非常简单。但你现在还没结束。你现在可以对指定的查询强制执行计划。 现在你知道包含聚集索引扫描的执行计划有更好的性能。因此现在你可以通过点击【强制执行计划】强制查询7使用执行计划。

搞定,我们已经解决问题了!
现在当你执行存储过程(用80000的输入参数值),在执行计划里你可以看到聚集索引扫描,执行计划只生成419个逻辑读——很简单,是不是?绝对不是!!!!
微软告诉我们只给修正SQL Server性能相关的“新方式”。你只是强制了特定的计划,一切都还好。这个方法有个大的问题,因为性能问题的根源并没有解决!这个问题的关键是因为书签查找计划没有稳定性。取决于首次执行计划默认的输入值,执行计划因此就被不断重用。
通常我会建议调整下你的索引设计,创建一个覆盖索引来保证计划的稳定性。但强制特定执行计划只是临时解决问题——你还是要修正你问题的根源。
小结
不要误解我:SQL Server 2016里的查询存储功能很棒,可以帮你更容易理解计划回归。它也会帮你“临时”强制特定的执行计划。但性能调优的目标还是一样:你要找到问题根源,尝试解决问题——不要在外面晃荡!
SQL Server 2016 查询存储性能优化小结的更多相关文章
- 【SQL server初级】数据库性能优化一:数据库自身优化(大数据量)
数据库优化包含以下三部分,数据库自身的优化,数据库表优化,程序操作优化.此文为第一部分 数据库性能优化一:数据库自身优化 优化①:增加次数据文件,设置文件自动增长(粗略数据分区) 1.1:增加次数据文 ...
- 【SQL server初级】数据库性能优化三:程序操作优化
数据库优化包含以下三部分,数据库自身的优化,数据库表优化,程序操作优化.此文为第三部分 数据库性能优化三:程序操作优化 概述:程序访问优化也可以认为是访问SQL语句的优化,一个好的SQL语句是可以减少 ...
- SQL Server 2016中In-Memory OLTP继CTP3之后的新改进
SQL Server 2016中In-Memory OLTP继CTP3之后的新改进 转译自:https://blogs.msdn.microsoft.com/sqlserverstorageengin ...
- 在SQL Server 2016里使用查询存储进行性能调优
作为一个DBA,排除SQL Server问题是我们的职责之一,每个月都有很多人给我们带来各种不能解释却要解决的性能问题. 我就多次听到,以前的SQL Server的性能问题都还好且在正常范围内,但现在 ...
- sql server 2016新特性 查询存储(Query Store)的性能影响
前段时间给客户处理性能问题,遇到一个新问题, 客户的架构用的是 alwayson ,并且硬件用的是4路96核心,内存1T ,全固态闪存盘,sql server 2016 . 问题 描述 客户经常出现 ...
- SQL Server 2016新特性:列存储索引新特性
SQL Server 2016新特性:列存储索引新特性 行存储表可以有一个可更新的列存储索引,之前非聚集的列存储索引是只读的. 非聚集的列存储索引支持筛选条件. 在内存优化表中可以有一个列存储索引,可 ...
- 50种方法优化SQL Server数据库查询
查询速度慢的原因很多,常见如下几种: 1.没有索引或者没有用到索引(这是查询慢最常见的问题,是程序设计的缺陷) 2.I/O吞吐量小,形成了瓶颈效应. 3.没有创建计算列导致查询不优化. 4.内存不足 ...
- 转载 50种方法优化SQL Server数据库查询
原文地址 http://www.cnblogs.com/zhycyq/articles/2636748.html 50种方法优化SQL Server数据库查询 查询速度慢的原因很多,常见如下几种: 1 ...
- SQL Server 2016:内存列存储索引
作者 Jonathan Allen,译者 谢丽 SQL Server 2016的一项新特性是可以在“内存优化表(Memory Optimized Table)”上添加“列存储索引(Columnstor ...
随机推荐
- 一个小demo 实用selenium 抓取淘宝搜索页面内的产品内容
废话少说,上代码 #conding:utf-8 import re from selenium import webdriver from selenium.webdriver.common.by i ...
- BZOJ.2679.Balanced Cow Subsets(meet in the middle)
BZOJ 洛谷 \(Description\) 给定\(n\)个数\(A_i\).求它有多少个子集,满足能被划分为两个和相等的集合. \(n\leq 20,1\leq A_i\leq10^8\). \ ...
- cf 443
题目链接 A,对于每一位可以暴力输入,看输出是什么,然后就有2x2中对应方式,然后可以用3次运算搞了,好像网上在悬赏最多只用2次搞出来的. B,这个题可以先处理每个串内部的情况,再处理连接处的情况,代 ...
- set_include_path和get_include_path用法详解
首先set_include_path这个函数呢,是在脚本里动态地对PHP.ini中include_path进行修改的.而这个include_path呢,它可以针对下面的include和require的 ...
- mongoose根据_id更新,且如果数组中没有元素就添加
await model.photo.update({ _id: { $in: photoIdsParam } }, { $addToSet: { customerIds: { code: custCo ...
- 上海交大ACM总教头俞勇讲述“最聪明人的故事”
这是一场世界大学生之间"最强大脑"的较量:这是拥有数十年历史的ACM国际大学生计算机程序设计大赛的赛场:斯坦福.加州理工.麻省理工.哈佛--当一个又一个在计算机科学领域拥有世界顶尖 ...
- error: RPC failed
error: RPC failed error: RPC failed; curl 56 GnuTLS recv error (-54): Error in the pull function. fa ...
- 第2讲——wiz
PC端信息收集 网页剪藏 win+s 屏幕截图:win+printscreen微博收集:@mywiz @我的印象笔记 按ESC隐藏/恢复左边导航栏 F11全屏阅读 打标签:解决文件夹重叠问题 搜索 ...
- [Vijos1130][NOIP2001]数的计数 (递推)
自己的递推一塌糊涂 考前抱佛脚 #include<bits/stdc++.h> using namespace std; ]; int main() { int n;scanf(" ...
- python系统编程(一)
进程的创建-fork 1. 进程 VS 程序 编写完毕的代码,在没有运行的时候,称之为程序 正在运行着的代码,就成为进程 进程,除了包含代码以外,还有需要运行的环境等,所以和程序是有区别的 2. fo ...