Kafka初入门简单配置与使用
一 Kafka概述
1.1 Kafka是什么
在流式计算中,Kafka一般用来缓存数据,Storm通过消费Kafka的数据进行计算。
1)Apache Kafka是一个开源消息系统,由Scala写成。是由Apache软件基金会开发的一个开源消息系统项目。
2)Kafka最初是由LinkedIn开发,并于2011年初开源。2012年10月从Apache Incubator毕业。该项目的目标是为处理实时数据提供一个统一、高通量、低等待的平台。
3)Kafka是一个分布式消息队列。Kafka对消息保存时根据Topic进行归类,发送消息者称为Producer,消息接受者称为Consumer,此外kafka集群有多个kafka实例组成,每个实例(server)称为broker。
4)无论是kafka集群,还是producer和consumer都依赖于zookeeper集群保存一些meta信息,来保证系统可用性。
1.2 Kafka内部实现原理
(1)点对点模式(一对一,消费者主动拉取数据,消息收到后消息清除)
点对点模型通常是一个基于拉取或者轮询的消息传送模型,这种模型从队列中请求信息,而不是将消息推送到客户端。这个模型的特点是发送到队列的消息被一个且只有一个接收者接收处理,即使有多个消息监听者也是如此。
(2)发布/订阅模式(一对多,数据生产后,推送给所有订阅者)
发布订阅模型则是一个基于推送的消息传送模型。发布订阅模型可以有多种不同的订阅者,临时订阅者只在主动监听主题时才接收消息,而持久订阅者则监听主题的所有消息,即使当前订阅者不可用,处于离线状态。
1.2 为什么需要消息队列
1)解耦:
允许你独立的扩展或修改两边的处理过程,只要确保它们遵守同样的接口约束。
2)冗余:
消息队列把数据进行持久化直到它们已经被完全处理,通过这一方式规避了数据丢失风险。许多消息队列所采用的"插入-获取-删除"范式中,在把一个消息从队列中删除之前,需要你的处理系统明确的指出该消息已经被处理完毕,从而确保你的数据被安全的保存直到你使用完毕。
3)扩展性:
因为消息队列解耦了你的处理过程,所以增大消息入队和处理的频率是很容易的,只要
另外增加处理过程即可。
4)灵活性 & 峰值处理能力:
在访问量剧增的情况下,应用仍然需要继续发挥作用,但是这样的突发流量并不常见。如果为以能处理这类峰值访问为标准来投入资源随时待命无疑是巨大的浪费。使用消息队列能够使关键组件顶住突发的访问压力,而不会因为突发的超负荷的请求而完全崩溃。
5)可恢复性:
系统的一部分组件失效时,不会影响到整个系统。消息队列降低了进程间的耦合度,所以即使一个处理消息的进程挂掉,加入队列中的消息仍然可以在系统恢复后被处理。
6)顺序保证:
在大多使用场景下,数据处理的顺序都很重要。大部分消息队列本来就是排序的,并且能保证数据会按照特定的顺序来处理。(Kafka保证一个Partition内的消息的有序性)
7)缓冲:
有助于控制和优化数据流经过系统的速度,解决生产消息和消费消息的处理速度不一致的情况。
8)异步通信:
很多时候,用户不想也不需要立即处理消息。消息队列提供了异步处理机制,允许用户把一个消息放入队列,但并不立即处理它。想向队列中放入多少消息就放多少,然后在需要的时候再去处理它们。
一 Kafka集群部署
2.1 环境准备
2.1.1 集群规划
hadoop201 hadoop202 hadoop203
zk zk zk
kafka kafka kafka
2.1.2 jar包下载
官网: http://kafka.apache.org/downloads.html
2.1.3 虚拟机准备
1)准备3台虚拟机
2)配置ip地址
3)配置主机名称
4)3台主机分别关闭防火墙
2.1.4 安装jdk
2.1.5 安装Zookeeper
2.2 Kafka集群部署
1)解压安装包
tar -zxvf kafka_2.11-0.11.0.0.tgz -C /opt/module/
2)修改解压后的文件名称
cd /opt/module/
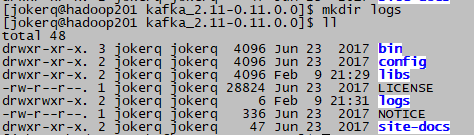
3)在/opt/module/kafka目录下创建logs文件夹
cd kafka_2.11-0.11.0.0/
mkdir logs
4)修改配置文件
cd config/
4.1修改server.properties(vi server.properties)

(文件解释
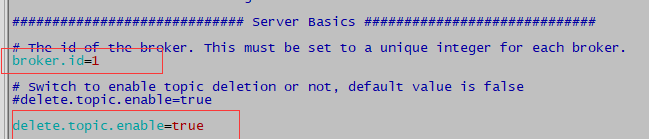
#broker的全局唯一编号,不能重复
broker.id=0
#删除topic功能使能
delete.topic.enable=true
#处理网络请求的线程数量
num.network.threads=3
#用来处理磁盘IO的现成数量
num.io.threads=8
#发送套接字的缓冲区大小
socket.send.buffer.bytes=102400
#接收套接字的缓冲区大小
socket.receive.buffer.bytes=102400
#请求套接字的缓冲区大小
socket.request.max.bytes=104857600
#kafka运行日志存放的路径
log.dirs=/opt/module/kafka_2.11-0.11.0.0/logs
#topic在当前broker上的分区个数
num.partitions=1
#用来恢复和清理data下数据的线程数量
num.recovery.threads.per.data.dir=1
#segment文件保留的最长时间,超时将被删除
log.retention.hours=168
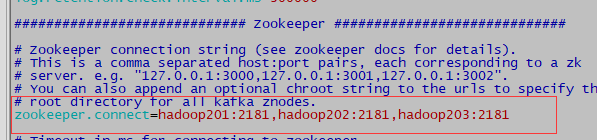
#配置连接Zookeeper集群地址
zookeeper.connect=hadoop201:2181,hadoop202:2181,hadoop203:2181
)
5)配置环境变量
su root
vi /etc/profile
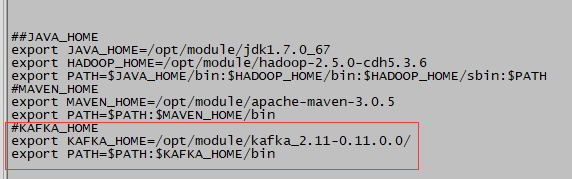
#KAFKA_HOME
export KAFKA_HOME=/opt/module/kafka_2.11-0.11.0.0/
export PATH=$PATH:$KAFKA_HOME/bin
source /etc/profile
6)分发安装包
cd /etc/
scp profile hadoop202:/etc/
scp profile hadoop203:/etc/
su jokerq
scp -r kafka_2.11-0.11.0.0/ hadoop202:/opt/module/
scp -r kafka_2.11-0.11.0.0/ hadoop203:/opt/module/
7)分别在hadoop202和hadoop203上修改配置文件/opt/module/kafka/config/server.properties中
的broker.id=2、broker.id=3
注:broker.id不得重复

7.1)在1 2 3中(source /etc/profile)
8)启动集群
依次在hadoop201、hadoop202、hadoop203节点上启动kafka
cd /opt/module/kafka_2.11-0.11.0.0/
bin/kafka-server-start.sh config/server.properties & (完事按下回车即可回到命令行)
2.3 Kafka命令行操作
1)查看当前服务器中的所有topic
[atguigu@hadoop102 kafka]$ bin/kafka-topics.sh --list --zookeeper hadoop102:2181
2)创建topic
[atguigu@hadoop102 kafka]$ bin/kafka-topics.sh --create --zookeeper hadoop102:2181 --replication-factor 3 --partitions 1 --topic first
选项说明:
--topic 定义topic名
--replication-factor 定义副本数
--partitions 定义分区数
3) 删除topic
[atguigu@hadoop102 kafka]$ bin/kafka-topics.sh --delete --zookeeper hadoop102:2181 --topic first
需要server.properties中设置delete.topic.enable=true否则只是标记删除或者直接重启。
4)发送消息
[atguigu@hadoop102 kafka]$ bin/kafka-console-producer.sh --broker-list hadoop102:9092 --topic first
>hello world
>atguigu atguigu
5)消费消息
[atguigu@hadoop103 kafka]$ bin/kafka-console-consumer.sh --zookeeper hadoop102:2181 --from-beginning --topic first
6)查看某个Topic的详情
[atguigu@hadoop102 kafka]$ bin/kafka-topics.sh --topic first --describe --zookeeper hadoop102:2181
ctrl z bg--后台
fg--前台 (干掉进程:然后按ctrl+c 干掉进程)
Kafka初入门简单配置与使用的更多相关文章
- Flume初入门简单配置与使用
1.Flume在集群中扮演的角色 Flume.Kafka用来实时进行数据收集,Spark.Storm用来实时处理数据,impala用来实时查询. 2.Flume框架简介 1.1 Flume提供一个分布 ...
- NHibernate初入门之配置文件属性说明(四)
一.NHibernate配置所支持的属性 属性名 用途 dialect 设置NHibernate的Dialect类名 - 允许NHibernate针对特定的关系数据库生成优化的SQL 可用值: ful ...
- Nhibernate初入门基本配置(二)
转载地址http://www.cnblogs.com/kissdodog/p/3306428.html 使用NHibernate最重要的一步就是配置,如果连NHibernate都还没有跑的起来,谈何学 ...
- Nhibernate初入门基本配置(一)
文章出处:http://www.cnblogs.com/GoodHelper/archive/2011/02/14/nhiberante_01.html 一.NHibernate简介 什么是?NHib ...
- Maven+SpringMVC+Dubbo 简单的入门demo配置
转载自:https://cloud.tencent.com/developer/article/1010636 之前一直听说dubbo,是一个很厉害的分布式服务框架,而且巴巴将其开源,这对于咱们广大程 ...
- kafka快速入门(官方文档)
第1步:下载代码 下载 1.0.0版本并解压缩. > tar -xzf kafka_2.11-1.0.0.tgz > cd kafka_2.11-1.0.0 第2步:启动服务器 Kafka ...
- 【Spark深入学习 -15】Spark Streaming前奏-Kafka初体验
----本节内容------- 1.Kafka基础概念 1.1 出世背景 1.2 基本原理 1.2.1.前置知识 1.2.2.架构和原理 1.2.3.基本概念 1.2.4.kafka特点 2.Kafk ...
- Kafka 之 入门
摘要: 最近研究采集层,对Kafka做了一个研究.分为入门,中级,高级步步进阶.本篇主要介绍基本概念,适用场景. 一.入门 1. 简介 Kafka is a distributed, parti ...
- Kafka从入门到放弃(三) —— 详说生产者
上一篇对Kafka做了简单介绍,还没看的朋友可以点击下方链接. Kafka从入门到放弃(一) -- 初识别Kafka 消息中间件必须与生产者和消费者一起存在才有意义,这次先来聊聊Kafka的生产者. ...
随机推荐
- 收藏的blog
https://www.cnblogs.com/xifengxiaoma/tag/vue/ https://www.cnblogs.com/xifengxiaoma/p/9400200.html
- PICE(6):集群环境里多异类端点gRPC Streaming - Heterogeneous multi-endpoints gRPC streaming
gRPC Streaming的操作对象由服务端和客户端组成.在一个包含了多个不同服务的集群环境中可能需要从一个服务里调用另一个服务端提供的服务.这时调用服务端又成为了提供服务端的客户端了(服务消费端) ...
- 如何在cygwin中运行crontab定时脚本[利刃篇]
用到cygwin,自然是希望能多处理一些类似linux的任务了,那就自然少不了定时任务crontab,看到网上教程不少,自己运行一个测试却也不那么容易,下面就记录我的安装过程,以供参考吧! 1.首先, ...
- 手把手教你如何用eclipse搭建前端开发环境
3.创建静态web工程 打开eclipse,选择file,new project 或者 new other...,选择web项中的static web project ,next. 输入你的项目名,如 ...
- Python基础入门教程(3)
人生苦短,我学Pyhton Python(英语发音:/ˈpaɪθən/), 是一种面向对象.解释型计算机程序设计语言,由Guido van Rossum于1989年底发明,第一个公开发行版发行于199 ...
- .NET手记-ASP.NET MVC快速分页的实现
对于Web应用,展示List是很常见的需求,随之而来的常见的分页组件.jQuery有现成的分页组件,网上也有着大量的第三方分页组件,都能够快速实现分页功能.但是今天我描述的是用基本的C#和html代码 ...
- C#单元测试分享ppt
单元测试(unit testing),是指对软件中的最小可测试单元进行检查和验证.对于单元测试中单元的含义,一般来说,要根据实际情况去判定其具体含义,如C语言中单元指一个函数,Java里单元指一个类, ...
- 第七章:四大组件之Service
Service是Android系统中的一种组件,它跟Activity的级别差不多,但是它不能自己运行,只能后台运行,并且可以和其他组件进行交互.Service是没有界面的长生命周期的代码.Servic ...
- TCP/IP 笔记 - 域名解析和域名系统
由于IP地址的烦琐导致的记忆和使用困难,互联网支持使用主机名称来识别包括客户机和服务器在内的主机.同时为了使用一系列协议,主机名称通过称为"名称解析"的过程转换成对应IP地址. 互 ...
- 转:Bash Shell常用快捷键
转载:原文出处 移动光标 ctrl+b: 前移一个字符(backward) ctrl+f: 后移一个字符(forward) alt+b: 前移一个单词 alt+f: 后移一个单词 ctrl+a: 移到 ...