hadoop伪分布式环境搭建
环境:Centos6.9+jdk+hadoop
1.下载hadoop的tar包,这里以hadoop2.6.5版本为例,下载地址https://archive.apache.org/dist/hadoop/common/hadoop-2.6.5/hadoop-2.6.5.tar.gz
2.修改linux虚拟机的主机名HOSTNAME的值改为hadoop01.zjl.com
# vi /etc/sysconfig/network
NETWORKING=yes
HOSTNAME=hadoop01.zjl.com
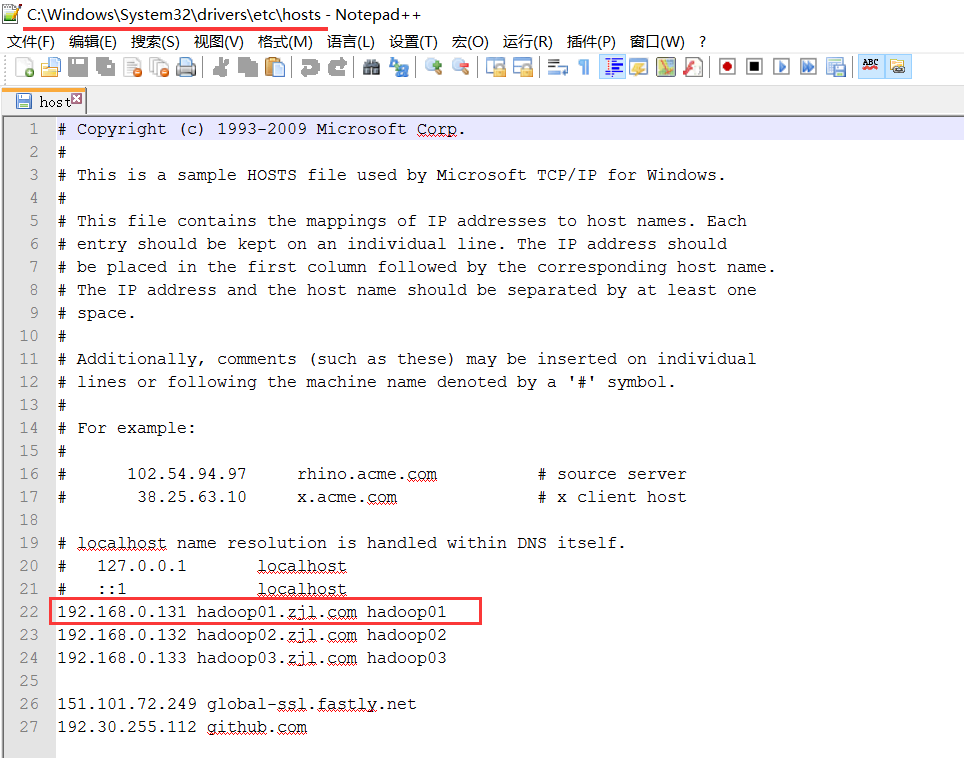
3.配置主机名和IP地址的映射,在/etc/hosts文件末尾 追加192.168.0.131 hadoop01.zjl.com hadoop01
# vi /etc/hosts
127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4
:: localhost localhost.localdomain localhost6 localhost6.localdomain6
192.168.0.131 hadoop01.zjl.com hadoop01
4.关闭防火墙后,重启虚拟机,是步骤2、3、4的配置生效
service iptables stop
service ip6tables stop
service iptables status
service ip6tables status
chkconfig iptables off
chkconfig ip6tablesoff
vi /etc/selinux/config
SELINUX=disabled
5.在物理机的hosts文件中配置192.168.0.131 hadoop01.zjl.com hadoop01,我的物理机是win10 64位操作系统,hosts文件的位置是C:\Windows\System32\drivers\etc\hosts
6.(1)执行# rpm -qa|grep java,发现虚拟机中没装过jdk,如果装过可以用# rpm -e --nodeps来卸载
(2)jdk安装包没有执行权限
# ll jdk-8u131-linux-x64.tar.gz
-rw-rw-r--. hadoop hadoop May : jdk-8u131-linux-x64.tar.gz
(3)给安装包授予执行权限
$ chmod u+x jdk-8u131-linux-x64.tar.gz
(4)解压安装
$ tar -zxvf jdk-8u131-linux-x64.tar.gz -C /opt/modules/
7.(1)配置环境变量
# vi /etc/profile
# set java environment
export JAVA_HOME=/opt/modules/jdk1..0_131
export PATH=$PATH:$JAVA_HOME/bin
(2)使环境变量的 配置生效
# source /etc/profile
(3)执行java命令,检验配置是否生效
# java -version
java version "1.8.0_131"
Java(TM) SE Runtime Environment (build 1.8.0_131-b11)
Java HotSpot(TM) -Bit Server VM (build 25.131-b11, mixed mode)
8.解压hadoop安装包
$ tar -zxvf hadoop-2.6..tar.gz -C /opt/modules/
9.在etc/hadoop/hadoop-env.sh文件中设置JAVA_HOME
export JAVA_HOME=/opt/modules/jdk1..0_131
10.默认情况下,Hadoop配置为以非分布式模式运行,作为单个Java进程,
本地模式:mapreduce程序运行在本地,只需启动JVM
以下示例复制未打包的conf目录以用作输入,然后查找并显示给定正则表达式的每个匹配项。输出被写入给定的输出目录。
$ mkdir input
$ cp etc/hadoop/*.xml input
$ bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.6.5.jar grep input output 'dfs[a-z.]+'
$ cat output/*
依次执行上述命令后如果没有报错,则说明mapreduce程序运行成功
11.NameNode,DataNode,HDFS文件系统配置
(1)etc/hadoop/core-site.xml
<configuration>
<property>
<name>fs.defaultFS</name>
<!-- 如果没有配置,默认会从本地文件系统读取数据,步骤11就是读取本地文件系统的数据 -->
<value>hdfs://hadoop01.zjl.com:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<!-- hadoop文件系统依赖的基础配置,很多路径都依赖它。如果hdfs-site.xml中不配置namenode和datanode的存放位置,默认就放在这个路径中 -->
<value>/opt/modules/hadoop-2.6.5/data/tmp</value>
</property>
</configuration>
(2)创建目录/opt/modules/hadoop-2.6.5/data/tmp
$ mkdir -p data/tmp
(3)etc/hadoop/hdfs-site.xml
<configuration>
<property>
<name>dfs.replication</name>
<value></value>
</property>
</configuration>
12.执行
(1)格式化文件系统:
$ bin/hdfs namenode -format
(2)启动NameNode守护进程和DataNode守护进程:
$ sbin/start-dfs.sh
(3)执行jps命令查询java守护进程,若出现NameNode,DataNode,SecondaryNameNode等进程,则启动成功
$ jps
Jps
NameNode
DataNode
SecondaryNameNode
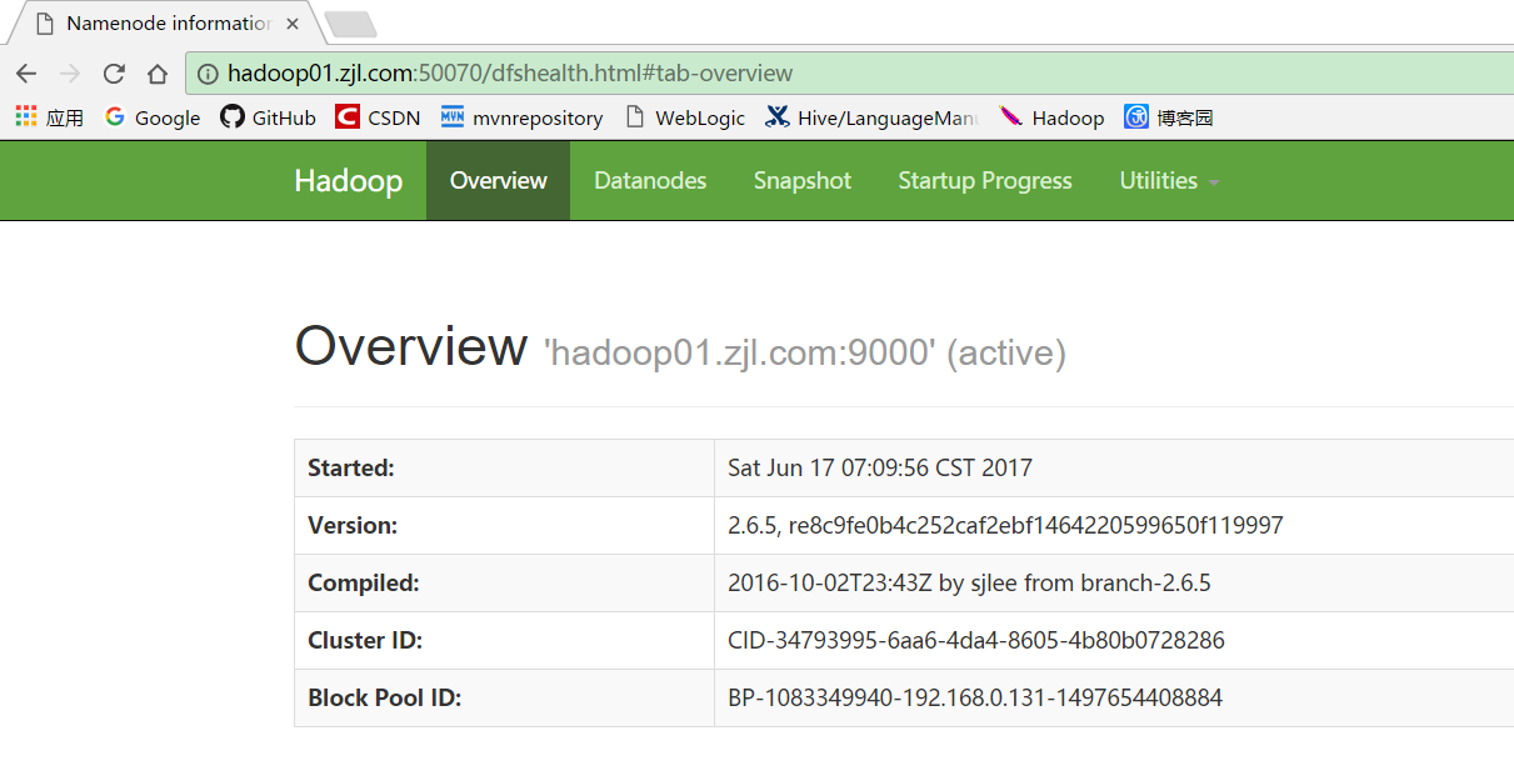
(4)在浏览器地址栏输入http://hadoop01.zjl.com:50070,回车,出现下图所示页面
13.单节点上的YARN的配置
(1)在etc/hadoop/yarn-env.sh文件中配置export JAVA_HOME=/opt/modules/jdk1.8.0_131
(2)etc/hadoop/yarn-site.xml
<configuration>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>hadoop01.zjl.com</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.log-aggregation-enable</name>
<!-- yarn的日志聚集 -->
<value>true</value>
</property>
<property>
<name>yarn.log-aggregation.retain-seconds</name>
<!-- yarn的日志聚集 -->
<value>10080</value>
</property>
</configuration>
(3)将etc/hadoop/slaves文件中的localhost换成主机名hadoop01.zjl.com,slaves表示从节点,指向DataNode和NodeManager所在的机器
(4)启动ResourceManager守护程序和NodeManager守护程序:
$ sbin/start-yarn.sh
(5)执行jps命令查询java守护进程,若出现了NodeManager和NameNode进程,说明yarn启动成功
$ jps
NodeManager
NameNode
Jps
DataNode
SecondaryNameNode
ResourceManager
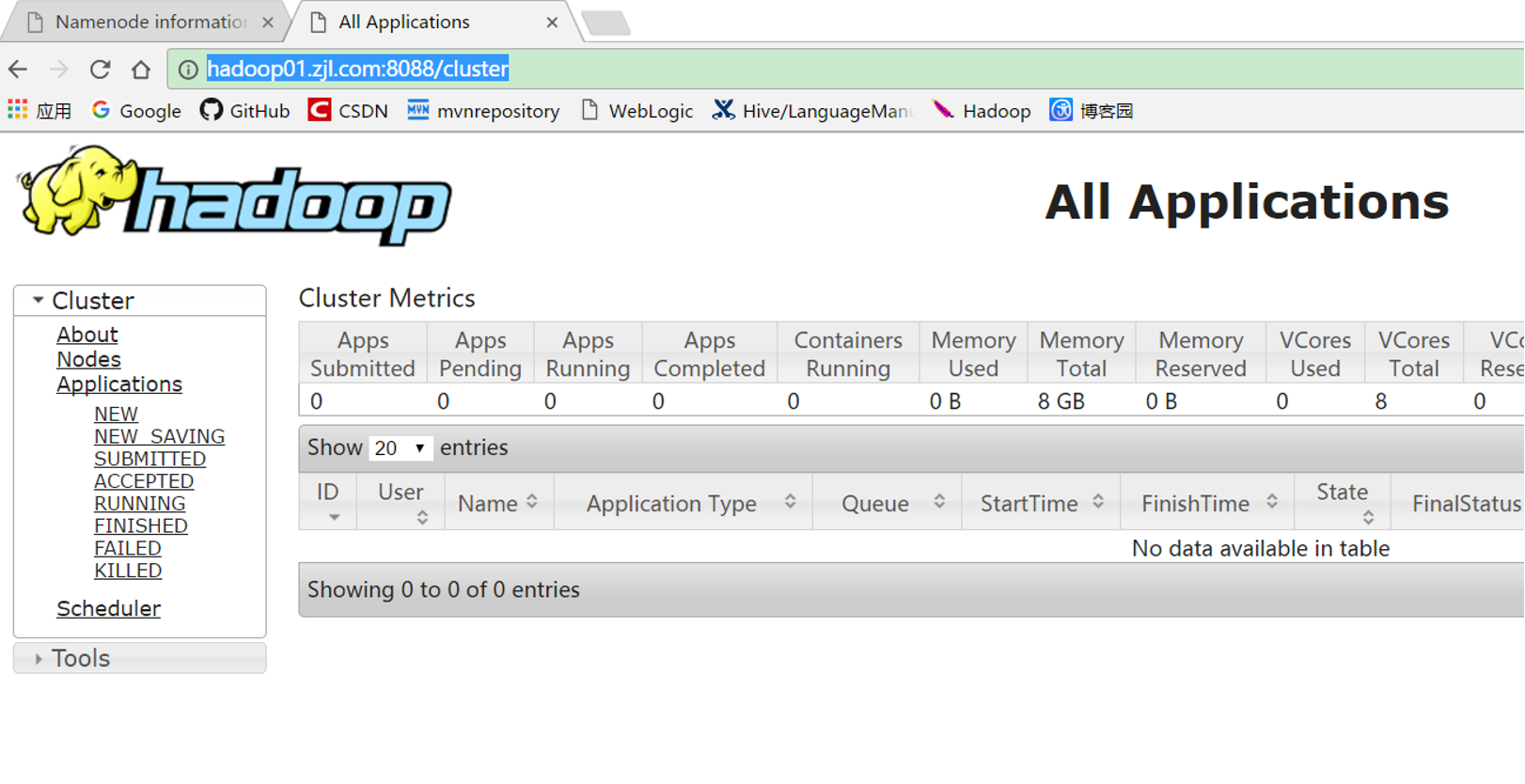
(6)在浏览器地址栏输入http://hadoop01.zjl.com:8088/cluster,回车,出现下图所示页面
14.使Mapreduce能够在yarn上运行
(1)在etc/hadoop/mapred-env.sh文件中配置export JAVA_HOME=/opt/modules/jdk1.8.0_131
(2)将etc/hadoop/mapred-site.xml.template重命名为mapred-site.xml,添加配置
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
(3)在yarn上运行MapReduce示例程序,如果没报错,则MapReduce程序启动成功
$ hdfs dfs -mkdir -p input
$ hdfs dfs -put $HADOOP_HOME/etc/hadoop/*.xml input
$ yarn jar $HADOOP_HOME/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.6.5.jar grep input output 'dfs[a-z.]+'
hadoop伪分布式环境搭建的更多相关文章
- 【Hadoop离线基础总结】CDH版本Hadoop 伪分布式环境搭建
CDH版本Hadoop 伪分布式环境搭建 服务规划 步骤 第一步:上传压缩包并解压 cd /export/softwares/ tar -zxvf hadoop-2.6.0-cdh5.14.0.tar ...
- CentOS7下Hadoop伪分布式环境搭建
CentOS7下Hadoop伪分布式环境搭建 前期准备 1.配置hostname(可选,了解) 在CentOS中,有三种定义的主机名:静态的(static),瞬态的(transient),和灵活的(p ...
- 《OD大数据实战》Hadoop伪分布式环境搭建
一.安装并配置Linux 8. 使用当前root用户创建文件夹,并给/opt/下的所有文件夹及文件赋予775权限,修改用户组为当前用户 mkdir -p /opt/modules mkdir -p / ...
- Hadoop伪分布式环境搭建+Ubuntu:16.04+hadoop-2.6.0
Hello,大家好 !下面就让我带大家一起来搭建hadoop伪分布式的环境吧!不足的地方请大家多交流.谢谢大家的支持 准备环境: 1, ubuntu系统,(我在16.04测试通过.其他版本请自行测试, ...
- hadoop伪分布式环境搭建之linux系统安装教程
本篇文章是接上一篇<超详细hadoop虚拟机安装教程(附图文步骤)>,上一篇有人问怎么没写hadoop安装.在文章开头就已经说明了,hadoop安装会在后面写到,因为整个系列的文章涉及到每 ...
- Hadoop学习笔记1:伪分布式环境搭建
在搭建Hadoop环境之前,请先阅读如下博文,把搭建Hadoop环境之前的准备工作做好,博文如下: 1.CentOS 6.7下安装JDK , 地址: http://blog.csdn.net/yule ...
- 【Hadoop】伪分布式环境搭建、验证
Hadoop伪分布式环境搭建: 自动部署脚本: #!/bin/bash set -eux export APP_PATH=/opt/applications export APP_NAME=Ares ...
- Hadoop2.5.0伪分布式环境搭建
本章主要介绍下在Linux系统下的Hadoop2.5.0伪分布式环境搭建步骤.首先要搭建Hadoop伪分布式环境,需要完成一些前置依赖工作,包括创建用户.安装JDK.关闭防火墙等. 一.创建hadoo ...
- hive-2.2.0 伪分布式环境搭建
一,实验环境: 1, ubuntu server 16.04 2, jdk,1.8 3, hadoop 2.7.4 伪分布式环境或者集群模式 4, apache-hive-2.2.0-bin.tar. ...
随机推荐
- 升讯威微信营销系统开发实践:(5) Github 源码:微信接口的 .NET 封装。
微信开发系列教程,将以一个实际的微信平台项目为案例,深入浅出的讲解微信开发.应用各环节的实现方案和技术细节. 本系列教程的最终目标是完成一个功能完善并达到高可用性能指标的微信管理软件,所以除了与微信本 ...
- web乱码解决了
web容易乱码,最近有乱码了,透死了! 搞了半天,终于好了: String comment = new String(request.getParameter("comment") ...
- 通过rpm 安装MYSQL
1.MYSQL Server端安装: 2.MYSQL client 安装 3.设置MYSQL密码(安装了MySql客户端才可以执行) ' 4.登录MYSQL mysql 的最简单的安装方法啦
- 在CentOS上使用Jexus托管运行 ZKEACMS
ZKEACMS Core 是基于 .net core 开发的,可以在 windows, linux, mac 上跨平台运行,接下来我们来看看如何在 CentOS 上使用Jexus托管运行 ZKEACM ...
- protobuf 系列 ---------下载、编译与使用
protobuf是谷歌开发并开源的二进制序列化工具,比常用的xml,json体积更小,解析速度更快. 目前,手头上的项目有涉及到这个工具,打算仔细研究一番,顺带记录遇到的问题,解决方法,时间足够的话, ...
- Python下划线的使用
References: [1]. http://python.jobbole.com/81129/ 本文将讨论Python中下划线(_)字符的使用方法.我们将会看到,正如Python中的很多事情,下划 ...
- OpenGL: Rotation vector sensor of Android and Device motion of iOS
为了实现一个全景图片展示的功能,需要借助手机的姿态传感器,实现一个这样的功能:当手机旋转时,视角也跟着旋转(读者若理解不能,可以参考下现在流行的 VR 应用,使用陀螺仪模式时的效果,亦可称作" ...
- (数字IC)低功耗设计入门(五)——RTL级低功耗设计(续)
二.RTL级低功耗设计(续) 前面一篇博文我记录了操作数隔离等低功耗设计,这里就主要介绍一下使用门控时钟进行低功耗设计. (4)门控时钟 门控时钟在我的第一篇博客中有简单的描述,这里就进行比较详细的描 ...
- Weighted Effect Coding: Dummy coding when size matters
If your regression model contains a categorical predictor variable, you commonly test the significan ...
- MyBatis_Generator插件的安装以及简单使用
MyBatis_Generator_1.3.1.zip 1 下载安装包 安装包名称:MyBatis_Generator_1.3.1.zip 2 在Eclipse上进行安装 l ...