R formulas in Spark and un-nesting data in SparklyR: Nice and handy!
Intro
In an earlier post I talked about Spark and sparklyR and did some experiments. At my work here at RTL Nederland we have a Spark cluster on Amazon EMR to do some serious heavy lifting on click and video-on-demand data. For an R user it makes perfectly sense to use Spark through the sparklyRinterface. However, using Spark through the pySparkinterface certainly has its benefits. It exposes much more of the Spark functionality and I find the concept of ML Pipelinesin Spark very elegant.
In using Spark I like to share two little tricks described below with you.
The RFormula feature selector
As an R user you have to get used to using Spark through pySpark, moreover, I had to brush up some of my rusty Python knowledge. For training machine learning models there is some help though by using an RFormula
R users know the concept of model formulae in R, it can be handy way to formulate predictive models in a concise way. In Spark you can also use this concept, only a limited set of R operators are available (+, – , . and :) , but it is enough to be useful. The two figures below show a simple example.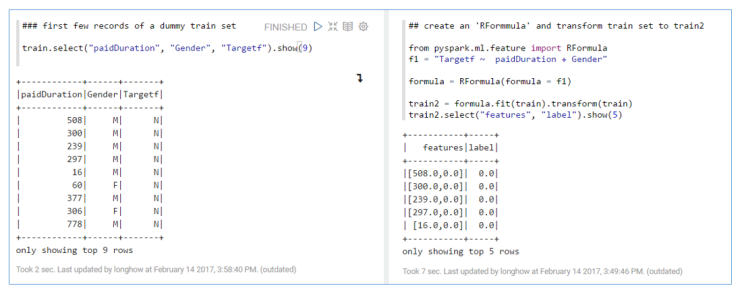
|
1
2
3
4
|
from pyspark.ml.feature import RFormulaf1 = "Targetf ~ paidDuration + Gender "formula = RFormula(formula = f1)train2 = formula.fit(train).transform(train) |
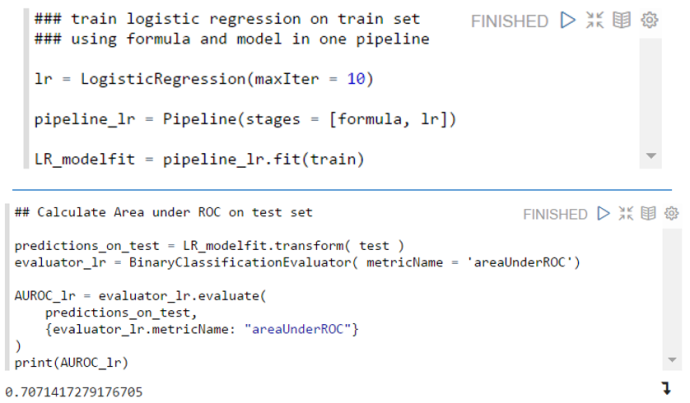
A handy thing about an RFormula in Spark is (just like using a formula in R in lm and some other modeling functions) that string features used in an RFormula will be automatically onehot encoded, so that they can be used directly in the Spark machine learning algorithms.
Nested (hierarchical) data in sparklyR
Sometimes you may find your self with nested hierarchical data. In pySpark you can flatten this hierarchy if needed. A simple example, suppose you read in a parquet file and it has the following structure: Then to flatten the data you could use:
Then to flatten the data you could use: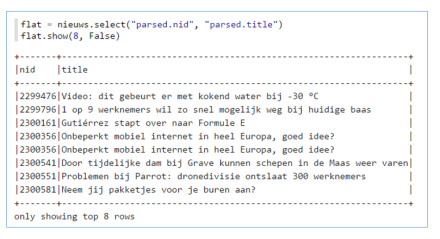 In SparklyR however, reading the same parquet file results in something that isn’t useful to work with at first sight. If you open the table viewer to see the data, you will see rows with: <environment>.
In SparklyR however, reading the same parquet file results in something that isn’t useful to work with at first sight. If you open the table viewer to see the data, you will see rows with: <environment>.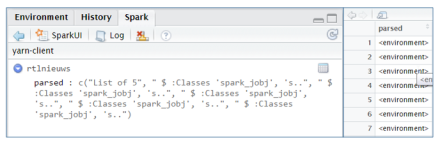 Fortunately, the facilities used internally by sparklyR to call Spark are available to the end user. You can invoke more methods in Spark if needed. So we can invoke the select and col method our self to flatten the hierarchy.
Fortunately, the facilities used internally by sparklyR to call Spark are available to the end user. You can invoke more methods in Spark if needed. So we can invoke the select and col method our self to flatten the hierarchy.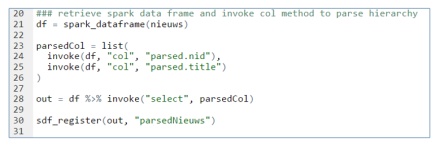 After registering the output object, it is visible in the Spark interface and you can view the content.
After registering the output object, it is visible in the Spark interface and you can view the content.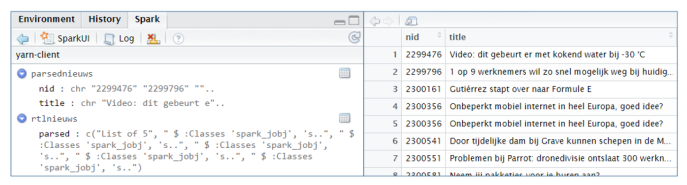
Thanks for reading my two tricks. Cheers, Longhow.
转自:https://longhowlam.wordpress.com/2017/02/15/r-formulas-in-spark-and-un-nesting-data-in-sparklyr-nice-and-handy/
R formulas in Spark and un-nesting data in SparklyR: Nice and handy!的更多相关文章
- Introducing DataFrames in Apache Spark for Large Scale Data Science(中英双语)
文章标题 Introducing DataFrames in Apache Spark for Large Scale Data Science 一个用于大规模数据科学的API——DataFrame ...
- 大数据工具比较:R 语言和 Spark 谁更胜一筹?
本文有两重目的,一是在性能方面快速对比下R语言和Spark,二是想向大家介绍下Spark的机器学习库 背景介绍 由于R语言本身是单线程的,所以可能从性能方面对比Spark和R并不是很明智的做法.即使这 ...
- Using Apache Spark and MySQL for Data Analysis
What is Spark Apache Spark is a cluster computing framework, similar to Apache Hadoop. Wikipedia has ...
- 【译】Using .NET for Apache Spark to Analyze Log Data
.NET for Spark可用于处理成批数据.实时流.机器学习和ad-hoc查询.在这篇博客文章中,我们将探讨如何使用.NET for Spark执行一个非常流行的大数据任务,即日志分析. 1 什么 ...
- Spark性能优化之道——解决Spark数据倾斜(Data Skew)的N种姿势
原创文章,同步首发自作者个人博客转载请务必在文章开头处注明出处. 摘要 本文结合实例详细阐明了Spark数据倾斜的几种场景以及对应的解决方案,包括避免数据源倾斜,调整并行度,使用自定义Partitio ...
- R class of subset of matrix and data.frame
a = matrix( c(2, 4, 3, 1, 5, 7), # the data elements nrow=2, # number of rows ...
- Spark性能调优之道——解决Spark数据倾斜(Data Skew)的N种姿势
原文:http://blog.csdn.net/tanglizhe1105/article/details/51050974 背景 很多使用Spark的朋友很想知道rdd里的元素是怎么存储的,它们占用 ...
- Spark SQL is a Spark module for structured data processing.
http://spark.apache.org/docs/latest/sql-programming-guide.html
- Managing Spark data handles in R
When working with big data with R (say, using Spark and sparklyr) we have found it very convenient t ...
随机推荐
- 自然梯度(Natural Gradient)
自然梯度(Natural Gradient)
- 跟着刚哥梳理java知识点——流程控制(六)
分支结构(if…else .switch) 1.if else 语句格式 if(条件表达式){ 执行代码块; } else if(条件表达式){ 执行代码块; } else{ 执行代码块; } 2.s ...
- STAR法则的感想
STAR法则百度百科上被解释为,面试官用于收集面试者信息的工具,而我个人理解,它更像是一个表达技巧,叙述结构,我们先来看看什么是STAR法则: STAR法则,即为Situation Task Acti ...
- spring项目log4j使用入门
log4j是Java开发中经常使用的一个日志框架,功能强大,配置灵活,基本上可以满足项目开发中对日志功能的大部分需求.我前后经历了四五个项目,采用的日志框架都是log4j,这也反应了log4j受欢迎的 ...
- 关于sql、mysql语句的模糊查询分类与详解,包括基本用法和mapper.xml文件里插入写法
欢迎猿类加qq:2318645572,共同学习进步 实际例子: ssm框架:service业务层->dao层->mappers.xml->junit/test测试 1:service ...
- 初识bd时的一些技能小贴士
既然小豆腐如此给力,而且充分的利用主动学习的优势,已经有了迅速脑补,压倒式的优势,不过这只是表面而已,一切才刚刚开始,究竟鹿死谁手,还有待验证. 以上可以看到,小豆腐为什么拼命的要teach我们了么, ...
- canvas绘制一定数目的圆(均分)
绘制多圆 2016年5月24日12:12:26 绘制一定数目(num)颜色随机的小圆,围成一个大圆.根据num完全自动生成,且小圆自动均分大圆路径(num≥20). 效果: 前置技能:(1).Canv ...
- 2017年陕西省网络空间安全技术大赛——种棵树吧——Writeup
2017年陕西省网络空间安全技术大赛——种棵树吧——Writeup 下载下来的zip解压得到两个jpg图片,在Kali中使用binwalk查看文件类型如下图: 有两个发现: 1111.jpg 隐藏了一 ...
- MongoDB系列:把mongodb作为windows的服务来启动
1.首先切换到mongodb安装目录下的bin目录,在控制台直接运行以下命令 "C:\Program Files\MongoDB\Server\3.0\bin\mongod.exe" ...
- springmvc学习笔记(简介及使用)
springmvc学习笔记(简介及使用) 工作之余, 回顾了一下springmvc的相关内容, 这次也为后面复习什么的做个标记, 也希望能与大家交流学习, 通过回帖留言等方式表达自己的观点或学习心得. ...