递归神经网络(Recurrent Neural Networks,RNN)
在深度学习领域,传统的多层感知机(MLP)具有出色的表现,取得了许多成功,它曾在许多不同的任务上——包括手写数字识别和目标分类上创造了记录。甚至到了今天,MLP在解决分类任务上始终都比其他方法要略胜一筹。尽管如此,大多数专家还是会达成共识:MLP可以实现的功能仍然相当有限。究其原因,人类的大脑有着惊人的计算功能,而“分类”任务仅仅是其中很小的一个组成部分。我们不仅能够识别个体案例,更能分析输入信息之间的整体逻辑序列。这些信息序列富含有大量的内容,信息彼此间有着复杂的时间关联性,并且信息长度各种各样。这是传统的MLP所无法解决的,RNN 正式为了解决这种序列问题应运而生,其关键之处在于当前网络的隐藏状态会保留先前的输入信息,用来作当前网络的输出。
许多任务需要处理序列数据,比如Image captioning, speech synthesis, and music generation 均需要模型生成序列数据,其他领域比如 time series prediction, video analysis, and musical information retrieval 等要求模型的输入为序列数据,其他任务比如 机器翻译,人机对话,controlling a robot 的模型要求输入输出均为序列数据。 RNN 模型可以用来处理序列数据, RNN 包含了大量参数,且难于训练(时间维度的 vanishing/exploding),所以出现一系列对 RNN 优化 ,比如网络结构、求解算法与并行化。今年来 bidirectional RNN (BRNN)与 LSTM 在 image captioning, language translation, and handwriting recognition 这几个方向上有了突破性进展 。下面从 RNN 开始来逐一介绍这些网络模型。
RNN 的结构不同于 MLP ,输入层与来自序列中上一元素隐层的信号共同作用到当前的隐藏层,如下图所示:

下图能更清楚的展示 RNN 的结构:
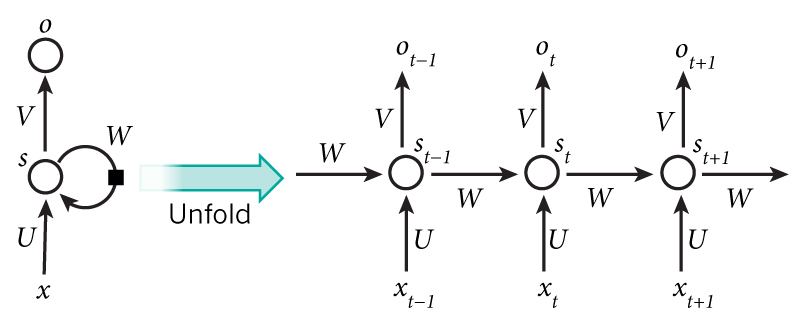 看下面关于 RNN BP分析之前,请确保之前看过 多层感知机及其BP算法(Multi-Layer Perceptron),此文为 RNN BP 的基础,现在来看 RNN 的 BP 算法,对于长度为 $T$ 的序列 $x$ ,RNN 的输入层大小为 $I$ ,隐层大小为 $H$ ,输出层大小为 $K$ ,可以得到上图中三个矩阵的维度分别为 : $U \in \mathbb{R}^{I \times H} , W \in \mathbb{R}^{H \times H} , V \in \mathbb{R}^{H \times K} $ ,这里 $x^t$ 代表序列第 $t$ 项 的输入, $a^t$ 代表第 $t$ 项隐层的输入,$b^t$ 代表对 $a^t$ 做非线性激活也即为神经网络的输出 ,这里 $a^t$ 由输入层 $x^t$ 与 上一层隐层的输出 $b^{t-1}$ 共同决定:
看下面关于 RNN BP分析之前,请确保之前看过 多层感知机及其BP算法(Multi-Layer Perceptron),此文为 RNN BP 的基础,现在来看 RNN 的 BP 算法,对于长度为 $T$ 的序列 $x$ ,RNN 的输入层大小为 $I$ ,隐层大小为 $H$ ,输出层大小为 $K$ ,可以得到上图中三个矩阵的维度分别为 : $U \in \mathbb{R}^{I \times H} , W \in \mathbb{R}^{H \times H} , V \in \mathbb{R}^{H \times K} $ ,这里 $x^t$ 代表序列第 $t$ 项 的输入, $a^t$ 代表第 $t$ 项隐层的输入,$b^t$ 代表对 $a^t$ 做非线性激活也即为神经网络的输出 ,这里 $a^t$ 由输入层 $x^t$ 与 上一层隐层的输出 $b^{t-1}$ 共同决定:
\[a_h^t =\sum_iw_{ih}x_i^t +\sum_{h'}w_{h'h}b_{h'}^{t-1}\]
\[b_h^t = f(a_h^t)\]
这里 序列从状态 $t=1$开始,一般设置 $b^0 = 0 $ 即可,接下来将隐层传导至输出层即可,通常 RNN 的输出层采用与传统 MLP 的类似的 $softmax$ 来进行分类任务.即输出层的输出为:
\[a_k^t = \sum_hw_{hk}b_h^t\]
\[y_k^t = \frac{e^{a_k^t}}{\sum_j e^{a_j^t}}\]
注意 RNN 中由于输入时叠加了之前的信号,所以反向传导时不同于传统的 MLP ,因为对于时刻 $t$ 的输入层,其残差不仅来自于输出,还来自于之后的隐层入下图所示:
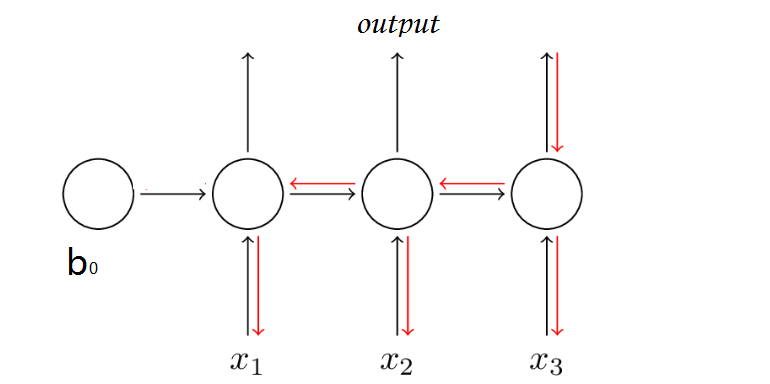
时刻 $t$ ,RNN 输出层的算残差项同 MLP 为 $ \delta_k^t = y_k^t-z^t_k$,由于前向传导时隐层需要接受上一个时刻隐层的信号,所以反向传导时根据 BPTT 算法,隐层还需接收下一时刻的隐层的反馈:
\[\delta_h^t = f'(a_h^t) \left (\sum_k\delta_k^tw_{hk} + \sum_{h'} \delta^{t+1}_{h'}w_{hh'} \right )\]
当序列长度为 $T$ ,则残差 $\delta^{T+1}$ 均为 0 。并且整个网络其实就只有一套参数 $U$、$V$、$W$ , 对于时刻 $t$ 其倒数分别为:
\[U: \ \frac{\partial O}{\partial w_{ih}}= \frac{\partial O}{\partial a_h^t}\frac{\partial a_h^t}{\partial w_{ih}}=\delta_h^tx_i^t\]
\[V: \ \frac{\partial O}{\partial w_{hk}}= \frac{\partial O}{\partial a_k^t}\frac{\partial a_k^t}{\partial w_{hk}}=\delta_k^tb_h^t\]
\[W: \ \frac{\partial O}{\partial w_{h'h}}= \frac{\partial O}{\partial a_h^t}\frac{\partial a_h^t}{\partial w_{h'h}}=\delta_k^tb_{h'}^t \]
为了方便表示,写成统一的形式(假设对输入层有 $x_i^t = a_i^t =b_i^t$):
\[\frac{\partial O}{\partial w_{hij}}= \frac{\partial O}{\partial a_j^t}\frac{\partial a_j^t}{\partial w_{ij}}=\delta_j^tb_i^t\]
最后,由于 RNN 的递归性 ,对于时刻 $t = 1,2,...,T$ ,将其进行求和即可,下面为最终得 RNN 网络的关于权重参数的导数:
\[\frac{\partial O}{\partial w_{ij}}= \sum_t\frac{\partial O}{\partial a_j^t}\frac{\partial a_j^t}{\partial w_{ij}} = \sum _t \delta_j^tb_i^t\]
Bidirectional RNNs
RNN 中对于当前时刻 t 通常会考虑之前时刻的信息而没有考虑下文的信息,Bidirectional RNNs 克服了这一缺点,其引入了对下文的考虑,其结构如下:
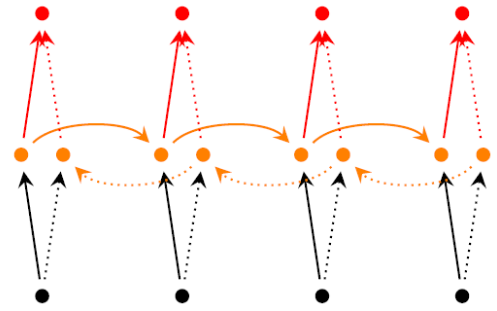
可见 BRNN 引入了一套额外的隐层,但是输入与输出层是共享的,多了一个隐层意味着多了三套参数分别为 $U'$、$V'$、$W'$ 。BRNN 的训练算法类似于 RNN ,forward pass 的过程如下:

backward pass 的过程如下:

计算完残差后,分别对前向参数 $U$、$V$、$W$ 后向参数 $U'$、$V'$、$W'$ 求导即可,至此 BRNN 的训练算法介绍完毕, 目前 ,BRNN 在 NLP 的序列标注任务中取得了极大的成功。
递归神经网络(Recurrent Neural Networks,RNN)的更多相关文章
- 循环神经网络(Recurrent Neural Networks, RNN)介绍
目录 1 什么是RNNs 2 RNNs能干什么 2.1 语言模型与文本生成Language Modeling and Generating Text 2.2 机器翻译Machine Translati ...
- 递归神经网络(Recursive Neural Network, RNN)
信息往往还存在着诸如树结构.图结构等更复杂的结构.这就需要用到递归神经网络 (Recursive Neural Network, RNN),巧合的是递归神经网络的缩写和循环神经网络一样,也是RNN,递 ...
- The Unreasonable Effectiveness of Recurrent Neural Networks (RNN)
http://karpathy.github.io/2015/05/21/rnn-effectiveness/ There’s something magical about Recurrent Ne ...
- Recurrent Neural Networks(RNN) 循环神经网络初探
1. 针对机器学习/深度神经网络“记忆能力”的讨论 0x1:数据规律的本质是能代表此类数据的通用模式 - 数据挖掘的本质是在进行模式提取 数据的本质是存储信息的介质,而模式(pattern)是信息的一 ...
- 《转》循环神经网络(RNN, Recurrent Neural Networks)学习笔记:基础理论
转自 http://blog.csdn.net/xingzhedai/article/details/53144126 更多参考:http://blog.csdn.net/mafeiyu80/arti ...
- 循环神经网络(RNN, Recurrent Neural Networks)介绍(转载)
循环神经网络(RNN, Recurrent Neural Networks)介绍 这篇文章很多内容是参考:http://www.wildml.com/2015/09/recurrent-neur ...
- 循环神经网络(RNN, Recurrent Neural Networks)介绍
原文地址: http://blog.csdn.net/heyongluoyao8/article/details/48636251# 循环神经网络(RNN, Recurrent Neural Netw ...
- 课程五(Sequence Models),第一 周(Recurrent Neural Networks) —— 1.Programming assignments:Building a recurrent neural network - step by step
Building your Recurrent Neural Network - Step by Step Welcome to Course 5's first assignment! In thi ...
- 第十四章——循环神经网络(Recurrent Neural Networks)(第一部分)
由于本章过长,分为两个部分,这是第一部分. 这几年提到RNN,一般指Recurrent Neural Networks,至于翻译成循环神经网络还是递归神经网络都可以.wiki上面把Recurrent ...
- 第十四章——循环神经网络(Recurrent Neural Networks)(第二部分)
本章共两部分,这是第二部分: 第十四章--循环神经网络(Recurrent Neural Networks)(第一部分) 第十四章--循环神经网络(Recurrent Neural Networks) ...
随机推荐
- 深入了解linux下的last命令及其数据源
http://www.9usb.net/200902/linux-last.html http://blog.csdn.net/chaofanwei/article/details/11826567
- 关于在linux下清屏的几种技巧
在windows的DOS操作界面里面,清屏的命令是cls,那么在linux 里面的清屏命令是什么呢?下面笔者分享几种在linux下用过的清屏方法. 1.clear命令.这个命令将会刷新屏幕,本质上只是 ...
- ANDROID STUDIO, GRADLE AND NDK INTEGRATION
Originally posted on:http://ph0b.com/android-studio-gradle-and-ndk-integration/ With the recent chan ...
- mfc和win32区别
Win32通常是指sdk编程方法,app没有被封装,开发人员需要自己搭程序框架:mfC则是以C++类的形式封装了Windows的API,并且包含一个应用程序框架,以减少应用程序开发人员的工作量 (整理 ...
- Android核心分析之十七电话系统之rilD
Android电话系统之-rild Rild是Init进程启动的一个本地服务,这个本地服务并没有使用Binder之类的通讯手段,而是采用了socket通讯这种方式.RIL(Radio Interfac ...
- OneAPM:打造云时代的应用性能管控平台
在2015年大连市CIO信息化年会的现场,记者与OneAPM东北区总经理佟维针对云时代的企业系统应用性能的管理控制进行了简短交流.北京蓝海讯通科技股份有限公司,即OneAPM是中国基础软件领域的新兴领 ...
- React组件-mixin
一.组件 二.代码 <!DOCTYPE html> <html lang="zh-cn"> <head> <meta charset=&q ...
- Bootstrap下拉菜单dropdown-menu
1.步骤 (1)要做为下拉菜单的li增加class="dropdown" (2)为li中文字添加超链接<a data-toggle="dropdown" ...
- PHPStorm IDE 快捷键(MAC)
⌘——Command ⌃ ——Control ⌥——Option/Alt ⇧——Shift ⇪——Caps Lock fn——功能键就是fn 编辑 Command+alt+T 用 (if..else, ...
- JVM垃圾回收机制总结(2) :基本算法概述
1.引用计数收集器 (Reference Counting) 引用计数是垃圾收集的早期策略.在这种方法中,堆中每一个对象都有一个引用计数.一个对象被创建了,并且指向该对象的引用被分配给一个变量,这个对 ...