CUDA学习笔记(二)【转】
来源:http://luofl1992.is-programmer.com/posts/38847.html
编程语言的特点是要实践,实践多了才有经验。很多东西书本上讲得不慎清楚,不妨自己用代码实现一下。
作为例子,我参考了书本上的矩阵相乘的例子,这样开始写代码,然后很自然地出现了各种问题。
以下的内容供大家学习参考,有问题可以留言与我反馈。
开始学着使用 CUDA,实现一个矩阵乘法运算。
首先我们要定义一个矩阵的结构体,话说CUDA是否支持结构体作为设备端的函数的参数呢?
不妨都一股脑试验一下。
1、安装CUDA 5.0
在NVIDIA CUDA官方网站下载对应自己操作系统的最新版 CUDA,
为什么要最新版本呢,一方面技术一直更新,自己要保持潮流嘛~(程序员的苦逼之处也在此)
更新的版本一般实现功能上更加完善,BUG更少。
废话不多说,去这里下载:
最新版的CUDA不像4.0版本分ToolKit、SDK、Samples,可以说简化了安装复杂度。
安装完毕可以看看示例,路径为
安装目录 \\ nvToolsExt\samples
比如我的为:C:\Program Files\NVIDIA GPU Computing Toolkit\nvToolsExt\samples
2、创建一个新的CUDA项目
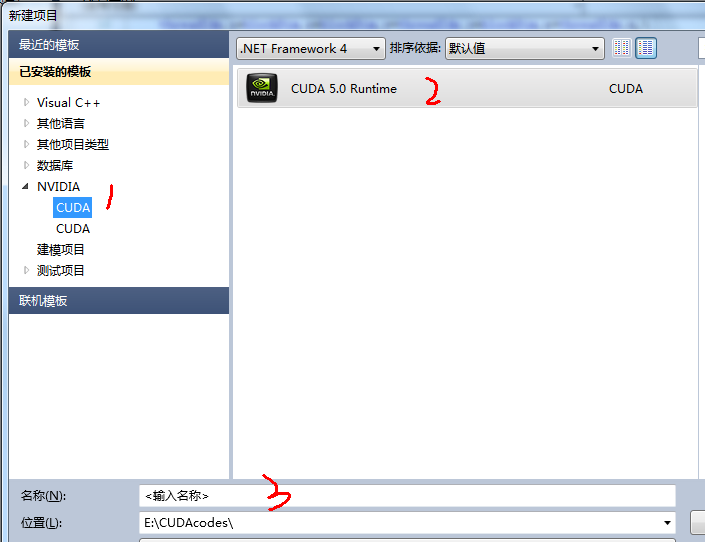
CUDA 5.0不需要再额外安装 cudaVSWizard了,安装完成后,VS中会出现这样的东西,
新建 ===》 项目 ===》 NVIDIA =====》 CUDA
填写项目名称,然后就会自动生成一个kernal.cu文件,编辑这个文件就可以了。
如果代码比较复杂,可以弄多个文件,但是cuda目前所有的设备代码似乎必须写在一个源文件中,不能使用常用的函数声明+其他文件实现的方式。如果存在多个cu文件,可以用#include "axxx.cu"指令打包成一个cu源文件。
这个后续还要测试。贴一张图说明一下,我的为VS2010:
3、修改代码
关于矩阵运算,比例子复杂一些。这里先给出其核心代码,
相信有良好C语言基础的人能够轻松看懂这个函数而不需要我的注释。
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
|
// 矩阵乘法,C = A * B__global__ void gpuMatrixMul(const Matrix A, const Matrix B, Matrix C){ int row = blockIdx.x * blockDim.x + threadIdx.x; int col = blockIdx.y * blockDim.y + threadIdx.y; float ret = 0; if ( row >= A.row || col >= B.col || A.col != B.row ) return; float *ma = A.ele + row * A.stride; float *mb = B.ele + col; for ( int i = 0, n = A.col, stride = B.stride; i < n; i++ ) { ret += ma[ i ] * mb[ i * stride ]; } C.ele[row * C.stride + col] = ret;}/*__global__ void gpuMatrixMul(const Matrix *A, const Matrix *B, Matrix *C){ int row = blockIdx.x * blockDim.x + threadIdx.x; int col = blockIdx.y * blockDim.y + threadIdx.y; float ret = 0; if ( row >= A->row || col >= B->col || A->col != B->row ) return; float *ma = A->ele + row * A->stride; float *mb = B->ele + col; for ( int i = 0, n = A->col, stride = B->stride; i < n; i++ ) { ret += ma[ i ] * mb[ i * stride ]; } C->ele[row * C->stride + col] = ret;}*/ |
其中结构体Matrix的定义如下:
|
1
2
3
4
5
6
7
8
|
// 矩阵结构体typedef struct MartixTag{ float *ele; // 一维数组,保存矩阵的元素 size_t col; // 矩阵的列数 size_t row; // 矩阵的行数 size_t stride; // 矩阵一行数据的数量,为了方便内存对齐,2^n}Matrix; |
实际测试表明,上述代码中,采用指针传递结构体参数时,运算结果会不正确。
这点在我们以后写CUDA函数的时候应该注意,我的理解是这样子,不知道大家怎么看:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
|
// (1)设备端分配的显存空间,不能直接在CPU上访问;// (2)主机端分配的内存空间,不能在设备端使用;// (3)需要使用时,需要使用 CUDA的相关函数。cudaError_t cudaMalloc(void **p, size_t size);/* 这个cudaMalloc函数中 参数p指针的指针, 主要是为了能够修改改指针指向的地址,而函数返回类型可以指出是否出现了错误。 这个部分可以再回顾一下指针的概念。*/cudaError_t cudaMemcpy(void *dst, void *src, size_t cnt, cudaMemoryKind kind);/* 这个cudaMemcpy函数中 cnt指定要复制的内存字节数。 kind指定了拷贝的方向,主要有cudaMemcpyHostToDevice // CPU内存到GPU显存cudaMemcpyDeviceToHost // GPU显存到CPU内存*/ |
4、调试设备端代码
在VS平台上使用,建议安装Nsight,这在官方网站上下载就好了。
需要自己注册一个NVIDIA帐号,然后填写一些信息,
什么?页面全英文看不懂?
慢慢看吧。https://developer.nvidia.com/nvidia-nsight-visual-studio-edition
显卡驱动,一般以前安装很新的版本的,就不用再安装了。
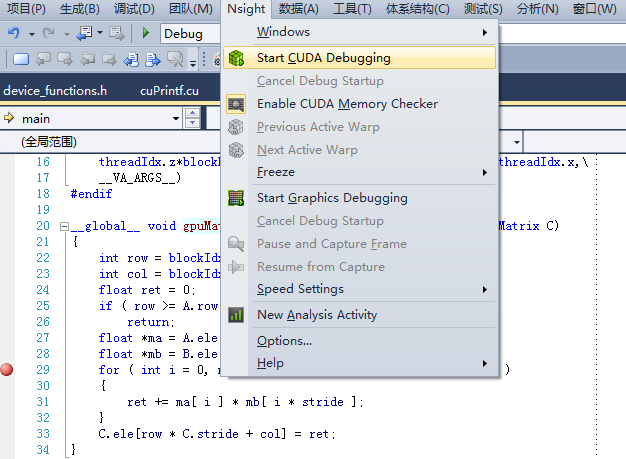
安装一下Nsight,关闭VS,完毕后重新打开时,发现菜单栏里面多了一个选项。
在要调试的设备端代码中按F9设置一个断点,然后选中菜单栏:
Nsight ---> Start CUDA Debuging ---->
就可以看到代码会中断在设备端的代码中了,设置在CPU端代码的断点不会被识别。
5、附录代码
最后附上我的一个成果,按照书上的分块计算矩阵乘法代码,经本人测试无误:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
|
__global__ void gpuMatrixMulB(Matrix A, Matrix B, Matrix C){ if ( blockDim.x != BLOCK_SIZE || blockDim.y != BLOCK_SIZE ) return; // x 横向指向一行 // y 指向列号,数组的第二维 // 访问元素以 C.ele[x][y] 的形式 // 一个thread计算C的一个值 const int bx = blockIdx.x, by = blockIdx.y; const int tx = threadIdx.x, ty = threadIdx.y; // A中第一个子块的起始地址 const int aBegin = A.stride * bx * BLOCK_SIZE; const int aEnd = aBegin + A.col; const int aStep = BLOCK_SIZE; // B中要处理的第一个子块的起始地址 const int bBegin = BLOCK_SIZE * by; const int bEnd = bBegin + B.stride * B.row; const int bStep = BLOCK_SIZE * B.stride; float Csub = 0; // 循环A的一行(by指向最开始),和B的一列(bx指向最开始) for ( int a = aBegin, b = bBegin, i = 0; a < aEnd; a += aStep, b+= bStep, i++ ) { __shared__ float AS[BLOCK_SIZE][BLOCK_SIZE]; __shared__ float BS[BLOCK_SIZE][BLOCK_SIZE]; int na = min(BLOCK_SIZE, aEnd - a); // 对不足一个整块的不用整体复制 if ( tx + bx * BLOCK_SIZE < A.row && ty + a - aBegin < A.col ) AS[tx][ty] = A.ele[a + A.stride * tx + ty]; else AS[ty][tx] = 0; if ( tx * B.stride + b < bEnd && ty + by * BLOCK_SIZE < B.col ) BS[tx][ty] = B.ele[b + B.stride * tx + ty]; else BS[tx][ty] = 0; __syncthreads(); for ( int k = 0 ; k < na; ++k ) { Csub += AS[tx][k] * BS[k][ty]; } __syncthreads(); } if ( by * BLOCK_SIZE + ty > C.col || bx * BLOCK_SIZE + tx > C.row ) return; // C[by*BLOCK + ty][bx * BLOCK + tx] C.ele[ (by * BLOCK_SIZE + ty ) + C.stride * (bx*BLOCK_SIZE + tx) ] = Csub;} |
调用方式如下(对相关参数初始化完毕后执行):
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
|
// 启用 kernel dim3 dimBlock(BLOCK_SIZE, BLOCK_SIZE); dim3 dimGrid( (d_C.row + dimBlock.x - 1) / dimBlock.x, (d_C.col + dimBlock.y - 1) / dimBlock.y); fprintf( stderr, "DimBlock: %d, %d, %d\nDimGrid: %d, %d, %d\n", dimBlock.x, dimBlock.y, dimBlock.z, dimGrid.x, dimGrid.y, dimGrid.z);#if 1 // 不要通过指针参数调用,指针所指向的内存必须要通过显式的内存拷贝 // 才能在GPU中使用 // gpuMatrixMul<<<dimGrid, dimBlock>>>(&d_A, &d_B, &d_C); gpuMatrixMulB<<<dimGrid, dimBlock>>>( d_A, d_B, d_C);#else gpuMatrixMul<<<dimGrid, dimBlock>>>( d_A, d_B, d_C);#endif cudaMemcpy( c.ele, d_C.ele, c.stride * c.row * sizeof(float), cudaMemcpyDeviceToHost ); |
顺便附录一份C源代码计算矩阵乘积,也分享给大家:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
|
int MatMul(const Matrix *a, const Matrix *b, Matrix *pRet){ const size_t row = a->row; const size_t col = b->col; const size_t n = a->col; const size_t stride = b->stride; float const * ma = a->ele; float const * mb = b->ele; float * mRet = pRet->ele; int i = 0, j = 0, k = 0; float ret = 0; if ( a->col != b->row ) return 0; if ( pRet->ele == NULL ) { pRet->col = a->col; pRet->row = b->row; pRet->stride = a->stride; pRet->ele = (float *)malloc( a->stride * sizeof(float) * b->row ); } for ( i = 0; i < row; i++ ) { for ( j = 0; j < col; j++ ) { ret = 0.0; for ( k = 0; k < n; k++ ) { ret += ma[k] * mb[k * stride + j ]; } mRet[j] = ret; } ma += a->stride; mRet += pRet->stride; } return 1;} |
CUDA学习笔记(二)【转】的更多相关文章
- WPF的Binding学习笔记(二)
原文: http://www.cnblogs.com/pasoraku/archive/2012/10/25/2738428.htmlWPF的Binding学习笔记(二) 上次学了点点Binding的 ...
- AJax 学习笔记二(onreadystatechange的作用)
AJax 学习笔记二(onreadystatechange的作用) 当发送一个请求后,客户端无法确定什么时候会完成这个请求,所以需要用事件机制来捕获请求的状态XMLHttpRequest对象提供了on ...
- [Firefly引擎][学习笔记二][已完结]卡牌游戏开发模型的设计
源地址:http://bbs.9miao.com/thread-44603-1-1.html 在此补充一下Socket的验证机制:socket登陆验证.会采用session会话超时的机制做心跳接口验证 ...
- JMX学习笔记(二)-Notification
Notification通知,也可理解为消息,有通知,必然有发送通知的广播,JMX这里采用了一种订阅的方式,类似于观察者模式,注册一个观察者到广播里,当有通知时,广播通过调用观察者,逐一通知. 这里写 ...
- java之jvm学习笔记二(类装载器的体系结构)
java的class只在需要的时候才内转载入内存,并由java虚拟机的执行引擎来执行,而执行引擎从总的来说主要的执行方式分为四种, 第一种,一次性解释代码,也就是当字节码转载到内存后,每次需要都会重新 ...
- Java IO学习笔记二
Java IO学习笔记二 流的概念 在程序中所有的数据都是以流的方式进行传输或保存的,程序需要数据的时候要使用输入流读取数据,而当程序需要将一些数据保存起来的时候,就要使用输出流完成. 程序中的输入输 ...
- 《SQL必知必会》学习笔记二)
<SQL必知必会>学习笔记(二) 咱们接着上一篇的内容继续.这一篇主要回顾子查询,联合查询,复制表这三类内容. 上一部分基本上都是简单的Select查询,即从单个数据库表中检索数据的单条语 ...
- NumPy学习笔记 二
NumPy学习笔记 二 <NumPy学习笔记>系列将记录学习NumPy过程中的动手笔记,前期的参考书是<Python数据分析基础教程 NumPy学习指南>第二版.<数学分 ...
- Learning ROS for Robotics Programming Second Edition学习笔记(二) indigo tools
中文译著已经出版,详情请参考:http://blog.csdn.net/ZhangRelay/article/category/6506865 Learning ROS for Robotics Pr ...
- Redis学习笔记二 (BitMap算法分析与BitCount语法)
Redis学习笔记二 一.BitMap是什么 就是通过一个bit位来表示某个元素对应的值或者状态,其中的key就是对应元素本身.我们知道8个bit可以组成一个Byte,所以bitmap本身会极大的节省 ...
随机推荐
- linux命令存放 bash: xxx command not found
参考资料:http://blog.sina.com.cn/s/blog_688077cf01013qrk.html 提示:bash: xxx command not found 首先就要考虑root ...
- 2013年7月份第3周51Aspx源码发布详情
批量重命名文件工具源码 2013-7-19 [VS2010]功能介绍:这是一个新型的文件重命名,主要用了TreeView(树形视图)来选择文件夹,批量进行文件重命名.其中,有"编号在前,编 ...
- c++父类指针强制转为子类指针后的测试(帮助理解指针访问成员的本质)(反多态)
看下面例子: #include "stdafx.h" #include <iostream> class A { //父类 public: void f() / ...
- SYN Cookie的原理和实现
本文主要内容:SYN Cookie的原理,以及它的内核实现. 内核版本:3.6 SYN Flood 下面这段介绍引用自[1]. SYN Flood是一种非常危险而常见的Dos攻击方式.到目 ...
- <xliff:g>标签
摘要: 这是Android4.3Mms源码中的strings.xml的一段代码: <!--Settings item desciption for integer auto-delete sms ...
- 前App Store高管揭秘:关于“苹果推荐”的七大真相
相信你已经看过很多这样那样关于如何获得苹果商店推荐的攻略了,但其实很多人依然陷入了很大的误区.前不久采访了前App Store团队高管Greg Essig,向各位开发者揭示关于获得苹果推荐的真相. 在 ...
- Js获取URL中的QueryStirng字符串
function GetQueryString(name) { var reg = new RegExp("(^|&)" + name + "=([^&] ...
- HDU 5862(离散化+树状数组)
Problem Counting Intersections 题目大意 给定n条水平或竖直的线段,统计所有线段的交点个数. (n<=100000) 解题分析 首先将线段离散化. 然后将所有线段按 ...
- 清除浮动4-插入多余的div
<!doctype html><html> <head> <meta charset="UTF-8"> <meta name= ...
- 一个比较完整的Inno Setup 安装脚本
一个比较完整的Inno Setup 安装脚本,增加了对ini文件设置的功能,一个安装包常用的功能都具备了. [Setup] ; 注: AppId的值为单独标识该应用程序. ; 不要为其他安装程序使用相 ...